1. はじめに
リレーショナルデータモデルの始祖コッド(E.F. Codd)はリレーション(relation)とは集合(set)であると定義しました.ここに,集合とは数学における「集合」を意味し,集合論の始祖カントール(G. Cantor)は「集合とは異なる元(element)の集まり」と定義しました.したがって,リレーションに重複したタップル(tuple)は出現しません.また,それが故にリレーションには必ず「キー」が定義できます.
一方,国際標準リレーショナルデータベース言語 SQL (以下,SQL) で定義されるテーブル (table,表) は集合ではありません.テーブルでは重複したタップルの出現が許されるからです.したがって,テーブルでは必ずしもキーを定義できるわけではありません.
テーブルは一般的にはバッグ(bag),数学ではマルチ集合(multiset)と呼ばれます.リレーションとテーブルの違いは,フォーマルには,リレーショナルデータモデルは集合意味論 (set semantics) に則り,SQL はバッグ意味論(bag semantics)に則った体系であると説明できます.意味論が違うので,当然のことながらリレーショナルデータモデルと実践のためのSQLではいろいろと違いが出てきます.本稿では,リレーションに対するデータ操作では起こり得ませんが,テーブルのデータ操作で発生する「重複タップルの部分削除」(partial delete of duplicate tuples)に焦点を当てて,少しく蘊蓄を傾けてみたいと思います.
2. 重複タップルの部分削除問題
まず,バッグ(=テーブル)をフォーマルに定義しておきます.ここに,リレーションスキーマ R はリレーション名 R と属性集合 ΩR={A1, A2, …, An} からなり,R(A1, A2, …, An)と定義されます.
【定義 1】(バッグ)
R(A1, A2, …, An) をリレーションスキーマ,dom をドメイン関数,dom(R)=dom(A1)×dom(A2)×・
・・×dom(An) とする.このとき,R(A1, A2, …, An) のバッグ R(A1, A2, …, An) は次のように定義される.
R(A1, A2, …, An)={t1(k1), t2(k2), …, tp(kp)}
ここに,(∀i, j)(i≠j ⇒ ti≠tj) であり,(∀i=1,..,p)(ti∈dom(R)∧ki≧1) とし,ti(ki) はバッグ R にタップル ti が丁度 ki 本あることを表すための記法である.ki を ti の重複度(multiplicity)という.
(定義終)
R の濃度(cardinality)を |R|=∑i=1,..,pki と定義します.なお,ki=1 のとき,ti(1) と書かずに単に ti と書くことがあります.また ti(0) は ti が存在していないことを表します.定義 1 から明らかなように,バッグ R は (∀i=1,..,p)(ki=1) のときリレーションです.
さて,集合と違ってバッグ(=マルチ集合)の特徴を表す大事な原理があります.それを次に示します.
■ 重複元の識別不可能性原理
バッグがリレーションと根本的に異なる点は,バッグには重複した元が存在しうることです.たとえば,バッグ R(A1, A2, …, An)={t1(k1), t2(k2), …, tp(kp)} の要素 ti(ki) は R にタップル ti が ki 本存在していることを表していますが,大事な点は,これら ki 本のタップル ti を識別することは不可能なことです.このことは,t1(k1), t2(k2), …, tp(kp) の全てに対して成立します.この性質を重複元の識別不可能性原理(principle of indistinguishability of duplicate elements)といいます[1].
この原理はとても大事です.たとえば,バッグ R(A)={1(3), 2} があったとき,タップル 1 は 3 本あるわけですが,それら 3 つの 1 に,たとえば色付けをして,赤の 1 とか青の 1 とか言うことはできないということです.3 つの 1 は識別不可能ということです.したがって,3 本あるタップル 1 を 1 本だけ削除したいと要求しようとしたとき,3 つの 1 のうちのどの 1 を削除してくれとは指定できないということですし,一方で,3 つの 1 から 1 本だけを削除してくれと依頼されたとき,どの 1 を削除したらよいのか,適当に 1 を 1 つ選択して削除してよいのか,どうしたらよいのか分からない,ということです.
■ 重複タップルの部分削除
重複元の識別不可能性原理に忠実であると,重複タップルの全部削除は認めるが部分削除は認められないということになってしまいます.しかし,バッグ意味論に則り設計されている SQL の現場では,部分削除を必要とする状況は確実にあり得るようです.たとえば,マテリアライズドビューでは重複タップルの発生はごく自然に考えられますし,何らかのエラーでテーブルに重複したタップルが発生してしまった場合にそれらを削除したいという状況も考えられます.
そこで,重複タップルの部分削除を何とか実現できないものかが重要な課題となります.選択肢として次の 2 つのアプローチ (a) と (b) が考えられます.ここに,テーブル R 中には t(n),すなわち,タップル t が重複して n 本存在していて,R から m(1≦m<n) 本のタップル t を削除したいということです.
(a) まず,n 本のタップル t をすべて削除し,続いて,n-m 本のタップル t,即ち t(n-m) を
挿入する.
(b) n 本のタップル t の中から適当に m 本を選択して削除する.
(a) は,R から t(n) すべてを削除することは重複元の識別不可能性原理には抵触せずにできます.また,t(n-m) を挿入することも問題なくできます.ただ,この総入れ替えの考え方は,現行の DELETE 文を使いつつも何とか部分削除を実現する手法を検討しようという本稿の趣旨とはそぐわないので,このアプローチは割愛することとします.
そこで (b) ですが,(b) を実現するにあたっては,「適当」とはどういうことか,そこが大事な論点となります.重複したタップルはみな同一であって識別不可能とは言いながらも,何らかの手段でそこに一意識別性を持ち込みたい.もちろん,あくまで「便法」です.
本来であれば,「識別不可能な重複タップルに便宜的に一意性を付与」する役割があったのは行(row)の oid です.これは歴史的にもそういう位置づけになっています.ただ,ご存知のように,現在の PostgreSQL では行 oid はデフォルトでは排除されているので,oid を本来一識別不可能な重複タップルに便宜的に一意性を付与する目的には事実上使えなくなっています.
そこで,次の 2 つのアプローチを検討してみることにしました.
(i) ctid を用いて重複タップルの部分削除を実現する.
(ii) ctid を使わないで,ORDER BY 句と LIMIT 句を用いて重複タップルの部分削除を実現する.
一体,何が起こるでしょうか?以下に示すように,PostgreSQL 14 で実行してみると,(i) では見かけ上,「部分削除」を実現できますが,(ii) では問題含みの展開となります.見ていきましょう.
3. ctid を用いた重複タップルの部分削除
ctid とは “current tuple identifier”[2] の頭字語です.Current とは「現時点の」という意味ですが,
PostgreSQL はテーブルをヒープファイルに格納して,MVCC のもと追記型アーキテクチャでタップルを更新するので,tid (tuple identifier) がタップルの更新や VACUUM FULL などによってその都度変化することに因んだ命名です.ctid は,たとえば(0,3)というような対として定義されますが,第 1 成分,この場合は 0,がそのタップルが格納されているページを,第 2 成分である 3 はそのページ内でのオフセットを指しています.ctid は「隠しカラム」なので,ctid を用いて重複タップルを部分削除するという発想に至るのはエンドユーザには少々ハードルの高さを感じますが,PostgreSQL の内部構造に明るい人であれば極めて自然な発想かもしれません.
では,例題を交えて,ctid を用いた重複タップルの部分削除の様子を見ていきましょう.まず,テーブル r(a)={1(3), 2} を作成します(以下,全て PostgreSQL 14 で実行).

続いて,これら 4 本のタップルの格納状況を見てみます.

ちなみに,この SELECT 文がどのように処理されるのか,QUERY PLAN を見てみると次の通りです.見ての通り,“Seq Scan on r” が実行されています.tid は使われていません.

次に,r からタップル 1 を 1 本だけ削除するべく LIMIT 句を用いることにします.「LIMIT 句を使用する時は, 結果の行を一意な順序に制御する ORDER BY 句を使用することが重要です.ORDER BY を使わなければ,問い合わせの行について予測不能な部分集合を得ることになるでしょう.10 番目から 20 番目の行を問い合わせることもあるでしょうが,どういう並び順での 10 番目から 20 番目の行でしょうか? ORDER BY 句を指定しなければ,並び順はわかりません」[3] と注意書きがあるので,
ORDER BY 句を併用します.そのための DELETE 文は ctid と副問合せ(subquery)を用いて次のように作成され,その実行計画と実行結果は以下の通りです.

この場合,WHERE 句の citd を処理するために,“Tid Scan on r” が実行されて,削除されたタップル 1 の ctid はこの時点で一番小さい (0,1) であると説明できます.
これは本題とは関係ありませんが,ctid を理解するために,タップル 1 が削除された上記のテーブル r に,改めてタップル 1 を挿入した場合の ctid の挙動を確認しておきますが,新しく挿入されたタップル 1 の ctid は (0,5) となりました.PostgreSQL のテーブルはヒープファイルとして格納され,この例ではテーブル r も小さくてそれを格納しているページ 0 に新たにタップル 1 を格納する余裕もあり,
vacuuming もされていないので,その結果は明白でしょう.

念のために,OFFSET 句を指定して新しく挿入された ctid=(0,5) のタップル 1 を削除してみます.そのための DELETE 文は次の通りです.実行してみると,確かに,OFFSET 2 が効いて,3番目のタップル 1,つまり,ctid=(0,5) のタップル1が削除されています.QUERY PLAN からも分かるように,この場合も WHERE 句の citd を処理するために,“Tid Scan on r” が実施されて,削除されたタップル 1 の ctid はこの時点で3番目に大きい (0,5) であることが分かります.

このように,ctid と副問合せを用いると,n 本ある同一タップルから m(1≦m<n)本だけ削除することができています.また,OFFSET 句を使うと削除されるタップルの先頭位置をずらせます.つまり,本来はマルチ集合の重複元の識別不可能性原理により重複タップルの部分削除はできないはずなのですが, ctid と副問合せを併用することにより,その時点での重複したタップルのどれを,つまり,どういう ctid を持ったタップルを削除したのか説明できるというわけです.
では,話を一歩進めて,ctid と副問合せを使わないで重複タップルの部分削除は行えないのでしょうか? 次に,それにトライすることにします.
4. ORDER BY 句と LIMIT 句を併用した重複タップルの部分削除
ORDER BY句と LIMIT句を併用すれば重複した n本のタップルから m (1≦m<n)本だけ削除することを指定できるのではないかと考えました.その論拠は,それらを併用して重複した n本のタップルのうち,m (1≦m<n)本だけを「問い合せる」ことができるからです.以下に示す SELECT 文の通りです.
■ ORDER BY 句と LIMIT 句を併用した問合せ
テーブル r に 3 本重複出現しているタップル 1 のうちの 1 本だけを検索する SELECT 文を発行してみます.ORDER BY 句と LIMIT 句を併用しています(どのタップル 1 が検索されたのかも知るために ctid も一緒に検索します).

この結果を見ると,テーブル r のタップル 1 の中で ctid の一番小さな ctid=(0,1) のタップルが選択されていますが,QUERY PLAN では r は sequential scan されています(Seq Scan on r の実行).ということは,上記の結果は「たまたま」ctid=(0,1) のタップル 1 が選択されただけ,という解釈になります.sequential scan と tid scan の関係性ですが,syncronize seq scan 機能が使われた場合や,
parallel seq scan が使われた場合には,タップルが格納順に返ってくる保証は無いとのことです.
さて,ここからが,本題です.
■ ORDER BY 句と LIMIT 句を併用した部分削除
上述のごとく,ORDER BY 句と LIMIT 句を併用した問合せは問題なく実行されたので,重複タップルの部分削除について次のように考えました.
「ORDER BY 句と LIMIT 句を併用した SELECT 文はうまくいった!
だったら,その WHERE 句を使って DELETE 文も処理してくれるかな?」
そこで,次の DELETE 文を発行してチェックしました.この DELETE 文の WHERE 句は上述の SELECT 文の WHERE 句と全く同じであることに注意してください.

エッ!撃沈です! SELECT 文や DELETE 文の定義構文(の基本)は下に示される通りで,SELECT 文が通ったのだから DELETE 文も問題なく実行されるだろうと思い込んでいた筆者にとっては理解不可能なメッセージでした.
SELECT 〈列リスト〉 FROM 〈対象表リスト〉
[ WHERE 〈探索条件〉]
DELETE FROM 〈対象表〉
[ WHERE 〈探索条件〉]
実は,このことについて,SELECT 文と DELETE 文では,厳密にはその WHERE 句の定義構文が異なり筆者が思い込んでいた世界とは異なることを,SRA OSS, Inc.日本支社の石井達夫氏と長田悠吾氏から教唆されました.実際,SQL の最新規格である SQL:2016 にあたってみると,【付録 1 】と【付録 2 】に示したように,それらは異なっています[4].
要点を掻い摘んで示すと,まず,SELECT 文の〈探索条件〉である query expression> の最上位の定義は次の通りです.

一方,delete statement: searched> の最上位の定義は次の通りです.

注意するべき点は,この DELETE 文の〈探索条件〉である search condition> ですが,【付録 2 】にその詳細が展開されているように,そこには SELECT 文の〈探索条件〉である query expression> で出現が許されている order by clause>,result offset clause>,fetch first clause> は許されていません.
そもそも, OFFSET 句や LIMIT 句は PostgreSQL の拡張であって,それらは SQL 標準の result offset clause> や fetch first clause> に対応しているとのことですが,PostgreSQL が SQL 標準に忠実な実装を行っていれば,DELETE 文に OFFSET 句や LIMIT 句の使用は許さないということになります.つまり,上記の DELETE 文 delete from r where a=1 order by a asc limit 1; が ERROR となったのは,それが原因だったと理解すべきいうことになります.ただ,典型的なエンドユーザである筆者にとっては(繰り返しになりますが)「SELECT 文の WHERE 句で同定されたタップルを r から削除すればよいだけのことなのに...」と,もう一つ腑に落ちないところではありました.
5. 「ORDER BY 句と LIMIT 句を併用した重複タップルの部分削除」の後日談
4 章の話には,後日談があります.筆者の疑問も尤もと思って下さった SRA OSS 日本支社事業本部技術開発室主任研究員の長田悠吾氏が,「試しにパッチを書いてコミュニティの意見を聞いてみた」と い う こ と で ,“Allow DELETE to use ORDER BY and LIMIT/OFFSET” と 題 し て pgsql-hackers@
postgresql.org へ投稿してくださいました[5].そうしたところ,即座に Tom Lane(PostgreSQL 開発コミュニティのコアメンバー)から「確かに,これは技術的には可能ですが,私たちは以前にそのアイディアを却下したことがあり,私は考えを変える理由を知りません.問題は,部分的な DELETE は,どの行が削除されるかについてあまり決定論的ではなく,データ更新コマンドの優れたプロパティとは思えないことです」と反対意見が投稿されてきました[6].長田主任研究員と Tom Lane のやり取りは現状ここまでですが,Tom Lane の反対意見は「どの行が削除されるかについてあまり決定論的ではなく」ということで,それはマルチ集合論の「重複元の識別不可能性原理」と符合する理由付けです.それが理由でしたら,本稿で蘊蓄を傾けたように SELECT 文に準じて DELETE 文を受け付けてくれても良いように思ってしまいます.そうではなく,そのような DELETE 文は SQL で許されていない syntax error だ!と切り捨ててくれた方がすっきりします.そうすれば,問題は標準 SQLマターになりますからね.
6. おわりに
以上が重複タップルの部分削除の議論です.
ここでは,上で書ききれなかったことを一つだけ補足します.3 章で示したように,ctid と副問合せを使うと,それなりの説得性を持って重複タップルの部分削除を実現することができました.だったら,「テーブル r から a=1 のタップルをオフセット s で m 行削除したい」という要求を次のように書くことを許したらどうでしょうか?(SELECT 文についても同様)
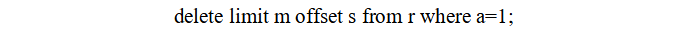
PostgreSQLはこの DELETE 文を粛々と次の DELETE 文に変換すればよいだけのことです.
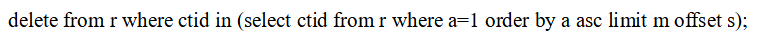
この DELETE 文は次に示すように PostgreSQL で問題なく実行できます(m=1, s=2).

明らかに,提案している DELETE 文をサポートしようとすると,DELETE 文の構文に変更を加える必要があり,SQL の標準化委員会である ISO/IEC JTC1/SC 32 WG 3 (SQL) に諮らないといけないマターとなるのでしょう.しかしながら,上述の機能を PostgreSQL の extension としてサポートしてくれれば大変有難いのかな,と思ってしまいます.このような機能の必要性は,SQL が集合意味論ではなく「バッグ意味論」に立脚しているからこそ出てくる根本的で切実な要望だと考えるからです.
【謝辞】
本稿を認めるにあたり,SRA OSS, Inc. 日本支社支社長の石井達夫氏,並びに同社事業本部
技術開発室主任研究員の長田悠吾氏から有益なご助言を多々頂きました.また,長田主任研
究員は,5 章の後日談で記しましたように,4 章で提起した筆者の疑問も尤もと捉えて下さり,
早速に pgsql-hackers@postgresql.org へパッチを投稿して下さり,その結果,Tom Lane の
見解を聞くこともできました.この場を借りて改めて深く感謝の意を表します.
【文献】
[1]
| Wayne D. Blizard. Multiset theory. Notre Dame Journal of Formal Logic, Vol. 30 (1), pp.36-66, 1988. |
[2]
|
Bruce Momjian. PostgreSQL: Re: Tuple identifier (tid) – object identifiers. 2002. https://www.postgresql.org/message-id/200208281654.g7SGsJB20339@candle.pha.pa.us |
[3]
|
PostgreSQLグローバル開発グループ. PostgreSQL 14.0文書,7.6. LIMITとOFFSET. https://pgsql-jp.github.io/current/postgres-A4.pdf |
[4]
|
SQL:2016 Document. http://jakewheat.github.io/sql-overview/sql-2016-foundation-grammar.html |
[5]
|
Yugo Nagata.Allow DELETE to use ORDER BY and LIMIT/OFFSET. 2021-12-17 00:47:18. https://www.postgresql.org/message-id/20211217094718.0d4d1c9eea684d09d8111c5d%40sraoss.co.jp |
[6]
|
Tom Lane. Re: Allow DELETE to use ORDER BY and LIMIT/OFFSET. 2021-12-17 03:17:58. https://www.postgresql.org/message-id/1272732.1639711078%40sss.pgh.pa.us |
【付録】
【付録 1 】query expression> の定義

【付録 2 】delete statement: searched> の定義

以上