Pacemakerで構築したクラスタシステムの運用を続けていると、Pacemakerで冗長化しているソフトウェアや、Pacemaker自体を新しいバージョンにアップデートする必要が生じる場合があります。主な理由としては以下が挙げられます。
- 脆弱性の修正
- 重要な不具合の修正
- サポート期間の終了
単体で動作しているソフトウェアの場合は、「サービス停止→パッケージ更新→サービス起動」のように比較的簡単な方法でアップデートが可能ですが、クラスタを組んでいる場合は、事前にいくつかの方法を検討した上で計画的に実施する必要があります。
クラスタ全体を停止してまとめてアップデートする方法
この方法は最も確実ですが、クラスタを停止している間はサービスが利用できません。
ある程度のサービス停止が許容できる場合はこの方法を選択してもよいでしょう。
また、メジャーバージョンアップ等でデータや設定の互換性がなくなる場合もこの方法をとることになります。
ローリングアップデートについて
ローリングアップデートとは、サービスを継続しながら各サーバを順次アップデートしていく方法です。
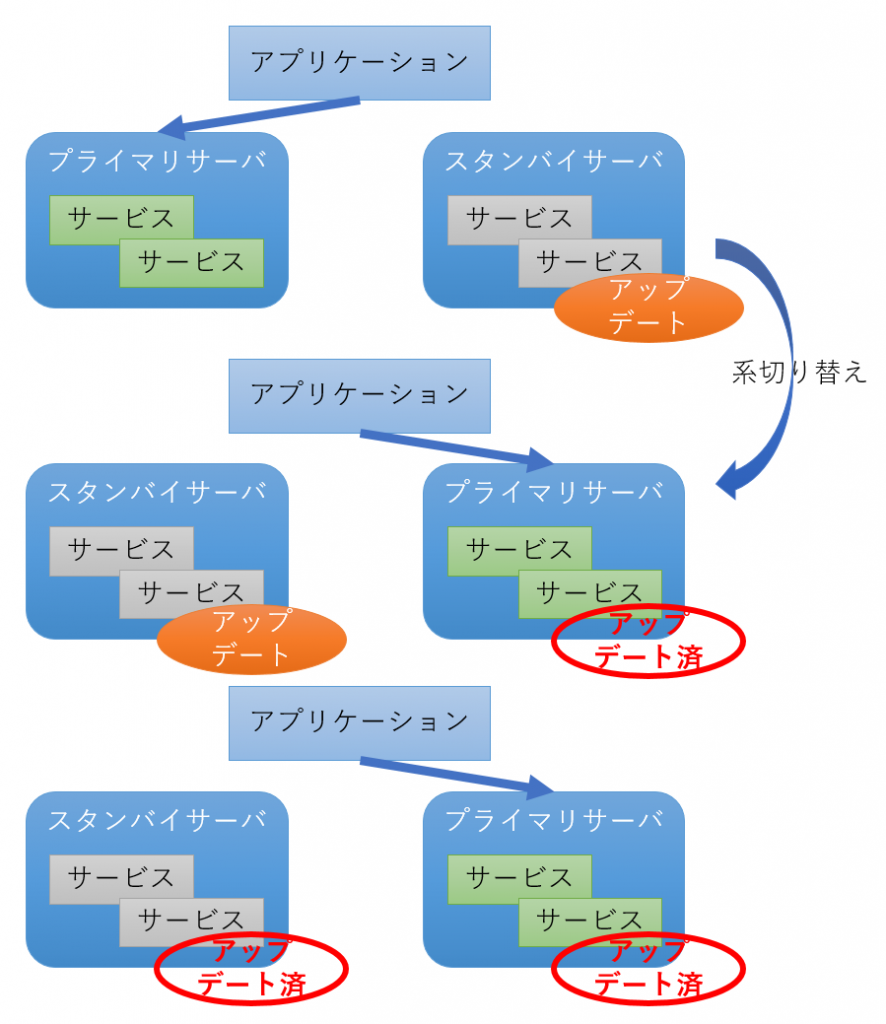
まずスタンバイサーバに対してアップデートを実施し、スタンバイサーバをプライマリサーバに切り替え、旧プライマリサーバ(現スタンバイサーバ)に対してアップデートを実施します。
この方法の場合、アップデート前後でソフトウェアの互換性が保たれていることが前提となります。
メジャーバージョンアップ等でデータや設定に互換性がなくなる場合は、この方法をとることが困難となります。
以下、具体的にローリングアップデートを行う手順をみていきます。
なお、前提とする環境はRHEL7.xおよびLinux-HA Japan提供のPacemaker/Corosyncとなります。
リソースとして管理されているサービスのアップデート
Pacemaker配下のリソースとして管理されているサービス(例: Apache, PostgreSQL)をアップデートする場合は、メンテナンスモードを使用することが一般的です。メンテナンスモードを有効にすると、リソースはunmanaged状態となり、リソースの起動・停止・監視が行われなくなります。
メンテナンスモード状態で各サービスのアップデートを行い、作業が完了したらメンテナンスモードを解除します。
クラスタ全体をメンテナンスモードにする場合
1. クラスタ全体をメンテナンスモードにします。
(crm)# crm configure property maintenance-mode=true (pcs)# pcs property set maintenance-mode=true
crm_mon -rfA1もしくはpcs statusで状態を確認すると、両ノードのリソースは以下のように (unmanaged) と表示されます。
Clone Set: ping-clone [ping] (unmanaged) ping (ocf::pacemaker:ping): Started server2 (unmanaged) ping (ocf::pacemaker:ping): Started server1 (unmanaged)
2. 両ノードで各ソフトウェアのメンテナンスやアップデートなどの作業を行います。このときプライマリ側でサービスを停止してもフェイルオーバーは発生しません。
3. メンテナンスモードを解除します。
(crm)# crm configure property maintenance-mode=false (pcs)# pcs property set maintenance-mode=false
注: メンテナンスモードを解除するとき、各リソースの状態はメンテナンスモードに入る前と同一の状態になっている必要があります。状態が異なる場合は予期せぬフェイルオーバーなどが発生する場合があります。
ノード単位でメンテナンスモードにする場合
1. スタンバイノード(メンテナンス対象ノード)で以下を実行します。デフォルトはコマンドを実行したノードが対象となるため、ノード名は省略できます。
(crm)# crm node maintenance <スタンバイノード名> (pcs)# pcs node maintenance <スタンバイノード名>
crm_mon -rfA1もしくはpcs statusで状態を確認すると、メンテナンスモード中のノードのリソースは以下のように (unmanaged) と表示されます。
Clone Set: ping-clone [ping] ping (ocf::pacemaker:ping): Started server2 (unmanaged) Started: [ server1 ] Node Attributes: * Node server1: + pingd : 100 * Node server2: + maintenance : on + pingd : 100
2. メンテナンス対象ノードで各ソフトウェアのメンテナンスやアップデートなどの作業を行います。
3. メンテナンスモードを解除します。
(crm)# crm node ready <スタンバイノード名> (pcs)# pcs node unmaintenance <スタンバイノード名>
4. リソースをプライマリノードからスタンバイノードへフェイルオーバーします。
以下はプライマリノードを一度standbyモードにしてリソースをフェイルオーバーさせています。
(crm)# crm node standby <プライマリノード名> (crm)# crm node online <プライマリノード名> (pcs)# pcs cluster standby <プライマリノード名> (pcs)# pcs cluster unstandby <プライマリノード名>
5. 現スタンバイ(旧プライマリ)ノードで同様に1.~3.のメンテナンス作業を実施します。
6. 必要に応じてリソースのフェイルバックを行います。
スタンバイモードを利用する場合
メンテナンスモードの代わりにスタンバイモードを使用し、ノードのリソースを停止させた状態でアップデートを実施してもよいです。サービスの起動を Pacemaker に任せるため、こちらのほうが比較的確実かもしれません。
1. スタンバイノード(メンテナンス対象ノード)で以下を実行し、スタンバイモードに移行します。
(crm)# crm node standby <スタンバイノード名> (pcs)# pcs cluster standby <スタンバイノード名>
2. メンテナンス対象ノードで各ソフトウェアのメンテナンスやアップデートなどの作業を行います。
3. スタンバイモードを解除します。
(crm)# crm node online <スタンバイノード名> (pcs)# pcs cluster unstandby <スタンバイノード名>
4. プライマリノードで1.を実行し、スタンバイモードに移行します。このときリソースはスタンバイノードへフェイルオーバーします。
5. 現スタンバイ(旧プライマリ)ノードで同様に2.~3.のメンテナンス作業を実施します。
6. 必要に応じてリソースのフェイルバックを行います。
Pacemaker/Corosyncのアップデート
Pacemaker/Corosyncのアップデートを行う場合は、各ノードでPacemaker/Corosyncを一時的に停止する必要があります。
1. スタンバイサーバの Pacemaker を停止します。
# systemctl stop pacemaker
2. スタンバイサーバの Pacemaker/Corosync のアップデートを実施します。
# yum update ...
3. スタンバイサーバの Pacemaker を起動します。
# systemctl start pacemaker
4. クラスタの状態が正常であることを確認したら、リソースをプライマリノードからスタンバイノードへフェイルオーバーします。
以下はプライマリノードを一度standbyモードにしてリソースをフェイルオーバーさせています。
(crm)# crm node standby <プライマリノード名> (crm)# crm node online <プライマリノード名> (pcs)# pcs cluster standby <プライマリノード名> (pcs)# pcs cluster unstandby <プライマリノード名>
5. 現スタンバイ(旧プライマリ)ノードで同様に1.~3.のメンテナンス作業を実施します。
6. 必要に応じてリソースのフェイルバックを行います。