SRA OSS LLC
OSS事業本部 技術開発室 主任研究員
長田 悠吾

2023/5/28〜31 にかけて、カナダのバンクーバーで開催された PGConf.dev 2024 に参加しましたので報告いたします。
PGConf.dev の正式名称は PostgreSQL Development Conference で、PostgreSQL のユーザや開発者、コミュニティ関係者が集まる、PostgreSQL の開発とコミュニティの発展に焦点を当てたイベントです。これまでは、年に一度のカンファレンスとして PGCon が同じくカナダのオタワで開催されていましたが、昨年の PGCon 2023 が最後となり、PGConf.dev はその後継イベントにあたります。つまり、今回は PGConf.dev の記念すべき初めての開催となります。 SRA OSS LLC はブロンズスポンサーとして、このカンファレンスの支援をさせていただきました。
今回の会場となったのは、バンクーバーのランドマークであるハーバーセンターの麓にあるサイモン・フレイザー大学(SFU)のバンクーバー・キャンパスです。全4日間の日程のうち、初日には PostgreSQL コミュニティの運営などが議論される “PostgreSQL Developer & Leadership Meeting”(招待制)や、拡張モジュールについての議論をアンカンファレンス形式で行う Extension Ecosystem Summit などが行われました。カンファレンスが本格的に始まるのは2日目からで、朝のオープニングセッションに続いて、様々な講演発表が2日間に渡って3トラック並行で行われました。最終日にはアンカンファレンスが行われた後に、クロージングとなりました。本レポートでは、これらの発表の中からいくつかピックアップして紹介します。
なお、以降では PostgreSQL 17 の新機能や改善について言及している箇所がありますが、それらは全て執筆時にリリース済の PostgreSQL 17 beta1 を元にしています。PostgreSQL 17 の正式リリースは 2024 年の秋頃を予定しており、それまでに状況が変わっている可能性もあることにご注意ください。
Microsoft の Thomas Munro の講演 “Streaming I/O and vectored I/O” では、PostgreSQL がディスク上のテーブルデータにアクセスする際に、複数のブロックを同時に、さらに最終的には事前にバックグラウンドで読み書きすることを可能にする「ストリーミング I/O」の試みについて解説されました。
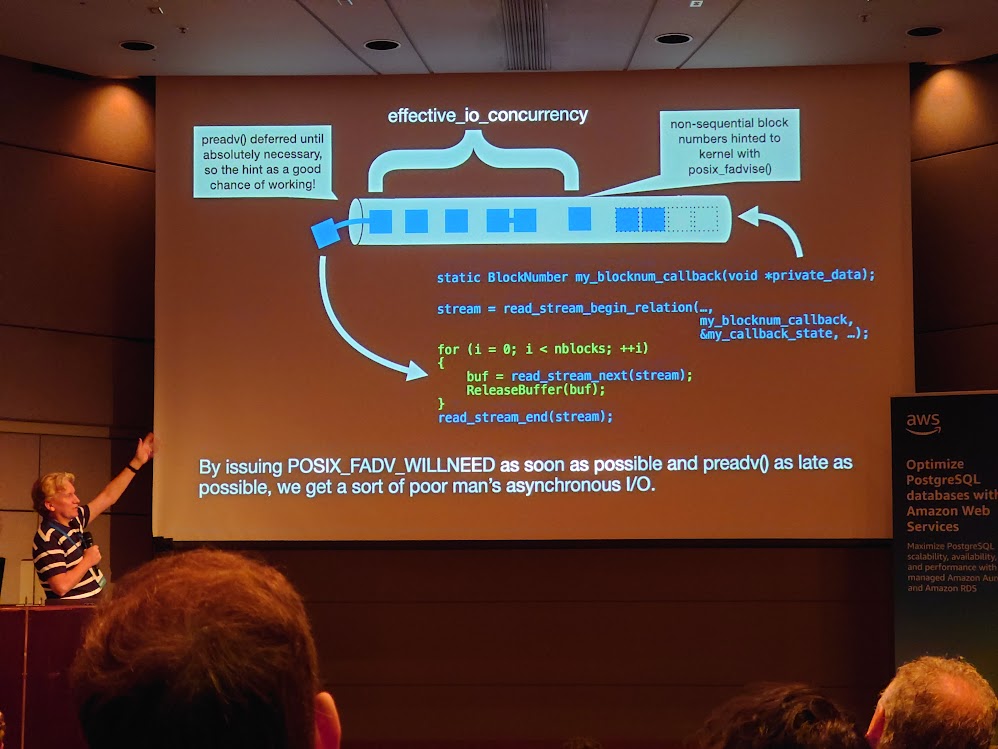
従来の PostgreSQL ではテーブルをディスクから読む際に、サイズが 8kB のブロック1つ毎に、 OS に読み込み要求を発行しています。これに対し、vectored I/O(scatter/gather I/O とも呼ばれます)という方法を使うことで、OS に1つの要求を発行するだけで複数ブロックの同時読み込みができるようになります。
この複数ブロックの同時読み込みは PostgreSQL 17 の改善として取り込まれており、後に必要となるブロックの番号をコールバック関数を介して伝えることで、事前に読み込んだブロックを1つずつ返すインタフェース(streaming API)として実装されています。先読みの程度と方法についてはデータのアクセスパターン(シーケンシャルか、ランダムアクセスか)によって適応的に調整されるようになっています。PostgreSQL 17 では実際にこの API を利用してテーブルのシーケンシャルスキャン、 ANALYZE 処理、pg_prewarm が改善されています。一方で、今回実装された streaming API は、将来 PostgreSQL に非同期 I/O(asynchronous I/O)を実装するための布石でもあります。本当の非同期 I/O は PostgreSQL 17 にはまだ実装されませんが、そのための準備は少しずつ進んでいるようです。
Fujitsu の Amit Kapila による “PostgreSQL 17 and beyond” は、次期 PostgreSQL の新機能や改善をわかりやすく解説する、もやは定番となったシリーズの講演です。PostgreSQL 17 の特徴を、Storage, Logical Replication, SQL, Security, JSON, Monitoring のセクションに分けて紹介していました。新機能の中でも目立つのは、増分バックアップ(incremental backup)のサポートや、ロジカルレプリケーションのレプリケーションスロットのフェイオーバ機能や pg_upgrade 対応、VACUUM の改善でしょうか。パーティションテーブルでパーティションの SPLIT(分割)と MERGE(併合) が可能になったことや、SQL/JSON 標準である JSON_TABLE のサポートも目新しいかもしれません。
最後に PostgreSQL 18 以降に向けて議論されている機能を紹介するのもいつもの流れです。今回は、透過的カラム暗号化、非同期 I/O に向けた取り組み、統計情報のインポート・エクスポート、ロジカルレプリケーションのDDL やシーケンス対応などが挙げられていました。その中には、弊社顧問の石井が取り組んでいる「行パターン認識(Row Pattern Recognition: RPR)」についても言及がありました。こちらについては、今回の PGConf.dev でも発表がありましたので、後ほどご紹介いたします。
AWS の Masahiko Sawada による “PostgreSQL meets ART – Using Adaptive Radix Tree to speed up vacuuming” は、PostgreSQL 17 で改善された VACUUM の性能についての講演です。Adaptive Radix Tree (ART)はその改善のために PostgreSQL に実装された新しいデータ構造です。講演では Adaptive Radix Tree の概要の説明に続いて、それがどのように VACUUM の改善に使われているのか解説されました。
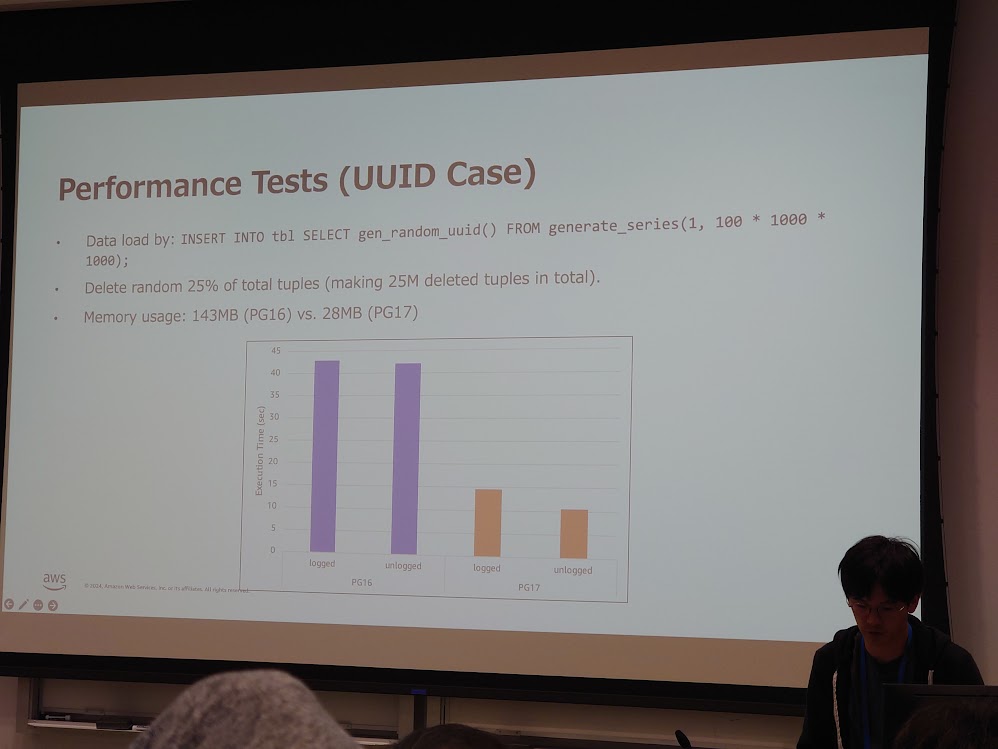
VACUUM はテーブルの中に発生した不要タプル領域を回収して再利用できるようにする処理ですが、その際には、まずテーブルをスキャンして不要タプルのタプルID (TID) をリストアップします。その後に、リストに含まれる TID に対応するインデックスエントリとテーブルタプルの回収が行われます。従来の PostgreSQL では、TID のリストは配列に格納されていました。しかし、この配列を用いた方法には、大きなメモリを事前に確保する必要がある、メモリ使用効率が悪い、使えるメモリ上限に 1GB の制限がある、TIDの検索に時間がかかる、といった問題がありました。そこで、従来の配列に替わる新しいデータ構造を検討した結果、採用されたのが Adaptive Radix Tree です。これにより、大きなメモリの事前確保は不要となり、メモリ使用効率も良くなり、1GBという上限もなくなり、さらに TIDの検索が高速化されました。発表の中の性能評価の結果では、PostgreSQL 16 と 17 で VACUUM 実行結果を比較した結果、実際にメモリ使用量と実行時間が大きく削減できていることが示されました。一方で VACUUM は多くのユーザが必然的に使用する重要な機能のため、beta 版のうちに何か問題がないか是非テストをして欲しい、という聴衆へのメッセージで講演は締めくくられていました。
EDB の Dilip Kumar による講演 “Problem in PostgreSQL SLRU – And how we are optimizing it” は、PostgreSQL の SLRU と呼ばれるメモリ管理システムの問題点とその改善について解説するものでした。

PostgreSQL はトランザクションに関する様々なデータをディスク上に持っています。代表的なものは WAL ですが、それ以外にもトランザクションのコミット状態(CLOG と呼ばれるもので、pg_xact ディレクトリに格納されている)や、サブトランザクションの状態(pg_subtrans)、共有行ロック取得時に使用されるマルチトランザクション状態(pg_multixact)などがあります。これらの情報は頻繁にアクセスされるため共有メモリ上にキャッシュされているのですが、そのキャッシュを管理しているのが SLRU (Simple Least Recently Used) です。
従来の PostgreSQL では SLRU へのアクセスが集中するような状況で劇的な性能劣化が観測されることがありました。例えば大量のサブトランザクションが発生する場合(多量の SAVEPOINT や PL/pgPSQL の EXCEPTION の使用)や、多量の共有行ロックが発生するような状況です。この発表では、そのような状態を意図的に作り出すことで実際に性能劣化をおこることを紹介していました。問題の原因としては、SLRU キャッシュのサイズが小さく頻繁にバッファ置き換えが発生していること、ロック競合が起きていること、CPU キャッシュミスが頻繁に発生していることの3つが挙げられています。
PostgreSQL 17 では SLRU の改善がいくつか行われています。まず、設定により各 SLRU キャッシュのサイズを変更できるようになったこと。次に SLRU キャッシュの内部を複数の “bank” に分割することで情報検索が早くなったこと、そして、ロックを bank 単位に分割することで競合を減らしたことです。発表によると、これらの改善によって SLRU への負荷が高い状況で2〜3倍の性能向上が見られたとのことでした。
これまでは主に PostgreSQL 17 に入る予定の機能や改善に関する発表を紹介してきました。その以外にも、将来の PostgreSQL に向けた提案に関する発表もいくつかありました。その内の1つが、SRA OSS の顧問である石井達夫(Tatsuo Ishii)による行パターン認識の実装について講演 “Implementing Row Pattern Recognition” です。

「行パターン認識(Row Pattern Recognition: RPR)」とは、SQL 標準(SQL:2016)で定義されている機能の一つで、SELECT 文で時系列データなどの行の並びに関する「パターン」を指定して検索ができるものです。例えば、株価の時系列データの中から「株価が上昇してから下降する」といったパターンが現れる箇所を検索することができます。
SQL 標準には2種類の行パターン認識の文法があります。1つは FROM の後ろに MATCH_RECOGNIZE 句を書いてその中で行パターン認識を定義するもので、もう1つは WINDOW 句の中に行パターン認識の定義を書くものです。今回の提案では実装のしやすさから後者の文法が選ばれました。また、行パターンの指定には正規表現を用いるのですが、現状対応している正規表現も今はシンプルなもののみとなっています。
この機能を実装したパッチは PostgreSQL 18 向けに提案されており、開発コミュニティのメーリングリストで議論が進行中です。今のパッチには新しい機能を加える予定はなく、メモリ消費を抑えるなどの改善に留めておき、それがコミットされた後に機能の追加や対応する正規表現の拡充などを予定している、とのことです。また、聴衆の中にメーリングリストでの行パターン認識の議論に参加していた人がいたらしく、発表終了後に話が盛り上がっている様子でした。
PostgreSQL の特徴の1つは拡張性の高さと言われており、PostgreSQL に機能を付与する拡張モジュールが数多く開発されています。今回の PGConf.dev 2024 でも、拡張機能に関する講演や議論が多くありました。初日に行われた Extension Ecosystem Summit や、最終日のアンカンファレンスにおいても、PostgreSQL 本体が提供するインターフェース(ABI/API)、パッケージング、拡張モジュール管理方法、など様々な議論がされていたのに加え、拡張モジュールを取り巻く状況の改善に関する発表が複数ありました。
その1つが、TileDB の Abigale Kim による “Anarchy in the Database: A Survey and Evaluation of Database Management System Extensibility” です。PostgreSQL を含むいくつかの DBMS の拡張機能を調査したというこの講演によると、PostgreSQL は他の DBMS に比べて柔軟性の高い拡張機能を持ち、また実際に拡張モジュールの数も桁違いに多いようです。一方で、複数の拡張モジュールを組み合わせると動かなくなる、といったような現象もよく見られます。講演の中で紹介された例は、分散データベース機能を提供する著名な拡張モジュールである citus と、PostgreSQL に同梱されている auto_explain を同時に使うとエラーが発生する、といったものでした。
調査のため、メジャーな拡張モジュールを 114 個選択し、その組み合わせを試してみたところ、その内 17% の組み合わせで問題が発生したとのことでした。解析の結果、そのような問題の発生と相関が高かった要因としては、「複数のPostgreSQLバージョンに対応するようなロジック」「ユーティリティコマンドに対するフック (ProcessUtility_hook) の使用」などが見つかったそうです。
このような PostgreSQL の柔軟な拡張性と安全性や保守性の懸念の関係を、発表者は「諸刃の剣(a double edged sword)」と表現していました。発表の最後ではこの問題への対処として、拡張モジュール管理の仕組みを作ることや、拡張モジュール間の互換性をチェックするツールを作ることなどが示唆されていました。
PostgreSQL の拡張モジュールを紹介する発表もいくつかあり、そのうちの1つが AWS の Jonathan Katz による “Vectors: how to better support a nasty data type in PostgreSQL” です。これは、ベクトルデータの類似性検索機能を提供する拡張モジュール pgvector と、その課題についての講演です。生成AIの話題が尽きない昨今、pgvecto は最も人気にある PostgreSQL の拡張モジュールの1つと言えるでしょう。
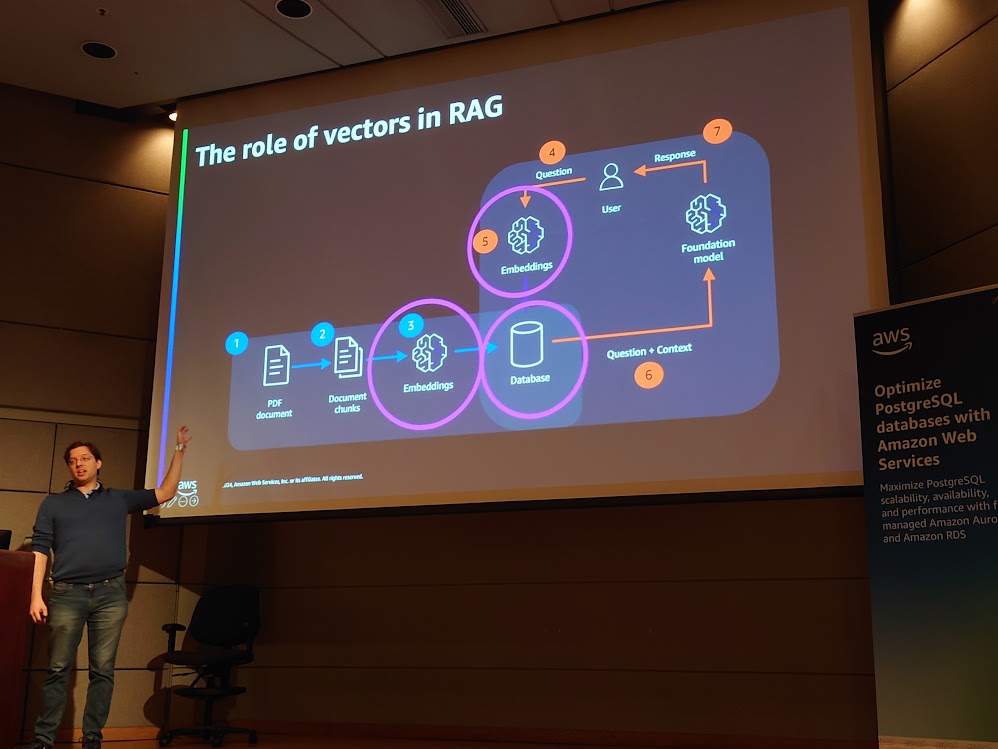
この発表では導入として、生成AIを用いた Retrieval Augmented Generation (RAG) におけるベクトルデータの果たす役割について解説されました。RAG とは何かをごく簡単に言えば、ユーザからの質問をそのまま生成AIに送るのではなく、ユーザの質問に関連する情報をデータベースから検索し、その情報を「文脈」として与えることで、生成AIからより適切な回答を得ようとする方法のことです。この時「ユーザの質問に関連する情報の検索」のときに行われるのがベクトルデータの類似性検索です。データベース内の情報は予めベクトルデータに変換(embedding) しておきます。ユーザの質問もベクトルデータに変換した上で、その質問と最も「近い」情報を「ベクトルデータの類似性」に基づいて検索するわけです。
発表では pgvector の概要、サポートしているインデックス(IVFFlat, HNSW)、過去一年の pgvector の性能向上についての説明がされた後、最後は pgvector の課題についての話題となりました。そのうちの1つが高次元ベクトルのデータサイズです。たとえば、3072 次元のベクトルの場合、そのサイズは 12kB にもなる(1次元が 4 byte の場合)のですが、このサイズは PostgreSQL の標準のブロックサイズである 8kB を超えています。実際には TOAST という技術により、テーブルにはこのサイズのデータを格納することはできるのですが、インデックスには TOAST が適用されないため、そのような高次元ベクトルではインデックスを生成できません。この問題に対して PostgreSQL 側で可能な対策としては、TOAST をインデックスに適用できるよう改良したり、インデックスのページサイズを 8kB 以上に変更できるようにする、といった案が示唆されていました。その他にも、pgvector でパラレルクエリがサポートされていなかったり、類似性検索実行時には外部サーバでの非同期実行が動作しないなどの課題が挙げられていました。

Postgres Professional の Alena Rybakina による講演 “Adaptive query optimization in PostgreSQL” においても興味深い拡張モジュールが紹介されていました。
PostgreSQL はカラム値の分布などの統計情報を元にして適切なクエリ実行計画を選択します。その時に行われるのは、結果行数(cardinality) の推定ですが、クエリが複雑だったり、カラム値の分布に偏りや相関がある場合には正確な推定ができず、あまり適切ではない実行計画が選ばれることがあります。これを是正するため、PostgreSQL には拡張統計情報という機能がありますが、これを適切に設定するのはそう簡単ではありません。
この講演で紹介している Adaptive Query Optimizer(AQO, 適応的クエリ最適化)は、繰り返し実行されるクエリの統計情報を記憶・学習することで適切な実行計画の生成を助ける拡張モジュールです。具体的には k-近傍法を用いて、クエリに含まれる条件の選択率に基づいて、実行結果として出力される行数を推定しているようです。Join Onder Bechmark というベンチマークでテストしたところ、ほとんどのクエリで行数推定の誤りが改善され、実行時間が短縮されていることが示されていました。現状の課題として、一時テーブルを含むクエリやスタンバイサーバでの動作には対応していないらしく、これらは将来の計画として挙げられていました。

ここまで PostgreSQL の技術的な発表についていくつか紹介してきましたが、今回の PGConf.dev 2024 ではより良いコミュニティのあり方についてのセッションもありました。4人のコミッタ Amit Langote, Masahiko Sawada, Melanie Plageman, Robert Haas による “Making PostgreSQL Hacking More Inclusive” では、PostgreSQL 開発コミュニティをより良くしてくために、様々な背景を持つ発表者の経験や考えを共有するというものでした。発表者の2人が日本からの参加であることもあり、英語話者でない人にとっての議論の難しさなど共感できる内容が多かったです。曖昧な言葉ではなく直接的に伝えるのが重要であるという考えは複数の発表者で共有されているようでした。
最後に、最終日に行われたアンカンファレンスの様子についてご紹介します。
アンカンファレンスとは、講演者や話す内容があらかじめ決まっているのではなく、参加者がその当日にその場で話題を提案して議論する形式のイベントです。議論したいことがある人はその場でテーマを大きなポストイットに書き込み、簡単に口頭で説明します。その後、関連するテーマは統合されたりしながら、最終的に議論されるテーマは会場にいる参加者の多数決により選ばれ、3つのトラックに振り分けられます。今回は PostgreSQL のマルチスレッド化、可観測性、新しいテストの枠組み、コミュニティの参加者を増やすには、通信プロトコルの強化など、全部で12のテーマが選ばれました。

PostgreSQL のマルチスレッド化については、2日目に Neon の Heikki Linnakangas による発表Multi-threaded PostgreSQL?でも提案があったのですが、アンカンファレンスでは、Robert Haas, Heikki Linnakangas, Thomas Munro といった強力な開発者たちが中心となって、グローバル変数、拡張モジュールの扱い、プロセスIDからスレッドIDへの書き換え、シグナルハンドラのリファクタリングといった、より具体的な課題解決について議論されていたようでした。誰がどこを担当するかといった話まで登場し、PostgreSQL のマルチスレッド化の計画が現実味を帯びて進みだしているように感じられました。
他に、可観測性に関するセッションは、自律運転(self-driving)、promethus exporter、VACUUM 統計情報といったテーマが合併されたもので、様々な興味から収集したい情報や、その集約の方法、たとえば拡張モジュールがよいのか本体の機能がよいのか、などについて議論されていたようでした。
また、新しいテストフレームワークを議論するセッションでは、現在の Perl を使ったテスト方法の問題点があげられ、Python の pytest を導入する提案などが議論されていました。

今回の PGConf.dev も、興味深い発表を沢山聞くことができ大変刺激的でした。セッションでもホールでも議論が大いに盛り上がっていました。今回行われた全ての議論から、PostgreSQL の本体ははもちろん、拡張モジュールやテスト、コミュニティのあり方まで、PostgreSQL に関わるあらゆることをより良くしていこうという活気と熱意を感じることができました。
来年の PGConf.dev もカナダのどこかの都市、予定ではバンクーバー、トロント、オタワ、モントリオールのどこかで開催される予定だそうです。また是非参加できたらと思います。

03-5979-2701 |