システムを安定して稼働させるためには、冗長化構成が不可欠です。冗長化構成を採用することで、稼働系サーバに障害が発生してサービスが停止した場合でも、待機系サーバへ自動的に切り替えることができ、ダウンタイムを最小限に抑えられます。
一方で、冗長化によって単一障害点は解消できるものの、クラスタノード間の通信が途絶えた場合には「スプリットブレイン」状態に陥るリスクが残ります。スプリットブレインが発生すると、複数のノードが同時に稼働系として振る舞い、IP アドレスの競合やファイルシステムの二重マウントなどが発生する可能性があります。最悪の場合、データ破損といった深刻な障害につながる恐れもあります。
そのため、クラスタ構成を安定して運用するうえで、スプリットブレイン対策は欠かせないポイントです。
本記事では、Pacemaker/Corosync クラスタで広く利用されているスプリットブレイン対策の仕組みについて解説します。
スプリットブレインとは
スプリットブレインとは、クラスタを構成するノード間の通信が途絶えた際に、各ノードが互いの状態を正しく認識できなくなり、複数のノードが同時に稼働系として動作してしまう状態を指します。
通常、クラスタではノード同士が定期的にハートビート通信を行い、相互監視を行っています。しかし、ネットワーク障害などにより通信が分断されると、各ノードは相手を「障害」と誤認する可能性があります。この状態では、同一サービスやリソースが複数ノードで同時に起動されるため、IP アドレスの競合、ファイルシステムの二重マウント、共有データへの同時書き込み、などが発生する可能性があります。
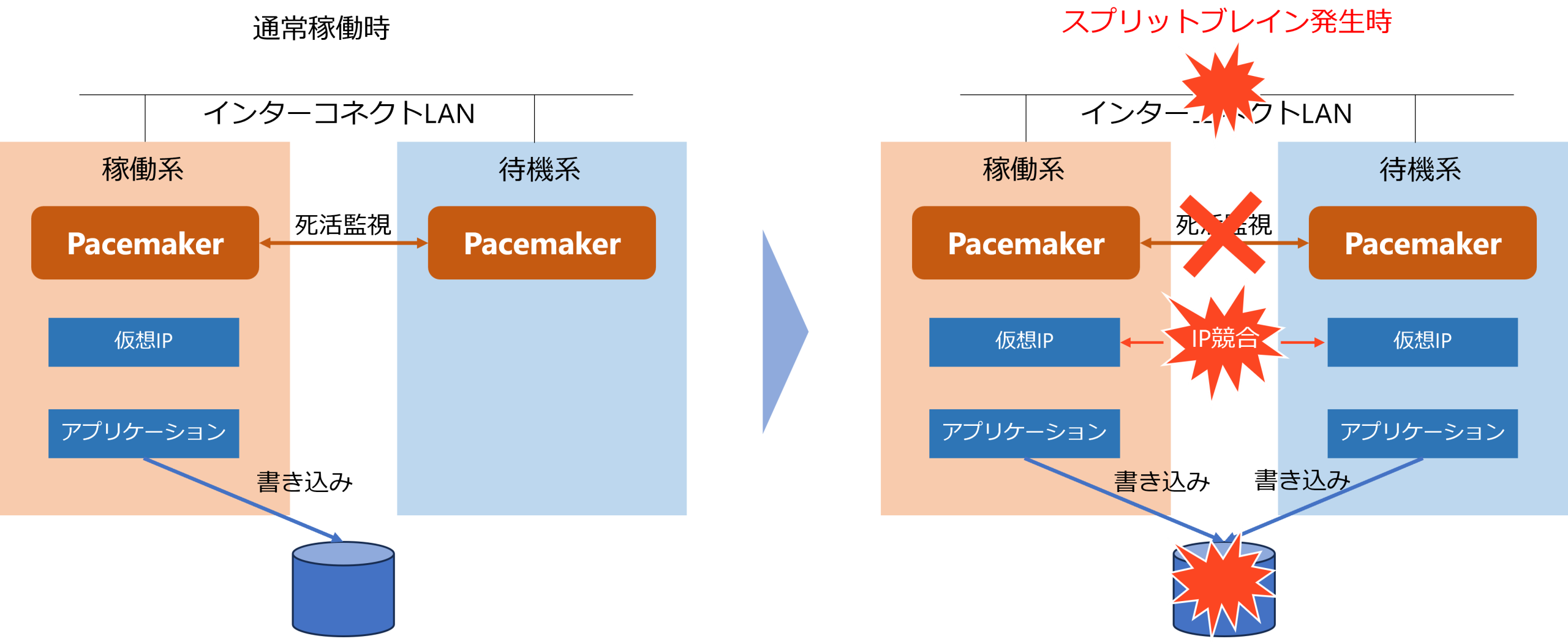
スプリットブレイン対策
Pacemaker/Corosync クラスタでは、スプリットブレインを防止するために複数の仕組みが用意されています。
Stonith によるフェンシング
STONITH (Shoot The Other Node In The Head) は、クラスタ環境で発生し得るスプリットブレインを防止するためのフェンシング手法です。ノード間の通信が途絶えた場合に、インターコネクト (クラスタ通信用ネットワーク) とは独立した経路を用いて問題のあるノードを強制的に停止または再起動させることで、データ破壊やサービスの二重起動を防ぎます。具体的には、IPMI などのハードウェア制御ボードや、共有ストレージを介した制御を利用して、異常が発生したノードを停止/再起動させます。
具体的には、以下のような仕組みが利用されます。
-
- IPMI などのハードウェア制御ボード
- 仮想化基盤の API
- 共有ストレージを利用した制御 (SBD など)
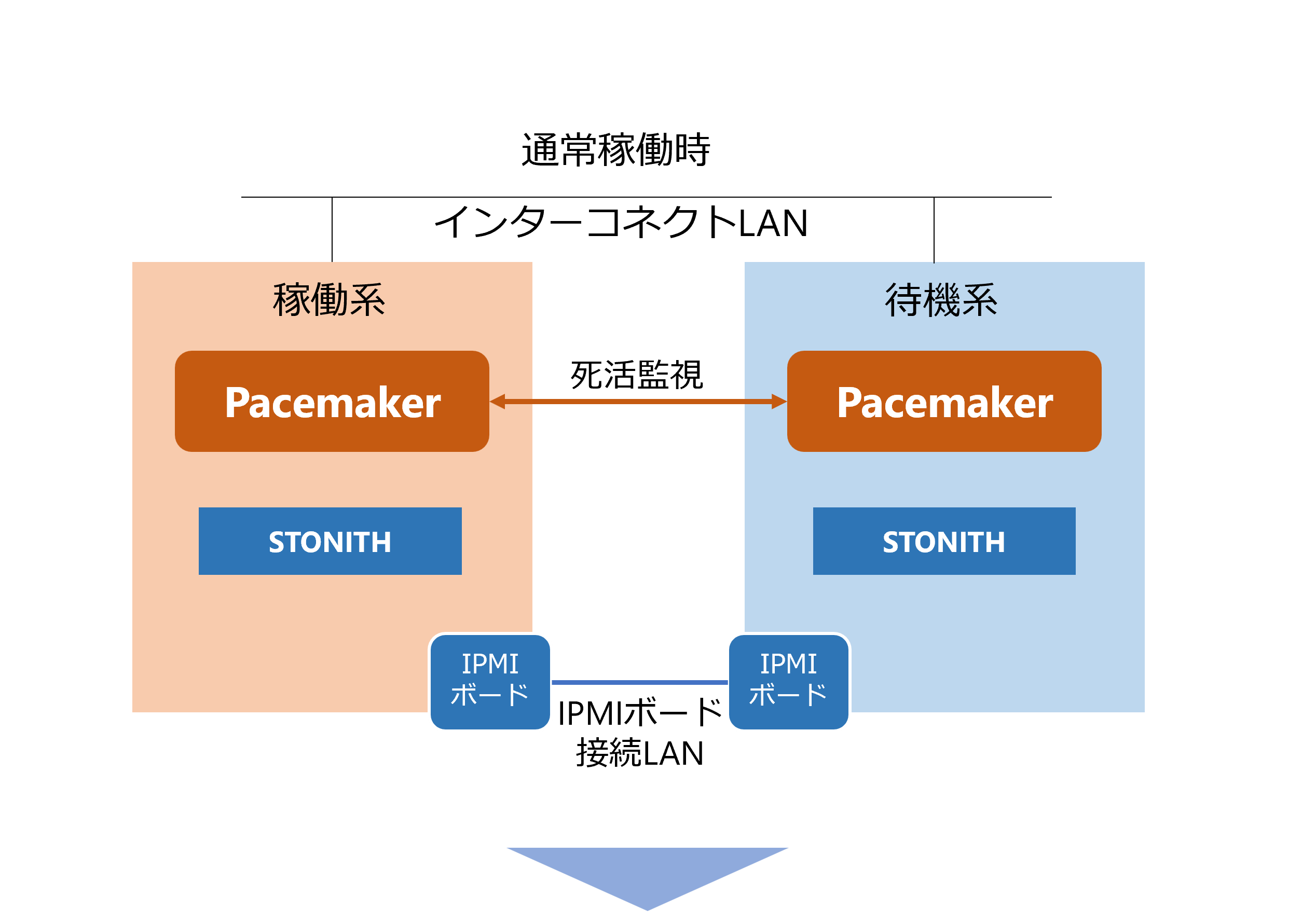
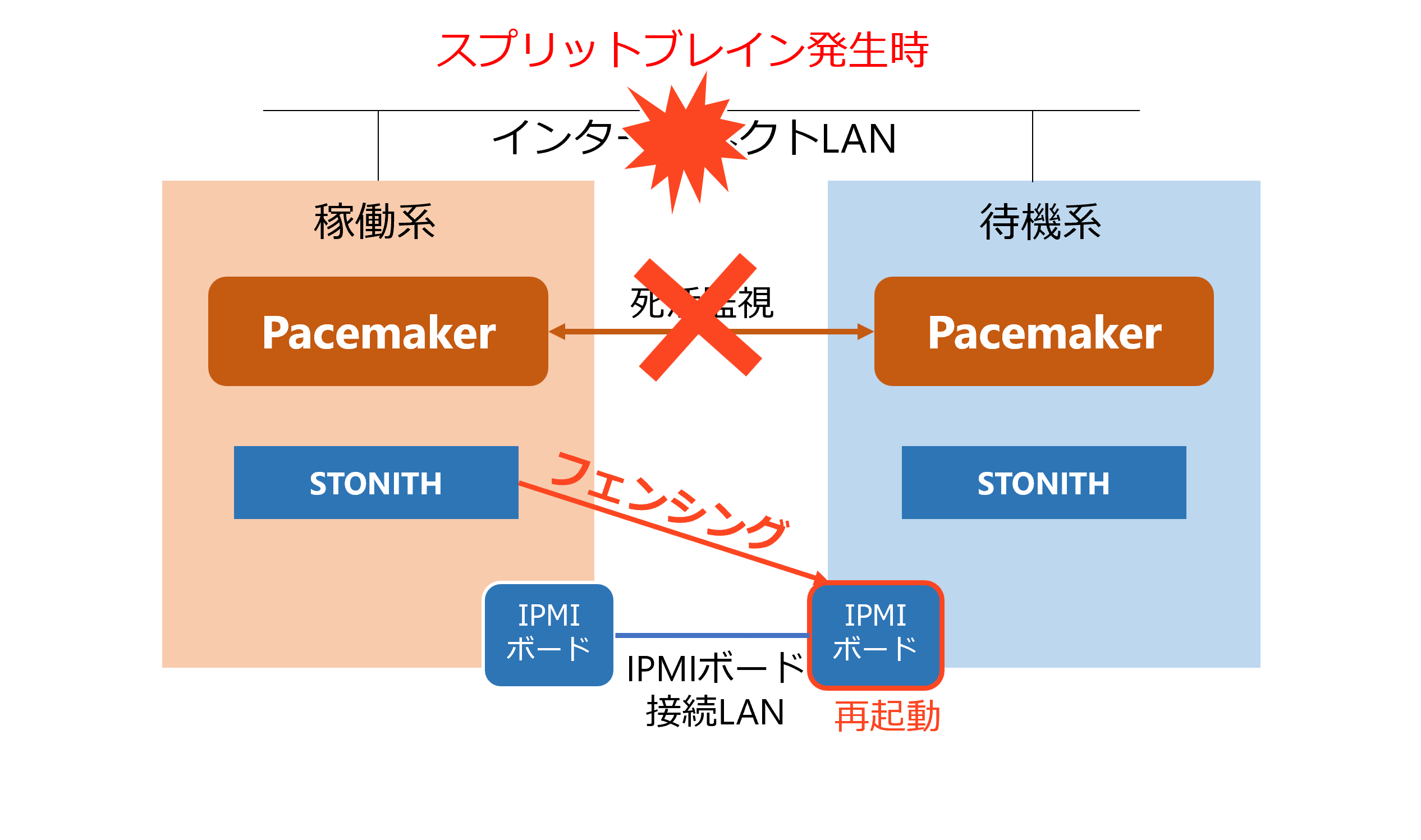
Pacemaker/Corosync を利用した HA クラスタにおいて、STONITH は最も確実で推奨されるスプリットブレイン対策です。
リソースの排他制御
リソースの排他制御により、複数ノードでの同時起動を防止する方法もあります。sfex や VIPCheck は、排他制御を実現するリソースエージェントです。
sfex は共有ディスクを使った排他制御を実現するリソースエージェントとなります。稼働系ノードが共有ディスク上に定期的に書き込みを行うことで排他状態を維持し、ノード間通信が途絶えた場合に、両系が同時に稼働系となることを防止します。
VIPCheck は仮想 IP 状態をチェックすることで排他制御を実現します。共有ディスクが利用できない環境でも、リソースの二重起動を抑止できます。
なお、sfex および VIPCheck は Linux-HA Japan が提供するリソースエージェントであり、RHEL HA Add-on の標準パッケージには含まれていません。
クォーラムによる多数決制御
クォーラムとは、クラスタ処理を継続するために必要な最低限の投票数のことを指します。スプリットブレイン対策として広く使われている一般的な手法です。
一般的に、3台以上のノードでクラスタを構成し、過半数を獲得したパーティションのみがクラスタを継続できる仕組みです。過半数を満たさない場合はクォーラムを喪失し、
no-quorum-policyの設定に従ってリソース停止やフェンシングが実行されます。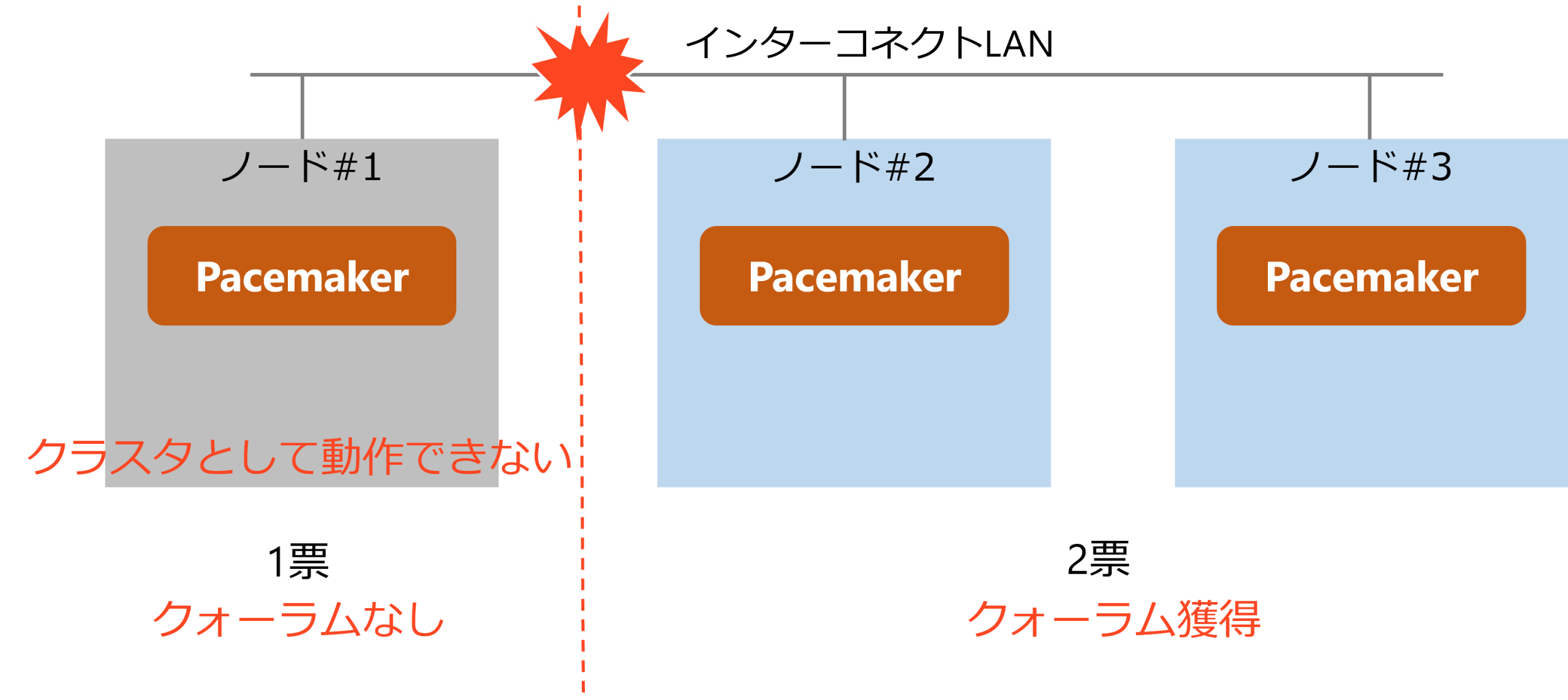
Pacemaker における
no-quorum-policyの各設定値の動作は以下の通りです。- stop (デフォルト)
クォーラムを喪失したノード上のすべてのリソースを停止します。 - freeze
現在動作しているリソースはそのまま維持しますが、新規起動や再配置は行いません。 - ignore
クォーラム喪失を無視し、通常どおりリソース管理を継続します。 - demote
Master/Slave (Promotable) リソースが存在する場合、Master を Slave に降格します。 - suicide
クォーラムを喪失したノードをフェンシングします。
クォーラムデバイス
クォーラムデバイスは、ノード間通信が切断された際に、どのノード (またはパーティション) がクラスタの運用を継続すべきかを判断するための外部投票ノードです。特に偶数ノードで構成されたクラスタでは、ネットワーク分断時に投票数が同数となり、クォーラム (過半数) が成立しないという問題があります。なかでも2ノードクラスタでは、インターコネクトが切断されると双方が相手を障害と誤認し、スプリットブレイン状態に陥るリスクが高まります。
このような構成では、クラスタノードとは別に調停役となるクォーラムデバイスを追加することで、クラスタ全体の投票数が奇数となり、過半数による多数決が成立します。その結果、スプリットブレイン発生時でも、どちらのノードがクラスタを継続すべきかを適切に判断できるようになります。
2ノードクラスタの場合、通常は各ノードが1票ずつを持ちますが、クォーラムデバイスを追加すると合計3票となります。ネットワーク分断が発生した際には、クォーラムデバイスの投票を含めた多数決により、過半数を得たノードのみがクラスタ管理を継続できます。これにより、両ノードが同時にリソースを稼働させる事態を防止できます。
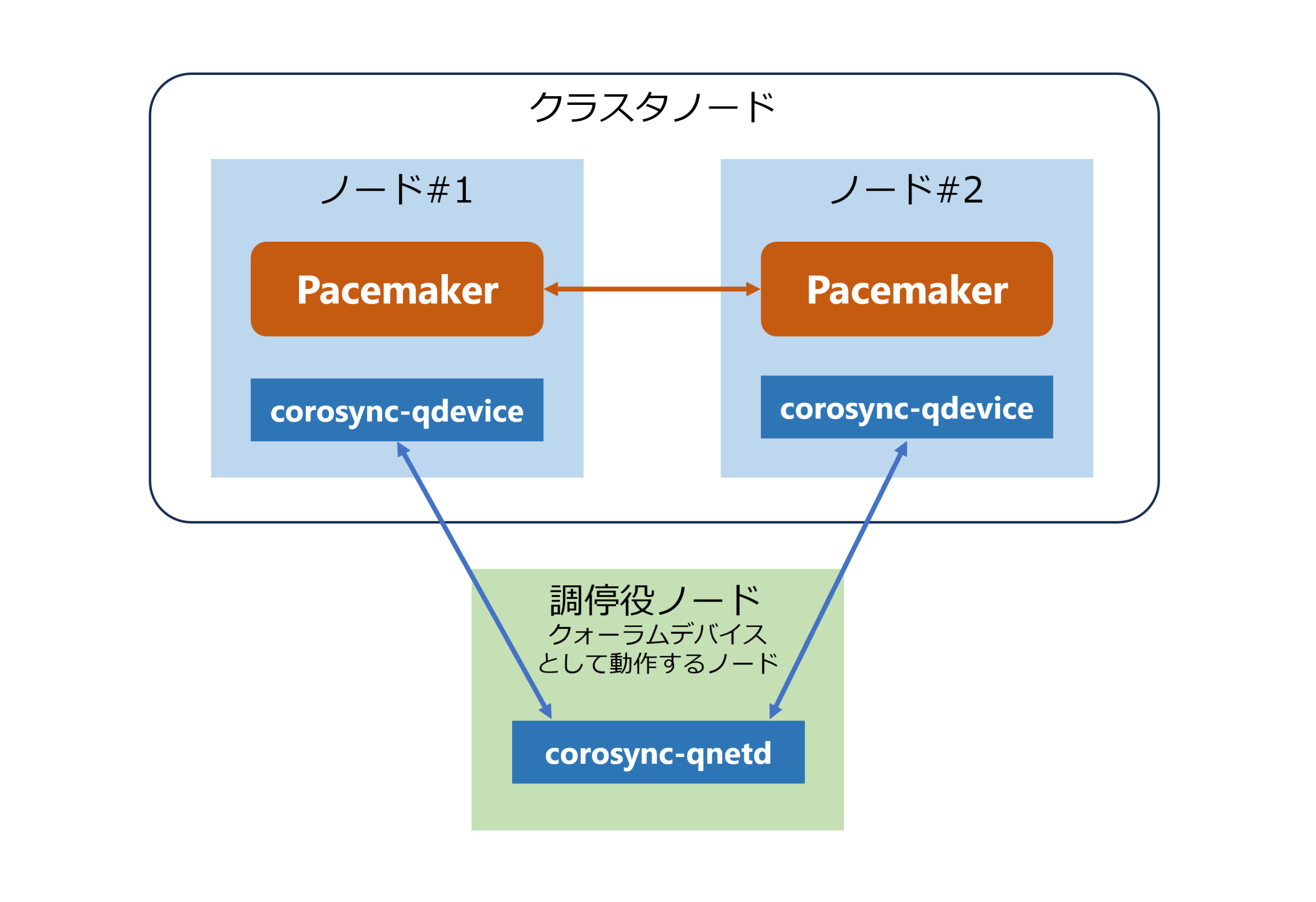
クォーラムデバイスを利用する場合、クラスタノードには corosync-qdevice をインストールし、調停役となるサーバには corosync-qnetd をインストールします。corosync-qnetd デーモンはクラスタ外部で動作し、投票を行います。分断時には corosync-qnetd の判定結果に基づき、過半数を得たノードのみがクラスタを維持し、過半数を得られなかったノードはクラスタサービスを停止します。
偶数ノード構成、特に2ノードクラスタではスプリットブレインのリスクが高いため、クォーラムデバイスの利用が推奨されます。
クォーラムデバイスの具体的な設定方法や、ネットワーク分断時の挙動を含む詳細な動作確認については、こちらの記事にて詳しく解説していますので、あわせてご参照ください。
おわりに
本記事では、スプリットブレイン対策として広く利用される以下の仕組みについて解説しました。
- STONITH によるフェンシング
- リソースの排他制御
- クォーラムによる多数決制御
- クォーラムデバイス
Pacemaker には多数のフェンスエージェントが用意されており、物理サーバ、仮想化基盤、共有ディスク環境など、それぞれの構成に応じたフェンシング方式を選択できます。HA クラスタにおいては、フェンシングの実装が最も確実なスプリットブレイン対策といえます。
一方で、環境要件や構成上の制約により電源制御を用いたフェンシングを採用しない場合には、クォーラム制御やクォーラムデバイスの利用によって多数決の仕組みを補強する方法があります。特に2ノードクラスタでは、クォーラムデバイスを追加することで投票数を奇数化し、分断時の判断を明確にできます。
HA クラスタでは、冗長化するだけでは不十分で、障害時の挙動まで考えた設計が欠かせません。本記事が、より安全で堅牢なクラスタ構築の参考になれば幸いです。