1. はじめに
ビッグデータの管理・運用で注目を浴びることとなった結果整合性(eventual consistency)ですが,賛否両論あるようです.否定的な意見は,たとえば,クレップマン(Martin Kleppmann)[1]の
著作に見ることができます.この著作,結構多くの方々がお持ちかと思いますが,クレップマンは複
製を行うデータベースのほとんどは,少なくとも結果整合性を提供しているとしながらも,これは非
常に弱い保障であり,複製がいつ(最終値に)収束するのかについては何も語られていなく,収束す
るときまで,読取りの結果が何になるのか,あるいはそもそも何も返さないのかは分からない,とク
レームしています.さらに,CAP 定理の対象範囲は非常に狭く,考慮しているのは 1 つの一貫性モ
デルと 1 種類のフォールト(つまり,ネットワーク分断)だけで,ネットワークの遅延,落ちている
ノード,あるいは他のトレードオフについては何も語っていない.したがって,CAP 定理は歴史的
には大きな影響力があったものの,システムの設計における実際的な価値はほとんどない,と述べて
います(文献[1]の 9 章「一貫性と合意」).
このクレップマンの否定的意見は,読取りの結果が何であるのか分からない,CAP 定理に実際的
価値はない,の 2 つに集約されると思いますが,まず,最初のクレームについて考えてみましょう.
確かに,結果整合性は,「非常に」かどうかは別にして,「弱い保証である」ことに間違いはあり
ません.整合性には強い整合性と弱い整合性があり,結果整合性は弱い整合性の一種であることは,
結果整合性の提案者であるフォーゲルス(Werner Vogels)自身も述べている通りです[2].結果整
合性は Amazon.com, Inc.(以下,Amazon)が開発した「高可用キー・バリューストア」Dynamo[3]
で初めて実装されましたが,フォーゲルスはその開発プロジェクトの中心人物でした(この Dynamo
は Amazon の自社用で,AWS の一環として提供されている Amazon DynamoDB とは別物).複製
が最終値に収束するまでの時間を不整合窓(inconsistent window)といいますが,フォーゲルスに
よれば,不整合窓の最大サイズは,通信の遅延,システムの負荷,レプリケーションスキームに含ま
れる複製の数などの要因に基づいて決定できるとのことです.したがって,これはシステムの負荷や
ネットワーク環境が安定しているときは一定の値を保つかもしれませんが,それらが変動すれば当然
変動するだろうことは想像に難くなく,クレップマンの最初のクレームを理不尽と決めつけるわけに
はいきません.
では,実際に結果整合性を実装したシステムでは不整合窓の長さについてどのような評価がなされ
ているのでしょうか?これに関して,次のような見解を見ることができます.
まず,N,W,R を次のように定めます.
N:データの複製を格納しているノードの数(=複製数)
W:更新完了の返事を返してくるべき複製の数
R:検索結果を返してくるべき複製の数
N,W,R はいかようにも定められますが,結果整合性を念頭に,N=3,W=1,R=1 と設定したシステムでは,可用性と一貫性が共に満たされているとの報告が見受けられます.つまり,W=1,R=1 なので高可用性の実現はその通りですが,一貫性も評価される原因としては,N=3 と複製数が小さいことや,新鮮でないデータでもそんなに腐臭が漂っているわけではないとの見解です.また,不整合窓の長さについては,実測で数 ms(millisecond)という報告もあれば,数 1,000ms という報告も見受けられます.これらの値が許容範囲にあるのかそうでないのかは定かではありませんが,不整合窓が長くてシステムが稼働しないといった報告は見つかりません.したがって,クレップマンが「読取りの結果が何であるのか分からない」としたクレームは,観念的にはそうなのだけれども実際にはその非難は当たっていないのではないか,と言えそうです.
次に,クレップマンが「CAP 定理に実際的価値はない」とクレームしている点についてですが,
CAP 定理の主張する CP あるいは AP の選択で(詳細は 4 章),可用性(A)とネットワークの分断
耐性(P)を選択した Amazon の Dynamo が顧客から間断なく舞い込む注文をこれまで処理し続けてこられたという実績はクレップマンの否定的な意見を覆すに十分な反証となっているのではないかと思います.最近の統計によれば,Amazon 本体(サードパーティの販売者によるマーケットプレイスは除くという意味)が扱っている商品数は約 1,200 万,毎月の顧客数は約 1 億,1 分あたりに売れる商品の数は約 4,000 という状況のようです.それを結果整合性のもとで,Amazon の Dynamo は always-on で処理し続けているわけです.
本稿は,以上のような観点から,結果整合性の意義を ACID vs. BASE という論点とも絡めながら再検討しておきたいと思います.
2. 結果整合性誕生は時代の必然
筆者は結果整合性という概念の誕生は,分散型データベースシステムの概念がウェブそしてビッグデータの到来で根底から変化することになった所産だと捉えています.
歴史的には,分散型データベースシステムは 1970 年代後半から 1980 年代にかけて IBM San Jose 研究所で研究・開発された System R * [4]をもってその嚆矢とすると認識しています.この時代の分散型データベースシステムの使命は遠隔地に散在するビジネスデータをコンピュータネットワークを介して相互アクセスし,いかにして「単一サイトイメージ」を実現するかが設計指針でした.言い換えれば「分散の透明性」の達成です.したがって,分散型データベースシステムはトランザクション処理に関してもあたかも単一サイトのイメージでそれを処理するわけですから,結果整合性などという発想は一切湧かず,単一サイトのデータベースシステムと同様に ACID 特性を堅持することが大前提となっていたわけです.
しかしながら,ウェブの誕生以降状況は徐々に変化していきます.ウェブは 1991 年をもってその元年としますが,その後進化をとげて 2005 年にオライリー(Tim O’Reilly)により Web 2.0 が提唱されました[5].これには経緯があって,その背景には「ドットコムバブルの崩壊」があります.つまり,ウェブ誕生後数年を経た 1995 年頃から 2000 年頃にかけて米国の株式市場はドットコムバブルに沸き返っていました.ドットコム(.com)とは営利企業を表す分野別トップレベルドメイン(generic TLD)で,(ハイテク中心の)ドットコムカンパニーの NASDAQ 指数は 2000 年 4 月 10 日に 5,048 で史上最高となったわけです.インターネット関連ベンチャー企業が株式を上場すれば,期待感から高値で取引されたといわれています.しかし,2000 年に入ると,次第にこれらのベンチャー企業の優勝劣敗が明らかになり,見込みのないベンチャー企業が次々と破たんするようになり,熱狂は一挙に冷めて株価は大暴落し,2001 年秋にバブルは崩壊しました.ドットコムバブルがはじけて,多くのウェブ関連ベンチャー企業が泡沫のごとくこの世から消え去ったのですが,その洗礼を受けつつもその後も成長し続けたベンチャー企業がありました.それらは泡沫のごとく消え去ったベンチャー企業とどこが違っていたのか?オライリーのチームは両者のビジネスモデルの違いに着目して,ブレインストーミングを重ね,その結果が Web 2.0 としてまとめられたというわけですが,ドットコムバブルの荒波を越えて生き残った代表格が Amazon や Google というわけです.
その Amazon が自社のビジネスモデルを達成せんがために構築した分散型データストア(distributed data store, DDS)が Dynamo で,そこで実装されたトランザクション管理の原理が従来の ACID 特性ではなく,結果整合性に基づいた BASE 特性であったということです.いみじくも,Dynamo の開発責任者であったフォーゲルは “Building reliable distributed systems at a worldwide scale demands trade-offs—between consistency and availability.”[2]と結果整合性の意義を述べていますが,この一文が従来の分散型データベースシステムとビッグデータ時代の分散型データベースシステムの構築原理の違いを端的に表していると思います.
3. 分散型データストア
3V(volume, velocity, variety)の性質を有するビッグデータをリレーショナル DBMS で管理・運用しようとすると,たとえばリレーションがとても疎(sparse)になるとか,さまざまな問題が生じて限界があることはよく知られているところです.したがってそのようなデータはビッグデータを扱う各組織体のビジネスモデルに一番合うような形で管理・運用されることが常となりました.たとえば,
Amazon はキー・バリューデータストアを,Google は列ファミリデータストアを,大量の JSON 文書を管理・運用したい組織は文書データストアを,そして,たとえば大規模なソーシャルネットワークを管理・運用したい組織はグラフデータベースを開発するといった具合です.その具体例が,Amazon
の Dymano や Google の BigTable[6]ということになるわけですが,NoSQL(Not only SQL の意)とはこのようなシステムの総称です.
さて,いわゆる NoSQL を標榜するシステムですが,スケーラビリティを(スケールアップではなく)スケールアウトで達成すること,システムは大規模となり個々のコンポーネントにあまりお金は掛けられないこと,システムが大規模になっても可用性は損ないたくないことなどを勘案すると,図 1 に示されるような疎結合クラスタ(shared nothing cluster)構成をとる分散型データストアとするのが一般的です.
少しく説明を加えると,1 台のマスタが複数のクライアントとスレーブを管理します.クライアントからの問合せ(query)や更新要求(insert, delete, update)はマスタに届けられ,マスタはマスタの判断でそれらをスレーブに配信し,その結果をクライアントに届けます.疎結合クラスタ構成をとっているので,データ量が増大するにつれてスレーブを増設していけばシステムのスケーラビリティを台数効果に基づきスケールアウトで達成できます.また,可用性やネットワークの分断耐性を向上させるためにデータは複製(replica,レプリカ)を作成してそれをスレーブに分散配置します.しかしながら,データが重複してスレーブに分散配置されることで,データの一貫性をどのようにして達成するのかが問われることになります.本稿で取り上げている結果整合性はそのために考案されたトランザクション管理のための新しい原理ということです.なお,図 1 ではクライアントがマスタやスレーブと同じネットワークに結合されているので,ネットワーク分断が発生したときにクライアントとマスタが通信できなくなりますが,ここではそれは何らかの手段で確保されていることとします.論点は,ネットワーク分断が発生した場合にマスタと一部のスレーブとの間の通信が不可能となりますが,それがデータベースの可用性と一貫性にどのような影響を与えるのかにあります.
![図 1 NoSQL のアーキテクチャ(疎結合クラスタ構成)[7]](https://www.sraoss.co.jp/tech-blog/wp-content/uploads/2022/12/drmasunaga-11-P04-01.png)
4. CAP 定理
分散型コンピューティングの強靭性に関して,Inktomi 社の創設者であったブルーワ(Eric Brewer)は次のような経験則を 2000 年に開催された国際会議で発表しました[8].
「一貫性,可用性,そしてネットワークの分断耐性の間には基本的にトレードオフがある」
改めて記しますが,一貫性(consistency)とは,書込み操作が完了したのちに読取り操作を発行すれば,その書込みの結果が返されないといけないということで,もしデータを複製して管理している場合には,複製間で更新の同期がとられていて,どの複製を読もうとも,同じ値が返ってこないといけないことを意味します.可用性(availability)とは,クライアントが依頼した読取りや書込みに対して,それが無視されることはなく,いづれ応答があるということをいいます.ネットワークの分断耐性(tolerance to network partitions あるいは partition tolerance)とは,サーバ間でやり取りするメッセージがいくらでも失われうることを意味します.つまり,本来ネットワークは分断されてしまうかもしれないという性質を有するので,ネットワーク分断が発生した状況の中にあっても分散型コンピューティングはそれなりに機能しないといけないということを謳っているものです.そして,ブルーワはこのトレードオフの意味するところを CAP 定理(CAP theorem)と名付けました.ここに,CAP の C は Consistency,A は Availability,P は Partition tolerance の頭文字です.この定理は,発表当初はあくまで推測(conjecture)にしか過ぎなかったのですが,2 年後にその証明が与えられました[9].証明は拙著[7]でも与えられているので興味があれば参照してください.
【定理1】(CAP 定理)[8]
共有データシステムにおいては,一貫性,可用性,分断耐性という 3 つの性質のうち,高々 2 つしか両立させることが出来ない.
CAP 定理を図示すると図 2 のように描けます.
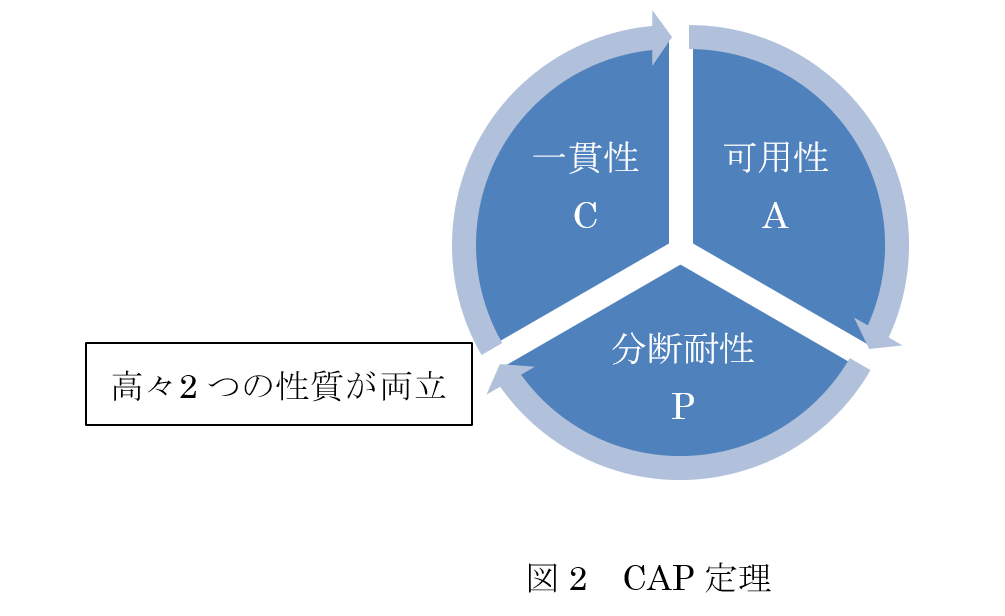
ネットワークは分断するものですから,つまりネットワークが絶対に故障しないという保証を与えることはできないので,共有データシステムはネットワーク分断を前提に,システムとして一貫性(C)の実現を選択しますか?それとも可用性(A)の実現を選択しますか?どちらを採りますか?という選択を迫られることになります.つまり,次に示す二者択一となるわけです.
● CP:一貫性と分断耐性を実現する.
● AP:可用性と分断耐性を実現する.
なお,念のために,両選択の違いを例題で見ておくと次の通りです(AP については第 6 章でさらに議論します).
【例題1】(CP vs. AP)
図 1 に示した構成でスレーブ i とスレーブ i+1 間のネットワークが分断されてしまったとき,CP と AP のもとでシステムがどのように振舞うのかを検証する(ここに,i≦n-1).
● CP を採用した場合
| そのようなネットワークの分断が発生すると,スレーブ 1 ~スレーブ i 群とスレーブ i+1 ~スレーブ n 群は通信不可となる,つまり両群にまたがり存在する同一データの複製間の一貫性を保証する手段がなくなるので,システムはネットワーク分断を検知した時点で停止し,読取り要求も書込み要求も受け付けず,ネットワーク分断の回復を待つ. |
● AP を採用した場合
| マスタはスレーブ 1 ~スレーブ i にアクセスし,N(データの複製数),R(検索結果を返してくるべき複製の数)や W(更新完了の返事を返してくるべき複製の数)が定める定足数に従い行動する.読取り要求の場合,検索されたデータがスレーブ 1 ~スレーブ i にあり,その数が R 以上であればそれをクライアントに返す(複数見つかれば時刻印が最新のデータを返す).書込み要求の場合,マスタはスレーブ 1 ~スレーブ i にその書込み要求を発行する.もし,書込み完了の返事の数が W 以上となれば書込みが完了した旨をクライアントに報告する.そうでなければ,書込み失敗をクライアントに報告する.前者の場合,複製の数は N(≧W)なので,報告時点で書込みが完了していない複製がスレーブ 1 ~スレーブ i 群とスレーブ i+1 ~スレーブ n 群に存在する可能性がある.これらの複製の書込みは遅延複製(lazy replication)[2, 10]で行う.つまり,書込みが可能となり次第,順次更新していく. |
このように,どちらを選択するかで,システムの振舞はがらりと変わってきます.具体的には,先述の通り,CP の選択肢を採ったのが Google の Bigtable であり,AP の選択肢を採ったのが Amazon の Dynamo ということです.Bigtable では分散したデータの複製の更新同期をとり一貫性を実現するために Paxos アルゴリズムが使われています.では,Dynamo は AP を実現するためにどのようなシステムアーキテクチャを開発したのでしょうか?それを以下に見てみます.
5. BASE 特性
CAP 定理により,ネットワークの分断が発生しても,可用性を採るとマスタはアクセスできるスレーブから所望のデータを読み書きできます.しかしながら,読み書きの対象となったデータが最新のデータであるかどうか,つまり一貫性のあるデータであるか否かの保証はありません.つまり,可用性を採ると,ネットワーク分断によりデータには更新されて新値を採るデータと旧値のままのデータが混在することとなり,データベースが一貫している保証はありません.つまり,この状況下では従来のトランザクション管理が金科玉条のごとく信奉してきた ACID 特性という概念が無意味化しているといえます.
では,可用性とネットワークの分断耐性(AP)を採ったシステムは一体どういう特性を満たしているといえるのでしょうか?それが,結果整合性に基づいた BASE 特性であるわけです.ちなみに,
BASE とは次の語群の頭文字です.
- Basically Available
- Soft-state
- Eventual consistency
ここに,Basically Available(基本的に可用)とは,共有データシステムは CAP 定理のいう AP の下で可用ということです.Soft-state(ソフト状態)とは,システムの状態は入力が無くても時間の経過と共に変遷していくであろうということです.Eventual consistency(結果整合性)とは,現時点では一貫性のないデータでもそれに対して何の更新要求も無ければ,何時かは一貫するであろうということです.
なお,BASE という用語ですが,ACID vs. BASE という対比を際立たせるために特に考えられたとのことです.すなわち,ACID の英語での意味は「酸」ですが,BASE は「塩基」(=アルカリ)を意味し,酸とアルカリで世界を 2 分するという意味を込めて,わざわざ BASE と命名されたという逸話が残っています.
では,BASE 特性の基となっている結果整合性をどのように実装するのか,次に見てみます.
6. 結果整合性の実装
BASE 特性を裏打ちする結果整合性はどのようにして実装できるのでしょうか?それを見てみることにします[2].
まず,整合性(一貫性と同義)には 2 つの観点があります.一つはクライアント側から見た場合の整合性です.これは,クライアントにとってデータ更新がどう見えるかということです.もう一つはサーバ側から見た場合で,どのように更新処理がなされるのか,更新する際にシステムとして何を保証することができるかという観点です.
まず,クライアント側から見れば,整合性は次のように大別されます.
● 強い整合性
● 弱い整合性
○ 結果整合性
まず,強い整合性(strong consistency)は,データの更新が完了すると,その後どの複製にアクセスしても更新された値を返してくることをいいます.強い整合性でない場合を弱い整合性(weak consistency)といいます.弱い整合性では,データの更新が完了したとしても,その後のアクセスが更新された値を返すことを保証しません.値が返されるにあたっては,いくつかの条件を満たす必要があります.更新から,クライアントが更新された値を常に見ることが保証される瞬間までの期間を不整合窓(inconsistent window)といいます.
結果整合性(eventual consistency)は弱い整合性の一種です.ストレージシステムは,オブジェクトに対して新しい更新が行われない場合,最終的にすべてのアクセスが最後に更新された値を返すことを保証します.障害が発生しない場合,不整合窓の最大サイズは,通信の遅延,システムの負荷,レプリケーションスキームに含まれるレプリカの数などの要因に基づいて決定できるとされています.
次に,サーバ側から見た場合,結果整合性は次のように形式化することができます.そのために,
N,W,R を次のように定めます.
→ N:データの複製を格納しているノードの数(=複製数)
→ W:更新完了の返事を返してくるべき複製の数
→ R:検索結果を返してくるべき複製の数
つまり,マスタはクライアントからデータの更新要求を受け付けると,そのデータの複製を格納している N 個のスレーブにその更新要求を発送し更新が完了したかどうか,返事を待ちます.もし,少なくとも W 個のスレーブから更新完了の返事が来たら,その時点でマスタはクライアントに更新完了の返事を送ります.一方,クライアントからマスタにデータ検索要求が来たら,マスタはその複製を格納している N 個のスレーブにその検索要求を発送して結果を待ちます.もし少なくとも R 個のスレーブから結果が返ってくれば,その中から最新の結果を選択して(そのために,データには時刻印やバージョンを付けておく),それをクライアントに返します.つまり,W や R はマスタがアクションをとれるための定足数(quorum)を定めていることになります.まとめると次のようになります.
(1) W+R>N の場合:強い整合性で対処する.
(2) W+R≦N の場合:結果整合性で対処する.
若干説明を追加すると,W+R>N の場合,書込み集合と読取り集合の「共通集合」(intersection)
は非空,つまり 2 つの集合は重なり合った部分があるということですから,強い整合性を保証できる
ということです.一方,W+R≦N の場合,共通集合が空となりうるので,強い整合性は保証できず,
この場合には結果整合性で対応しようということです.したがって,結果整合性を実装するというこ
とは,上記(2)の状況となるようなN,W,R を設定して検索や更新要求に対処するということです.
第 1 章での説明と重複しますが,N=3,W=1,R=1 と設定することで可用性と一貫性が共に満た
されているとの報告が見られます.W=1,R=1 なので高可用性の実現はその通りですが,一貫性も
評価される原因としては,N=3 と複製の数が小さいことや,新鮮でないデータでもそんなに腐臭が
漂っているわけではない,という見解も見られます.不整合窓の長さについては,実測で数 ms
(millisecond)という報告もあれば,数 1,000ms という報告もあります.これらの値が許容範囲に
あるのかそうでないのかは定かではありませんが,不整合窓が長くてシステムが稼働しないといった
報告は見つかりません.
なお,N,W,R の設定の仕方でシステムの振る舞いは相当に変わってきます.N=2, W=1, R=1 では強い整合性とはならないので一貫性は保証されないことに注意します.高性能で高可用な分散型データストアでは通常 N≧3 といわれています.一方,耐故障性(fault tolerance)を謳うシステムは,強い整合性を実現できる N=3, W=2, R=2 をとることが多いとのことです.組合せはさまざまで,興味のある者は論文[2]にあたってみてください.
DNS (Domain Name System)は結果整合性を実装する最も一般的なシステムとして知られていますが,Dynamo がキー・バリューデータモデルの考案と共に,結果整合性を実装してトランザクション管理を行うことで,Amazon の顧客はいつでも待たされることなく(always-on),ショッピングカートに入れた商品の注文を確定することができているという事実の説得性をここで改めて強調しておきたいと思います.
7.おわりに
分散型データストアを構築しようとしたとき,「ACID 特性 vs. BASE 特性」,あるいは「CP vs. AP」,あるいは「強い整合性 vs. 結果整合性」はきっと永遠のテーマだと思いますが,BASE・AP・結果整合性の採用は高可用性やスケーラビリティを達成したい分散型データストアの設計指針として,大変理に適っている発想だと思います.結果整合性が世に出て早くも十数年の月日が流れました.改めて,結果整合性の意義を回顧する報告が出ています[11, 12, 13].興味のある方には一読を勧めますが,いずれも結果整合性を肯定的に捉えています.
分散コンピューティングをデータベースの視点で捉えると,単一サイトイメージの達成が至上命令であった時代から数十年を経て,分散型データ管理は結果整合性で対応していこうという時代の流れになりました.この背景には,ビッグデータの管理・運用こそがビジネスモデルとする巨大な IT企業の誕生がありました.従来は基幹システムと称して OLTP がデータ処理の中核で,そこでは金科玉条のごとく ACID 特性への順守が叫ばれました.これは単一サイト,分散型を問わずということです.しかし,
ACID 特性は 3V の特徴を有するビッグデータの管理.運用が求める原理・原則ではなかったということです.そして,その要求に応えるべく必然的に生まれたのが BASE 特性であり結果整合性であったということです.
筆者はかつて IBM San Jose 研究所の客員研究員として,分散型リレーショナルデータベース管理システム開発の草分けであった System R* プロジェクトのメンバーとしてそのアクティビティを 1 年間にわたり目の当たりにしましたが,隔世の感を禁じ得ません.
【文献】
[1]
| Martin Kleppmann. 斉藤太郎(監訳).玉川竜司(訳).データ指向アプリケーションデザイン 信頼性,拡張性,保守性の高い分散システム設計の原理.オライリー・ジャパン,634p., 2019. |
[2]
| Werner Vogels. Eventually Consistent. ACM Queue, Vol. 6, Issue 6, pp 14–19, 2008. (同一内容の論文が,Werner Vogels. Eventually consistent. Communications of the ACM, Vol. 52, Issue 1, pp.40–44, 2009. として出版されている) |
[3]
| G. DeCandia, D. Hastorun, M. Jampani, G. Kakulapati, A. Lakshman, A. Pilchin, S. Sivasubramanian, P. Vosshall and W. Vogels. Dynamo: Amazon’s Highly Available Key-value Store. Proceedings of the 21st ACM Symposium on Operating Systems Principles (SOSP’07), pp.205-220, October 14–17, 2007. |
[4]
| B.G. Lindsay, L.M. Haas, C. Mohan, P.F. Wilms and R.A. Yost. Computation and communication in R*: A distributed database manager. ACM Transactions on Computer Systems, Volume 2, Issue 1, pp 24–38, February 1984. |
[5]
| Tim O’Reilly. What Is Web 2.0: Design Patterns and Business Models for the Next Generation of Software. 2005. |
[6]
| Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach, Mike Burrows, Tushar Chandra, Andrew Fikes and Robert E. Gruber. Bigtable: A Distributed Storage System for Structured Data. Proceedings of the 7th USENIX Symposium on Operating Systems Design and Implementation (OSDI’06), pp.205-218, 2006. |
[7]
| 増永良文.リレーショナルデータベース入門[第3版].サイエンス社,2017. |
[8]
| Eric A. Brewer. Towards Robust Distributed Systems (abstract), (Invited Talk). Proceedings of the 19th ACM Symposium on Principles of Distributed Computing, p.7, Portland, Oregon, July 2000. |
[9]
| S. Gilbert and N. Lynch. Brewer’s Conjecture and the Feasibility of Consistent, Available, Partition-tolerant Web Services. ACM SIGACT News Homepage Archive, Volume 33, Issue 2, pp.51-59, June 2002. |
[10]
| Rivka Ladin, Barbara Liskov, Liuba Shrira and Sanjay Ghemawat. Providing High Availability Using Lazy Replication. ACM Transactions on Computer Systems, Vol 10, No. 4, pp. 360–391, November 1992. |
[11]
| Dan Pritchett. BASE: An Acid Alternative: In partitioned databases, trading some consistency for availability can lead to dramatic improvements in scalability. ACM Queue, Vol. 6, Issue 3, pp 48–55, 2008. |
[12]
| Eric A. Brewer. CAP Twelve Years Later: How the “Rules” Have Changed. Computer, Vol.45, Issue 2, pp.23-29, IEEE Computer Society, 2012. |
[13]
| Peter Bailis and Ali Ghodsi. Eventual Consistency Today: Limitations, Extensions, and Beyond: How can applications be built on eventually consistent infrastructure given no guarantee of safety? ACM Queue, Vol.11, Issue 3, pp.20-32, 2013. |