Pacemaker/Corosync は、Linux 環境で高可用性クラスタを構築するためのオープンソースのクラスタリングソフトウェアです。複数ノードにまたがるリソースの起動、停止、監視を自動的に行い、障害発生時にはフェイルオーバーを実施することで、システムの継続稼働を実現します。
内部的には複数のデーモンプロセスがそれぞれ役割を担い、連携しながら動作しています。本記事では、Pacemaker/Corosync のプロセス構成とプロセス間のデータ処理の流れ、さらに状態遷移の仕組みについて解説します。
※バージョンによって挙動が異なる場合があるため、本記事では Pacemaker 2.1 を前提としています。
Pacemaker/Corosync のプロセス構成
Pacemaker の内部では、複数のデーモンプロセスが役割を分担し、クラスタ全体の監視、制御、リソース管理を行います。一方、Corosync はクラスタを構成するノード間の通信や死活監視、クォーラム管理を担当するプロセスです。両者が連携することで、障害が発生した場合でもサービスを継続できる、高可用性クラスタを実現できます。
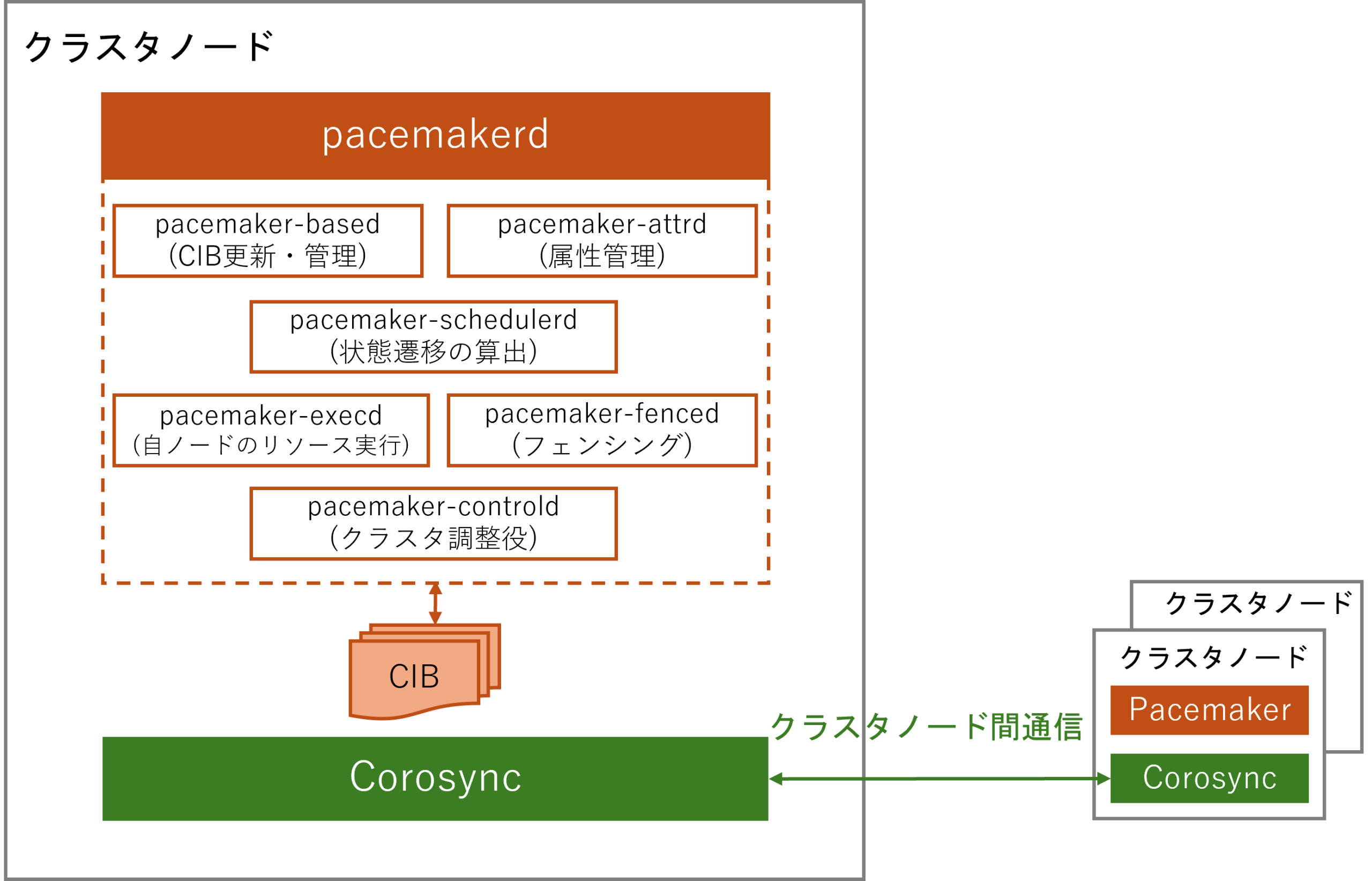
主要なプロセスの役割は以下のとおりです。
pacemakerd
Pacemaker クラスタ全体の管理を担う親デーモンであり、以下の各サブデーモンプロセスの起動・監視を行い、異常時は再起動します。
pacemaker-based
クラスタの設定や状態情報を保持する CIB (Cluster Information Base、詳細は後述) を管理するプロセスです。CIB は XML 形式で構造化されており、クラスタ設定やリソースの構成、ノードの状態などが記録されています。pacemaker-based は CIB の読み書きを行い、常に最新の情報を反映させるとともに、複数ノード間で内容が一致するよう同期処理を行い、クラスタ全体の一貫性を維持します。
pacemaker-attrd
クラスタノードやリソースに関する動的属性情報 (稼働状況、フェイルカウントなど) を管理するプロセスです。pacemaker-attrd は各ノードから収集した属性情報を保持し、必要に応じてクラスタ全体に伝達します。
pacemaker-schedulerd
CIB の情報をもとに、どのノードでどのリソースを動かすかを決定するプロセスです。フェイルオーバー時のリソース配置計画もここで決定されます。
pacemaker-controld
Pacemaker クラスタにおける「調整役」を担うプロセスです。このプロセスは pacemaker-schedulerd が決定した計画に基づき、各ノード上の pacemaker-execd に対してリソースの起動、停止、監視を指示します。
pacemaker-execd
ローカルノード上でリソースエージェントの起動、停止、監視を実行するプロセスです。操作結果は pacemaker-controld に報告され、クラスタ全体の判断材料として利用されます。
pacemaker-fenced
障害を起こしたノードを強制的にリブートまたはシャットダウンするフェンシングを担当するプロセスです。データ破壊や二重書き込みなどの重大な障害を防ぐため、STONITH デバイスを操作して信頼できないノードをクラスタから隔離します。
なお、Pacemaker 2.0 系ではプロセス名が変更されました。ただし、機能自体は従来と同じです。旧プロセス名との対応関係を以下の表に示します。
| 旧プロセス名 | 新プロセス名 |
|---|---|
| cib | pacemaker-based |
| attrd | pacemaker-attrd |
| pengine | pacemaker-schedulerd |
| crmd | pacemaker-controld |
| lrmd | pacemaker-execd |
| stonithd | pacemaker-fenced |
CIB (Cluster Information Base) とは
Pacemaker では、各プロセスが CIB を中心に情報を共有・同期することで、クラスタ全体の一貫性を保っています。
CIB は XML 形式で管理されるクラスタ情報のデータベースであり、クラスタの構成や各リソースの状態を記録します。CIB には、クラスタの状態変化に応じてリアルタイムで更新される動的な情報が保持されており、クラスタ全体の整合性を維持するうえで重要な役割を担っています。各ノード上の pacemaker-based プロセスが CIB を管理し、更新や同期を行うことで、pacemaker-schedulerd は常に最新の情報に基づいてリソースの配置やフェイルオーバーの判断を行うことができます。
CIB の構造は主に以下のセクションで構成されています。
<cib crm_feature_set="3.19.6" ...>
<configuration>
<!-- クラスタ設定(リソース定義、制約、ノード設定など) -->
</configuration>
<status>
<!-- 実行中のリソースの状態やノードの状態 -->
</status>
</cib>
プロセス間データ処理の流れと状態遷移の仕組み
Pacemaker では、複数のサブデーモンが連携してクラスタを制御します。その中心的役割を担う pacemaker-controld は、クラスタの「頭脳」として動作し、ノードの参加・離脱、リソースの起動・停止、フェイルオーバーなど、クラスタ内で発生する各種イベントに応じて内部状態を遷移させつつ、クラスタ全体を制御します。
代表的な状態は次のとおりです。
| 状態 | 説明 |
|---|---|
| S_STARTING | 初期化中 |
| S_PENDING | クラスタ構成情報や他ノードの参加を待機中 |
| S_ELECTION | DC を決定するための選挙中 |
| S_INTEGRATION | 他ノードの JOIN 要求を受け入れ、クラスタ統合を進める |
| S_FINALIZE_JOIN | JOIN を確定し、クラスタメンバーシップを確立 |
| S_POLICY_ENGINE | リソース配置計算を実施中 |
| S_TRANSITION_ENGINE | リソース操作を実行中 |
| S_IDLE | 安定状態 |
次に、一例として 起動時および障害発生時における状態遷移の流れについて解説します。
起動時の状態遷移
クラスタの起動時、Pacemaker の各サブデーモンは協調しながら、ノード間でメンバーシップを確立し、リソース配置を決定します。このプロセスは段階的に進み、各状態で必要な初期化や情報収集、計算処理が行われた上で、最終的にクラスタは安定状態に到達します。
起動 │ │ 親デーモン pacemakerd が起動し、各サブデーモンをを順次起動 │ (controld, schedulerd, execd, based, attrd, fenced) │ ▼ S_STARTING (初期化開始) │ │ 自ノード (node1) の状態を unknown → member に更新 │ CIB 読み込み、Corosync 接続 │ 他ノードの参加を待機 │ ▼ S_PENDING (待機) │ │ node2 の参加を検知 │ DC 選挙開始 │ ▼ S_ELECTION (DC選挙) │ │ 投票の結果、node1 が DC に選出 │ ▼ S_INTEGRATION (ノード統合) │ │ JOIN 要求を受け入れ、node2 をクラスタに統合 | ▼ S_FINALIZE_JOIN (JOIN確定) │ │ クラスタメンバーシップを確定 │ │ * pacemaker-based │ JOIN が完了したノード情報を CIB に反映 │ ▼ S_POLICY_ENGINE │ │ * pacemaker-schedulerd │ DC (node1) が決定後、リソース配置計算を開始 │ クラスタ全体のリソースの起動/配置プランを生成 │ 計算結果を pacemaker-controld に渡す │ ▼ S_TRANSITION_ENGINE │ │ * pacemaker-execd │ pacemaker-controld の指示に従って start/stop/monitor を実行 │ 成否を pacemaker-controld にフィードバック │ │ * pacemaker-controld │ リソース操作の成功を確認 │ ▼ S_IDLE (安定状態) │ │ リソース操作がすべて正常終了 │ クラスタは安定状態に遷移 │
障害発生時の状態遷移
クラスタ稼働中にリソース障害やノード障害が発生した場合、Pacemaker はそのイベントを検知し、自動的に回復処理を行います。障害発生時は、クラスタが持つ最新の CIB 情報に基づいて、フェイルオーバーや再起動などのアクションを決定し、適切に実行します。
S_IDLE (安定状態) │ │ クラスタは安定稼働中 │ * pacemaker-execd (node1) │ VIP_monitor_10000 が定期的に実行される │ 結果: 失敗 (rc=7, not running) │ この結果を pacemaker-controld に返却 │ │ * pacemaker-controld (node1) │ monitor 失敗を検知 │ CIB 更新要求を pacemaker-based に送信 │ │ * pacemaker-based (node1) │ CIB 更新要求を処理 │ CIB をディスクに書き込み │ │ * pacemaker-attrd (node1) │ 属性を更新: │ ・last-failure-VIP#monitor_10000[node1] = 1756193718 │ ・fail-count-VIP#monitor_10000[node1] = 1 │ CIB に反映 │ ▼ S_POLICY_ENGINE (リソース配置計算) │ │ * pacemaker-schedulerd (node1) │ CIB の変更を検知し、リソース配置計算を再実行 │ migration-threshold=1 のため node1 での再起動不可と判断 │ VIP を node2 へ移動する決定 │ Transition 10(遷移グラフ)を生成: │ ・VIP_stop on node1 │ ・VIP_start on node2 │ ・VIP_monitor_10000 on node2 (recurring) │ ▼ S_TRANSITION_ENGINE (アクション実行) │ │ * pacemaker-controld (node1) │ pacemaker-schedulerd から受け取った Transition 10 を順次実行 │ まず pacemaker-execd (node1) に VIP_stop を要求 │ │ * pacemaker-execd (node1) │ VIP_stop を実行し、結果を pacemaker-controld に返却 │ │ * pacemaker-controld (node1) │ 次に node2 に VIP_start を指示 │ │ * pacemaker-execd (node2) │ VIP_start を実行 │ VIP_monitor_10000 を開始 │ 結果を pacemaker-controld (node2) に返却 │ ▼ S_IDLE (安定状態復帰) │ │ VIP が node2 上で正常稼働開始 │ monitor 監視も復帰 │ クラスタは再び安定状態へ移行 │
おわりに
今回は、Pacemaker/Corosync のプロセス構成と、pacemaker-controld を中心とした状態遷移の仕組みについて解説しました。
Pacemaker は複数のデーモンプロセスが協調して動作しており、CIB を中心とした情報共有や状態遷移の制御を正しく理解することで、クラスタの挙動をより深く把握できます。これにより、トラブルシューティングやクラスタ構成の最適化を行う際に大いに役立つでしょう。