1. はじめに
トランザクションの同時実行制御は障害時回復とならんでトランザクション管理には欠かせない機能であることは言うまでもないことです.そのために 2 相ロッキング(two phase locking, 2PL)プロトコルが考案され,伝統的に 2PL が多くのデータベース管理システム(DBMS)で実装されてきました.しかし,2PLでは同時実行されているトランザクションの直列化可能性を保証するために,トランザクションは読取りや更新の対象となるオブジェクトをロック(lock,施錠)することが必要で,それによる同時実行性(concurrency)の制約は古くから認識されるところでした.
多版同時実行制御(multiversion concurrency control, MVCC)は 2PL とは異なり,競合しているトランザクションの実行終了を待つのではなく,同じデータ項目の異なる版(version)を用意することによって,トランザクションの隔離性を向上させ,同時実行性を高めようとするアプローチです.データ項目の版という概念の導入は 1978 年に遡りますが[1],その考え方はデータベース分野に直ちに入り込み,1980 年代初頭には MVCC の理論の礎が築かれました[2].MVCC と一口に言ってもその実現法は MVTO(multiversion timestamp ordering),MV2PL,MVMM,MVOCC,SI(snapshot isolation,スナップショット隔離性),SSI(serializable snapshot isolation,直列化可能スナップショット隔離性)など多様です.現在 MVCC はこのようなさまざまな実現法を包括した用語として用いられると同時に,狭義には MVCC の原点である MVTO を指す言葉としても用いられます.現在,多くのプロプラィエタリ(proprietary)あるいは OSS のリレーショナル DBMS で MVCC が実装されています.
2PL と MVCC ではトランザクションの同時持実行制御の考え方が根本的に異なるので,2PL を念頭に制定された国際標準リレーショナルデータベース言語 SQL が定めた隔離性水準(isolation level)と MVCC の提供する隔離性水準との間には齟齬が出ます.現在 PostgreSQL や Oracle で実装されている SI は ANSI SQL の隔離性水準を論評する過程で考案され,1995 年に公表されました[5].
本稿では,MVTO と SI を中心において,MVCCと は何かを改めて議論しておきたいと考えます.
2. MVCC
2.1 MVCC とは
MVCC という用語はとても一般的になっていますが,そもそも MVCC という概念は「更新可能なオブジェクトを不変な版(version)の系列と見なす」と発想した Reed の博士論文 “Naming and Synchronization in a Decentralized Computer Systems”[1] に見ることができます(1978 年 9 月にマサチューセッツ工科大学(MIT)に提出した学位請求論文).この考え方は 1981 年に InterBase で実装されたということです(その後,Firebird としてオープンソース化されました).
データベース分野で MVCC が本格的に論じられたのは Bernstein と Goodman が 1981 年に発表した論文 “Concurrency Control in Distributed Database Systems”[2]と考えられます.彼らはその論文で Reed の手法を “Multiversion Timestamp Ordering (MVTO)” として形式化し,その正当性の証明を与えて MVCC によるトランザクションの同時実行制御の時代の幕を切って落としました.MVCC の実現法はざまざまに考えられ,彼らはその論文で MVTO に加えて,従来の2PLに版の概念を導入して拡張した MV2PL,読みのみを発行するトランザクションを同期させるためには MVTO を使用し読み書きを行うトランザクションの同期には厳密な 2PL(strict 2PL)を使うMVMM(multiversion mixed method)を提案し,それらの正当性を証明しています.これら,初期の MVCC の手法は Bernstein らの一連の論文と著書に詳しく記載されています[2, 3, 4].その後,MVCC の手法として Larson ら[6]により MVOCC が提案されています.これは,トランザクションの同時実行制御法として知られている楽観的同時実行制御法(optimistic concurrency control, OCC)[7]に多版(multiversion)の概念を導入した手法です.そして,ANSI SQL の隔離性水準を論評する過程でスナップショット隔離性(snapshot isolation, SI)が提案されました[5].1995 年のことです.SI やそれを直列化可能とした直列化可能スナップショット隔離性(Serializable snapshot isolation,SSI)はシドニー大学(University of Sydney)の Fekete や Cahill ら[8, 9, 10]によりその性質や実装法が明らかにされましたが,それらも MVCC の一種です.このように MVCC は,広義には SI や SSI を含む多くの異形をカバーする用語ですが,狭義には MVTO を表す用語と理解するのが理にかなっているかと考えます.
2.2 2PL vs. MVCC
2PL ではなく,MVCC でトランザクションの同時実行を行うと何が嬉しいのか,それを単純ですが典型的な例で確認しておきたいと思います.以下,ここで想定している MVCC は,この概念の基礎となった MVTO をフォーマルに記述したものとします.なお,トランザクションの同時実行スケジュール,スケジュールのビュー等価(view equivalence)や相反等価(conflict equivalence)などの説明は省略しますが,参照されたい向きには拙著[11]を薦めます.
まず具体的に MVCC の意味するところを直観することにします.そこで,S1 をトランザクション T1 と T2 の同時実行スケジュールとし,図 1(a)に示す通りとしましょう.すると,S1 は相反直列化可能でない(従ってビュー直列化可能でもない)ことが確かめられますから,S1 は 2PL では正しい実行を保証されないスケジュールであることが分かります.
ところが,MVCC のもとではこのスケジュールでトランザクションを実行しても正しい結果が得られます.それはどうしてでしょうか?そうなる仕組みはどのようなものなのでしょうか?それを見てみましょう.
まず,具体的に,なぜスケジュール S1 は正しい結果を保証しないのでしょうか?それは,時刻5で発行された T1のデータ項目 y の読み,T1:read(y) は,T2 が時刻 4 で y に書き出した T2:write(y) の結果を読んでしまうが,(トランザクションの隔離性という観点から考えれば)本来はデータ項目 y の初期値,これを y0 と書く,を読みたかったはずなのに,スケジュール S1 ではそれが叶わなかったということです.
しかし,もし T1 と T2 の同時実行スケジュールが図 1(b)に示した S2 であったらどうでしょうか?このときは,容易に確かめられるように,S2 は相反直列化可能スケジュールとなり,このスケジュールで T1 と T2 を同時実行すれば正しい結果が保証されます.

図 1 スケジュール S1 と S2
さて,実は,MVCC のもとでは,スケジュール S1 に従ってトランザクション T1 と T2 を同時実行しても,正しい結果を保証してくれます.これはどうしてかというと,MVCC では版の概念があるので,たとえスケジュール S1 に従って T1 と T2 を同時実行しても,実質的にはスケジュール S2 で T1 と T2 を実行したことになるからです.それが正しく MVCC の意図するところです.
そこで, MVCC アルゴリズムに従いトランザクションの同時実行をスケジュールする多版スケジューラ(mulitiversion scheduler)がどのようにトランザクションステップの実行を制御していくのか,そのアルゴリズムを示しますが,それを理解するための助けとなるかと考え,いくつか補足的説明を行います.
(1)
| トランザクション群 {T1,T2,・・・,Tn}を同時実行するためのスケジュール S が与えられたとする.S に従いトランザクション Ti が実行を開始したとき,その時の時刻を Ti に時刻印(timestamp),これをts(Ti)と書く,として付与する.一般に,時刻は単調に増加する識別子,例えばカウンタ,なら何でもよい(その意味で論理時刻ともいう).トランザクションは並列(parallel)実行ではなく,同時(concurrent)実行なので,お互いの開始時間は異なるから,トランザクションが異なればそれらの時刻印は異なっていて,一意性が保証されている.つまり,時刻印を比較するとどちらが先発,あるいは後発のトランザクションであるかが分かる. |
(2)
| 次に,データ項目 x を考える.多版スケジューラは x の版,これを xi, xj, xk, …という具合に書く,を保持する.版はトランザクションがデータ項目に対して書きを実行したときに生成される.例えば,トランザクション Ti がデータ項目 x に対して write(x) を発行しそれが実行されれば,版 xi が生成される.このとき,xi にはそれが生成された時刻が時刻印として付与される.また,MVCC アルゴリズムはデータ項目の版に基づき作動するので,トランザクションの同時実行で使われるデータ項目 x については,その初期版(initial version)を設定しておく必要がある.そのために,各データ項目 x の初期版 x0 を生成する擬似的なトランザクション T0,その時刻印は 0 とする,がすべてのトランザクションステップに先行して実行されることとする. |
(3)
| MVCC アルゴリズムを理解する上で大事なことは,データ項目 x の版の存在は多版スケジューラが把握していればよいことであって,ユーザが意識する必要はない.つまり,ユーザが発行するトランザクションはデータ項目の版を意識する必要はないということである.換言すれば,ユーザにとっては,データ項目 x の版はただ 1 つしかないといえる.したがって,トランザクション Ti からデータ項目 x に対して読み(Ti:read(x))や書き(Ti:write(x))が発行された場合,多版スケジューラはそれらをデータマネジャが処理できるようにするために, データ項目 x の版,xi, xj, xk,…,に対する読み(ri[xk],Ti が版 xk を読むという意味)や書き(wi[xi],Ti が x に書込みをして版 xi が生成される)に変換しないといけない.その変換によって,図 1 の例で説明すれば,スケジュール S1 はあたかもスケジュール S2 に従っているかのような実行を実現できたのである. |
【MVCC アルゴリズム】
MVCC アルゴリズムは次の規則に則り,トランザクションの読みや書きを版(version)への読込みや書込みに変換する.
(1) Ti:read(x) を ri[xk] に変換する.このとき xk は ts(Ti) 以下で最大の時刻印を持つ x の
版を表す.
(2) Ti:write(x) は次の 2 つに場合分けされる.
(i) もし,ts(Tk)<ts(Ti)<ts(Tj)を満たす i, j, k に対して,rj[xk]なる処理が行われてい
たならば,Ti:write(x) は棄却される(従って,Ti はアボートされる.).
(ii) そうでなければ,Ti:write(x)をwi[xi] に変換する.
補足すると,(2)(i) の言っていることは,自分(Ti)より後発のトランザクション(Tj)が自分より先発のトランザクション(Tk)が書き出した結果を読んでしまっている(rj[xk])なら,自分がそのデータ項目 x を書き換えるとことは許されない,ということである.
さて,MVCC アルゴリズムに従った多版スケジューラが出力したスケジュールを多版スケジュールといいますが,この MVCC アルゴリズムに従って,図 1 (a) に示したスケジュール S1 でトランザクション T1 と T2 を同時実行して得られた多版スケジュールを図 2 に示します(←は代入を表す).特に注目するべきところは,時刻 5 で,T1:read(x) は MVCC のもとでは,T2 が直前に書き出した y2 を読むのではなく,MVCC アルゴリズムの (1) により,y の初期値 y0 を読んでいるところです.その結果,
MVCC に従うとスケジュール S1 で T1 と T2 を同時実行しても,その実行結果としての多版スケジュールは従来の相反直列化可能なスケジュール S2 での実行と同じになっていて,従って,正しい実行であると考えることができるわけです.

図 2 スケジュール S1 の多版スケジュール
このように,2PL の同時実行制御の考え方では相反直列化可能ではないスケジュール S1 が,MVCC アルゴリズムのもとでは正しい実行を保証してくれるスケジュールと考えてよいことを示しましたが,この根底には MVCC アルゴリズムの正当性が示されていないといけません.つまり,このアルゴリズムに則って多版スケジューラが出力する多版スケジュールでトランザクションを同時実行することによってデータベースの一貫性が損なわれることはない,ということの証明が必要ということです.この証明の道筋は,多版スケジュールを単一版(single version, 1V)スケジュールに変換して(単一版とは版が 1 つしかないということだから,従来型のスケジュールということで,従って,従来型の同時実行制御の考え方が適用できる),その直列化可能性から多版スケジュールの正当性を示すのですが,この証明はいささか複雑すぎます.どうしてもそれを知りたいという読者は,文献[4]の第 5 章で与えられていますので,それに当たってください.ここでは,これ以上立ち入らず,MVCC アルゴリズムは正しいという結果を述べるに留めたいと思います.
3. SI と SSI
3.1 SI の提案
さて,1995 年に “A Critique of ANSI SQL Isolation Levels” と題した論文[5]が発表されました.この論文は,題目の通りANSI(American National Standards Institute,米国国家規格協会)が制定した SQL のトランザクションの隔離性水準の不備を指摘するとともに,「直列化可能ではないものの,
ANSI SQL が指摘した現象,つまり汚読(dirty read),反復不可能な読み(unrepeatable read),幽霊(phantom)が発生しない多版同時実行メカニズム」を定義して,それをスナップショット隔離性(Snapshot Isolation,SI)と名付けました.そこでは,SI は MVMM(multiversion mixed method)の拡張であると紹介され,SI は ANSI の定義した READ COMMITTED よりは強く,
REPEATABLE READ とは強弱が言えないことが述べられています.また,直列化可能ではないことの理由として書込みスキュー異状(write skew anomaly)の発生を挙げています.
SI は MVTO や MV2PL などと違ってトランザクションの同時実行の正しさ,つまりトランザクションの直列化可能性を保証するプロトコルではなく,書込みスキュー異状に加えて読取り専用トランザクション異状(read-only transaction anomaly)[8]の発生も許してしまうのですが,その特性はシドニー大学(University of Sydney)の研究者により深く研究されその性質や実装法が明らかにされました[8, 9, 10].Fekete ら[9]は SI の下で TPC-C ベンチマークが異状を発生することなく実行可能であったことを実験的に示して,直列化可能性を保証できない SI ではあるが,ほとんどのトランザクションを問題なく同時実行できるのではないかということを強調しました.Cahill ら[10]は SI を直列化可能とする SSI(serializable snapshot isolation,直列化可能 SI)のアルゴリズムとその実装,ならびにその性能については様々なケースで 2PL より大幅に改善し,往々にして SI と同程度であったと報告しています.ただ,SSI では,現実的な実装法の制約から,本来は直列化可能なスケジュールなのにその実行が棄却されてしまうという擬陽性(false positive)が発生することは避けられないことには注意が必要です.これらの現象については,以下でより詳しく例題を挙げて説明します.
現在,SI は PostgreSQL,Oracle Database,MS SQL Server などで実装されています.SI は汚読,反復不可能な読み,幽霊を引き起こさないので,それを実装すれば SQL の隔離性水準である SERIALIZABLE を実現していることになります.Oracle Database はそれでもって SERIALIZABLE を実現,と謳っているのですが,2PL に基づいた SERIALIZABLE の実現と違って SI では書込みスキュー異状や読取り専用トランザクション異状が発生するので,トランザクションの同時実行制御の理論が謳うところの真の意味での(あるいは完全な)直列化可能性を達成しているわけではないわけで,
SERIALIZABLE と謳うのはいかがなものかと,この点で物議を醸してきたことは本稿の読者であればどこかで耳にしていることでしょう.一方,PostgreSQL では REPEATABLE READ を SI で,
SERIALIZABLE を SSI で,READ COMMITTED は SI を緩める,つまり,各読み毎にスナップショット(snapshot)を取り直す,ことで実装しています(READ UNCOMMITTED は実装されていなく,その隔離性水準を指定すると default の READ COMMITTED となります).この詳細は Ports と Grittner [12]により報告されています.したがって,PostgreSQL では Oracle Database のような物議は醸しませんが,前述のように SERIALIZABLE では擬陽性が発生することがあるので,それに注意する必要があります.
3.2 SI
さて,SI の定義を見てみることから始めましょう.
【定義 1】(SI)
SI の下で実行されるトランザクション T1 は,それが開始された論理時刻,これを開始時刻印(start-timestamp)と呼ぶ,の時点で有効なコミット済みデータからなるスナップショットから常にデータを読み取る.T1 の開始後にアクティブな他のトランザクションの更新は T1 には見えない.T1 がコミットの準備ができると,コミット時刻印(commit-timestamp)が割り当てられ,他の同時トランザクション T2(つまり,アクティブ期間 [開始時刻印, コミット時刻印] が T1 の期間と重複するトランザクション)がすでに T1 が書き込むことを意図しているデータに書込みをしていない場合にコミットが許可される.これは,遺失更新(lost update)を阻止するためで,First-Committer-Wins ルールと呼ばれる.
実際には,ほとんどの実装では,更新された行に排他ロックが使用されるため,First-Committer-Wins の代わりに,First-Updater-Wins ルールが適用されています.共に,同時実行されている 2 つのトランザクションが同じデータ項目を更新することはできないというためのルールで,その差異は重要ではありません.これは遺失更新異状が発生しないことを意味しているわけです.同様に,トランザクション T のすべての読みは T が開始する前にコミットしたトランザクションの結果を見るので,不完全なトランザクションの影響がなく,これは SI では汚読の異状が発生しないことを意味します.
SI の定義と補足説明でほぼ明らかかと思われますが,トランザクションはその開始時点でのスナップショットを読み続けるので,汚読,反復不可能な読み,幽霊は発生のしようがなく,その結果として SI は SQL の規定している隔離性水準 SERIALIZABLE でのトランザクションの同時実行を保証してくれます.
しかしながら,トランザクションの同時実行制御の理論が謳うところの「真」の意味での直列化可能性(serializability)は満たしていないわけです.なぜならば,SI では書込みスキュー異状や読取り専用トランザクション異状が発生してしまうからです.このことを例題で説明しましょう.
【書込みスキュー異状】(write skew anomaly)
たとえば,データ項目 x,y の初期状態を,x0=50, y0=50 とします.また,データベースには一貫性制約が課せられていて,それは x+y≧0 であったとします.
このとき,SI のもとでトランザクション T1 と T2 が同時実行され,そのスケジュールが図 3 に示されたようであったとします.論理時間は縦軸の上から下の方へ流れていっているとします.T1 の読んだ x と y の初期値 x0 と y0 はそれぞれ 50 で,両者を足して 100 となります.このとき,T1が xを -20
に書換えて x1=-20 としても(つまり,x0-70 を実行したということ),y0=50 なので,x1+y0=30
となり一貫性制約には抵触しなく,T2 はまだコミットしていないので,First Committer Wins ルールでコミットできます(それを c1 で表しています).一方,T1 と同時実行されている T2 は x0 と y0 を読み,y2=-30 と y を更新したとします.この更新も一貫性制約に抵触しないので許されます.さらに,T2 は y を更新したのであって,x を更新したのではないので,First Committer Wins ルールによりコミットできます(これを c2 で表しています).
さて,T1 と T2 の同時実行により,データベースの状態はどのようになったでしょうか?データ項目 x の値は -20 となりました.一方,データ項目yの値は -30 となりました.両方を足すと,x+y の値は -50 になり,これはデータベースの一貫性制約 x+y≧0 に抵触していることになります.この問題は First-Committer-Wins ルールの適用時には検出されませんでした.なぜならば,2 つの異なるデータ項目は,それぞれが他方の状態が変化することなく元のままであることを前提として更新されているためです.それが,「ずれた書込み」(write skew)と名付けられた所以です.なお,図中,rw は rw-dependency (rw-従属性)の存在を示しています(rw-従属性の説明は 3.3 節).

図 3 書込みスキュー異状が発生するトランザクションの同時実行例
【読取り専用トランザクション異状】(read-only transaction anomaly)
3 つのトランザクション間に生起する異状で,そのうちの 2 つは更新トランザクションですが,1 つは読取り専用トランザクションで,この読取り専用トランザクションで発生する異状です.そこで,T1, T2 を更新トランザクション, T3 を読取り専用トランザクションとし,それらが SI の下で,図 4 に示されたように同時実行されたとします.
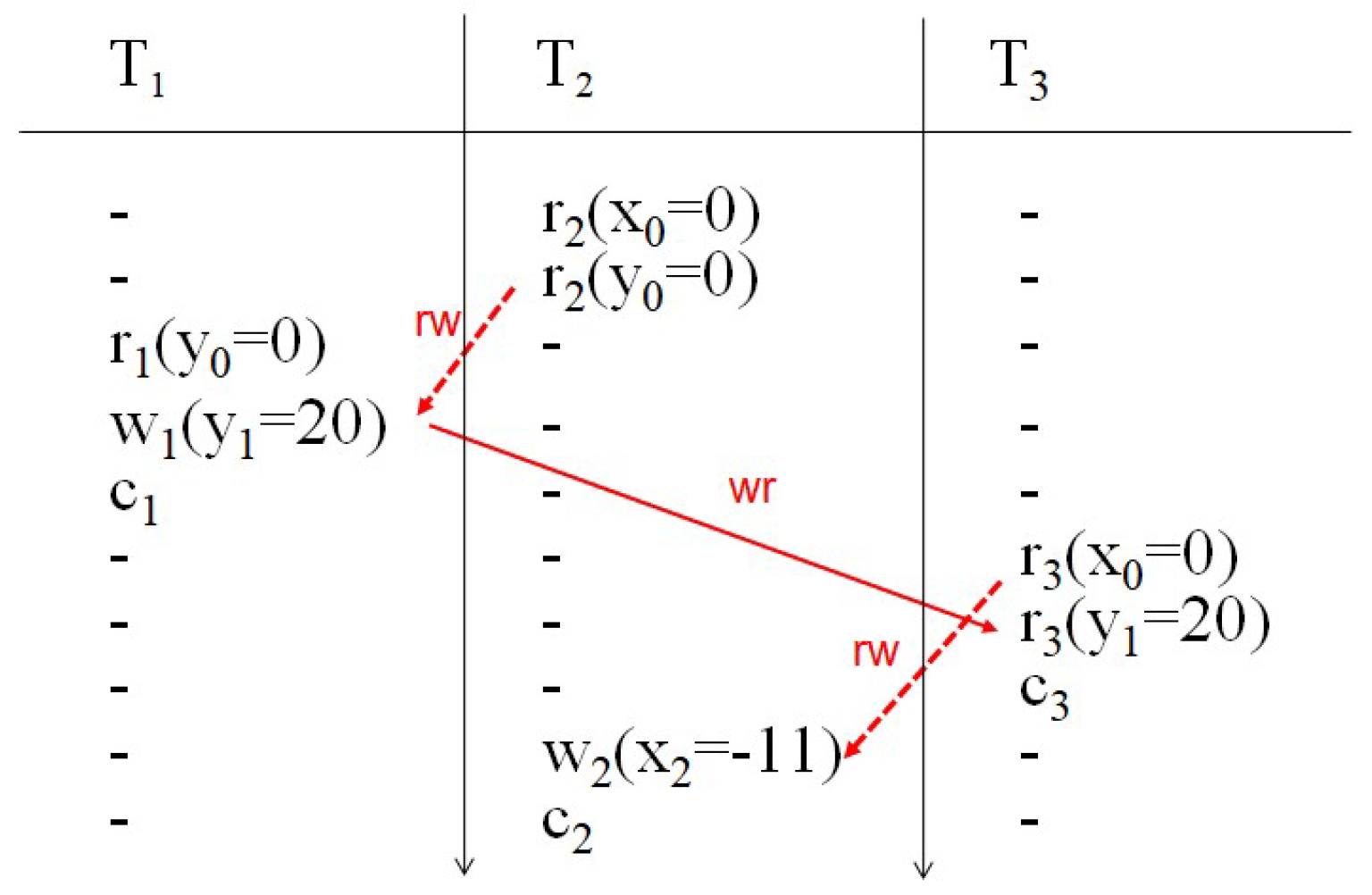
図 4 読込み専用トランザクション異状が発生するトランザクションの同時実行例
First-Committer-Wins ルールに従い,T1 は y1=20 として問題なくコミットします(c1).同様に T2 は x2=-11 として問題なくコミットします(c2).T3 は読取り専用トランザクションなので,問題なくコミットします(c3).
さて,このトランザクションの同時実行に問題はなかったのでしょうか?いや,実は,大きな問題があるのです.T3 が返すデータ項目 x,y の値はそれぞれ 0 と 20 です.しかし,x=0, y=20 という結果は,T1, T2, T3 をどのように直列実行しても得られる結果ではなく,意味不明です.このことについて付加的な説明を加えると,トランザクションが同時実行されたときに,その結果が正しいとはトランザクション群のある直列実行が存在して,その時に得られる結果になる,ということです.実際,T1, T2, T3 の直列実行の仕方は3! (=6) 通りありますが,それらが返す x と y の値は次の通りです.ここで,例えば,T1→T2→T3 はトランザクションが T1,T2,T3 の順に直列実行されたことを表します.
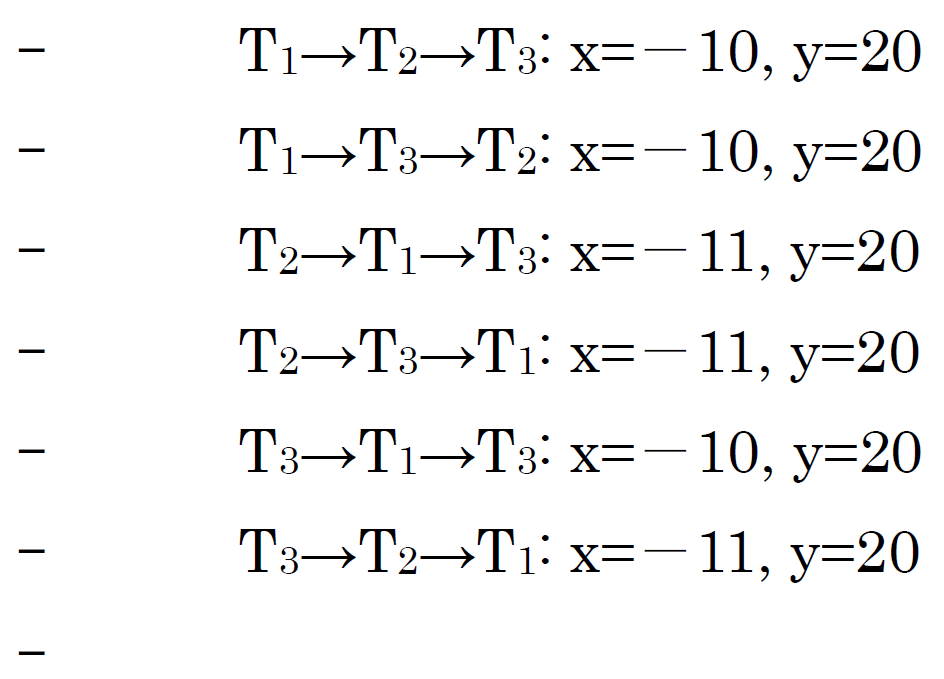
つまり,図 4 に示した T3 は x=0, y=20 を返したのですが,これは T1, T2, T3 のどのような直列実行の結果ともなっておらず,おかしいというわけです.T3 の返した結果は一体何だったのでしょうか?
なお,図中,wr は wr-dependency (wr-従属性)の存在を示しています(wr-従属性の説明は 3.3 節).
3.3 SII
書込みスキュー異状や読込み専用トランザクション異状が発生するので,SI では真の意味での直列化可能性を保証できないということで,「SI を真の意味での直列化可能にする」ための研究が行われ,直列化可能スナップショット隔離性(serializable snapshot isolation,SSI)が Fekete ら[9]によって提案されました.まず,その定義を見てみたいと思いますが,鍵となる概念は SI の下でのデータ項目への書きや読みの間に観察される rw-従属性(rw-dependency)です.このような従属関係を基に直列化グラフ(serialization graph)を作成すると,SI の下で実行されるトランザクションの直列化可能性を規定することができ,SSI を定義できます.このことを,シドニー大学の研究者の論文 [8, 9, 10]を参考にして,少し詳しく見ていきましょう.
まず,一般に,MVCC や SI といった多版同時実行制御のもとで生成される多版スケジュールの直列化可能性は,多版直列化グラフ(multiversion serialization graph, MVSG)を用いて説明することができます.First-Committer-Wins ルールが,x の版を生成する 2 つのトランザクションの間では,一方が開始する前に他方がコミットしていることを保証している SI の下では,データ項目 x の版はそれらの版を作成したトランザクションの時系列に従って順序付けられるので,それに基づき MVSG を次のように定義できます.つまり,MVSG では,次の状況 (i)~(iii) のときに,あるコミット済みトランザクション T1 から別のコミット済みトランザクション T2 にエッジ(edge,辺)を設定します.
(i)
| T1 は x の版を生成し,T2 は x の新しい版を生成している(ww-従属性). |
(ii)
| T1 は x の版を生成し,T2 はこの(またはそれ以降の)版の x を読み取っている(wr-従属性). |
(iii)
| T1 は x の版を読取り,T2 は x の新しい版を生成している(rw-従属性). |
図 5 に図 3 に示した書込みスキュー異状が生じたトランザクション T1 と T2 の同時実行の MVSG を示します.rw-従属性が点線の矢印で示されています.
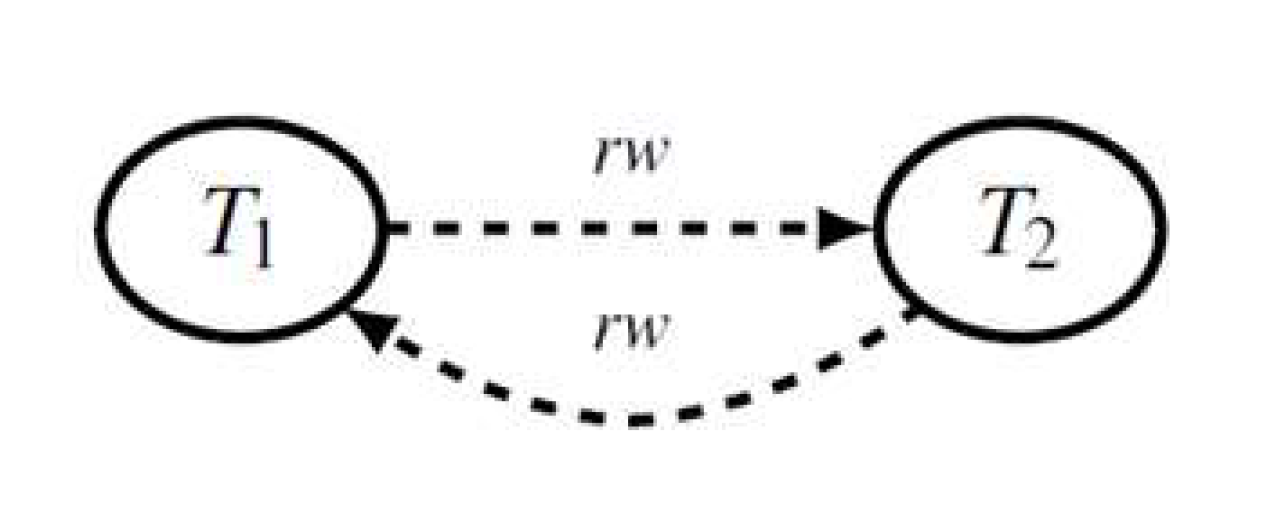
図 5 書込みスキュー異状(図 3)のMVSG
さて,トランザクション理論で知られているように[4],一般に MVSG にサイクルがないことは,トランザクションの同時実行が直列化可能であることを保証します.したがって,同時実行制御に SI を使用するシステムでどのような種類の MVSG が発生する可能性があるかを理解することが重要になります.
このことについて,Fekete ら[9, 10]は,「どのサイクルにも隣接して発生する 2 つの rw-従属性エッジがあり,さらに,これらのエッジのそれぞれが 2 つの同時実行されているトランザクションの間にあること」を示しました.そこで,同時実行されているトランザクション間の rw-従属性を脆弱なエッジ(vulnerable edge)と呼ぶことにし,サイクル内で 2 つの連続した脆弱なエッジが発生する状況を危険な構造(dangerous structure)と呼ぶことにします.これを図 6 に示します.2 つの連続する脆弱なエッジの接合部のトランザクションをピボット(pivot)トランザクションと呼びます.図 6 では T1 がピボットです.そのうえで,SI のもとで直列化可能とならない同時実行の MVSG には必ずピボットがあることを示しました.
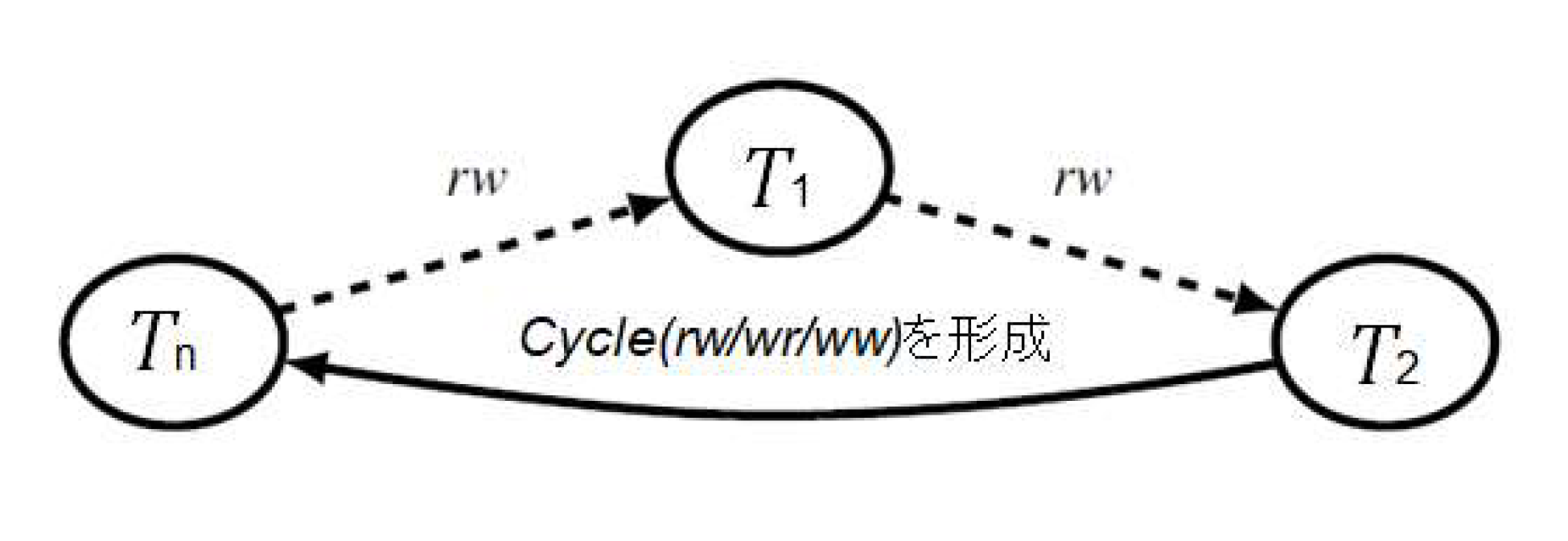
図 6 MVSG における「危険な構造」の一般化
■ SI で書込みスキュー異状が発生することの説明
図 3 を使って説明します.図 3 では rw-従属性を 2 つ確認できます.一つは T2 がデータ項目 x を読んだ後に T1 がデータ項目 x を更新しています.もう一つは,T1 がデータ項目 y を読んだ後に T2 がデータ項目 y を更新しています.では,これらのことは SI というトランザクションの同時実行環境下ではどういう意味を持つのでしょうか?
まず,前者の場合ですが,SI の定義を思い出してください,次のようになります.「T2 は,それが開始された時点で有効なコミット済みデータからなるスナップショットから常にデータを読み取る.T2 の開始後にアクティブな他のトランザクションの更新は,T2 には見えない」ということです.これは何を意味するのでしょうか?明らかです.T1 が T2 より先に実行され T1 が開始される以前にコミットされては困る,ということを表しています.(First-Committer-Wins ルールの場合.もし,First-Updater-Wins ルールの場合は,T1 が開始される以前にデータ項目 x を更新されては困る,となります)つまり,このことを回避するには,T2 の実行を T1 に先行させればよいわけです.このことを rw-従属性 T2 ⇢ T1 で表したわけです.データ項目 y に関する後者の場合も同様で,rw-従属性 T1 ⇢ T2 が得られます.この 2 つの rw-従属性から図 5 に示した書込みスキュー異状の MVSG が得られたわけです.明らかに,このグラフには「危険な構造」があります.したがって,T1 と T2 のこのスケジュールでの同時実行は直列化可能ではなかったことが分かります.
■ SI で読取り専用トランザクション異状が発生することの説明
図 4 で示した読取り専用トランザクション異状の同時実行から MVSG を作成すると図 7 のようになります.明らかにこのグラフには「危険な構造」があります.したがって,図 4 に示した同時実行のスケジュールは直列化可能でないことが分かります.
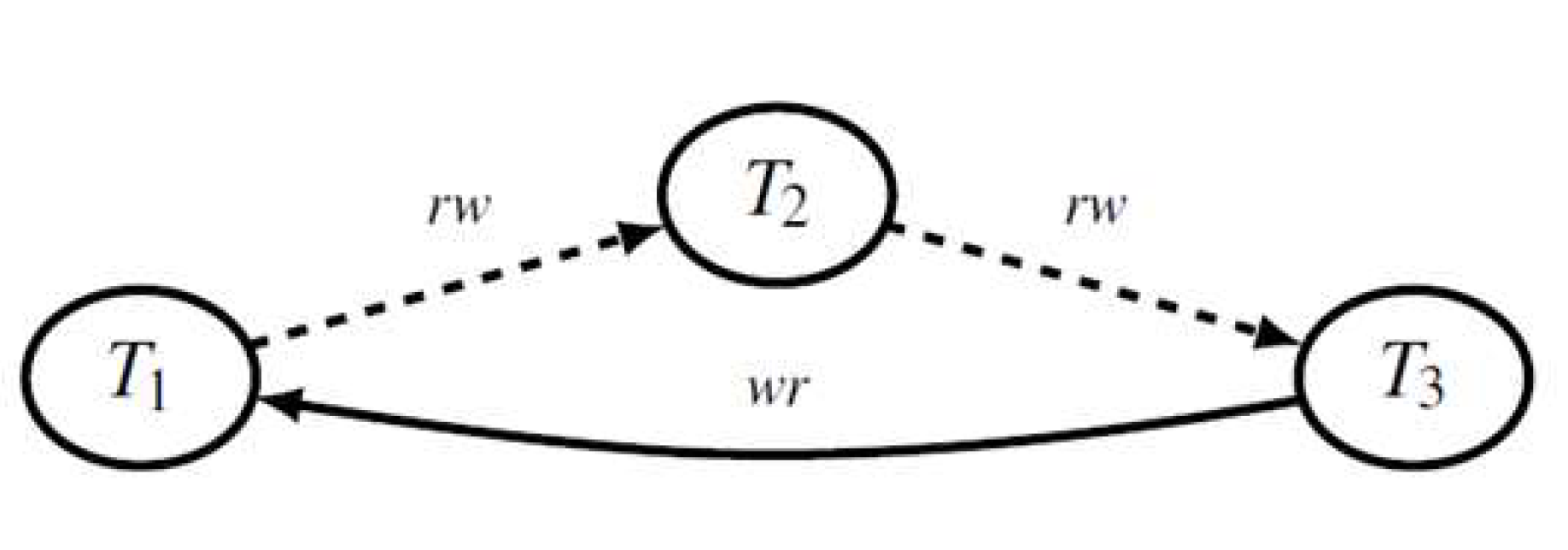
図 7 読取り専用トランザクション異状(図 4)の MVSG
さて,ここまで議論すると,SI の下で直列化可能を実現するための考え方は,ほぼ明らかになったと言えます.トランザクションを同時実行していく過程で MVSG を作り,そこに「危険な構造」を見つけたら,それを解消するために何らかのトランザクションをアボート(abort)すればよいわけです.しかしながら,危険な構造は「サイクル内で 2 つの連続した脆弱なエッジが発生する状況」であったのですが,そのためには同時実行されているすべてのトランザクションの実行を監視してそれら間の rw/wr/ww-従属性からサイクルが発生していないかを見つけなければなりません.Cahill ら[10]はそのコストは尋常ではないと考え,サイクルが形成されているかどうかは無視して,2 つの連続した脆弱なエッジが発生する状況を検知することだけにしました.その代償として,SSI では擬陽性(false positive)が発生してしまうのです.
【定義 2】(SSI)
SI の下で実行されるトランザクションの同時実行において,「2 つの連続した脆弱なエッジが発生する状況」を検知した場合は,直列化可能ではないと判定する.そうでなければ,SI の下で,直列化可能なトランザクションの同時実行が保証される.
この定義に基づく SSI の実装は,まず,T を同時実行しているトランザクションとして,2 つのブールフラッグ(boolean flag)T.inConflict と T.outConflict を定義します.T.inConflict は同時実行されている何らかのトランザクションから T に rw-従属性があるか否かを示します.一方,T.outConflict はTから同時実行している何らかのトランザクションに rw-従属性があるか否かを示します.さらに,これらの情報を繋いで「2 つの連続した脆弱なエッジが発生する状況」を検知するために,通常の WRITE ロックとこのために特別に用意した SIREAD ロックを導入して行います.詳細に興味のある読者は Cahill らの論文[10]にあたってください.
【擬陽性】
擬陽性を呈するトランザクションの同時実行例を図 8 に示します.
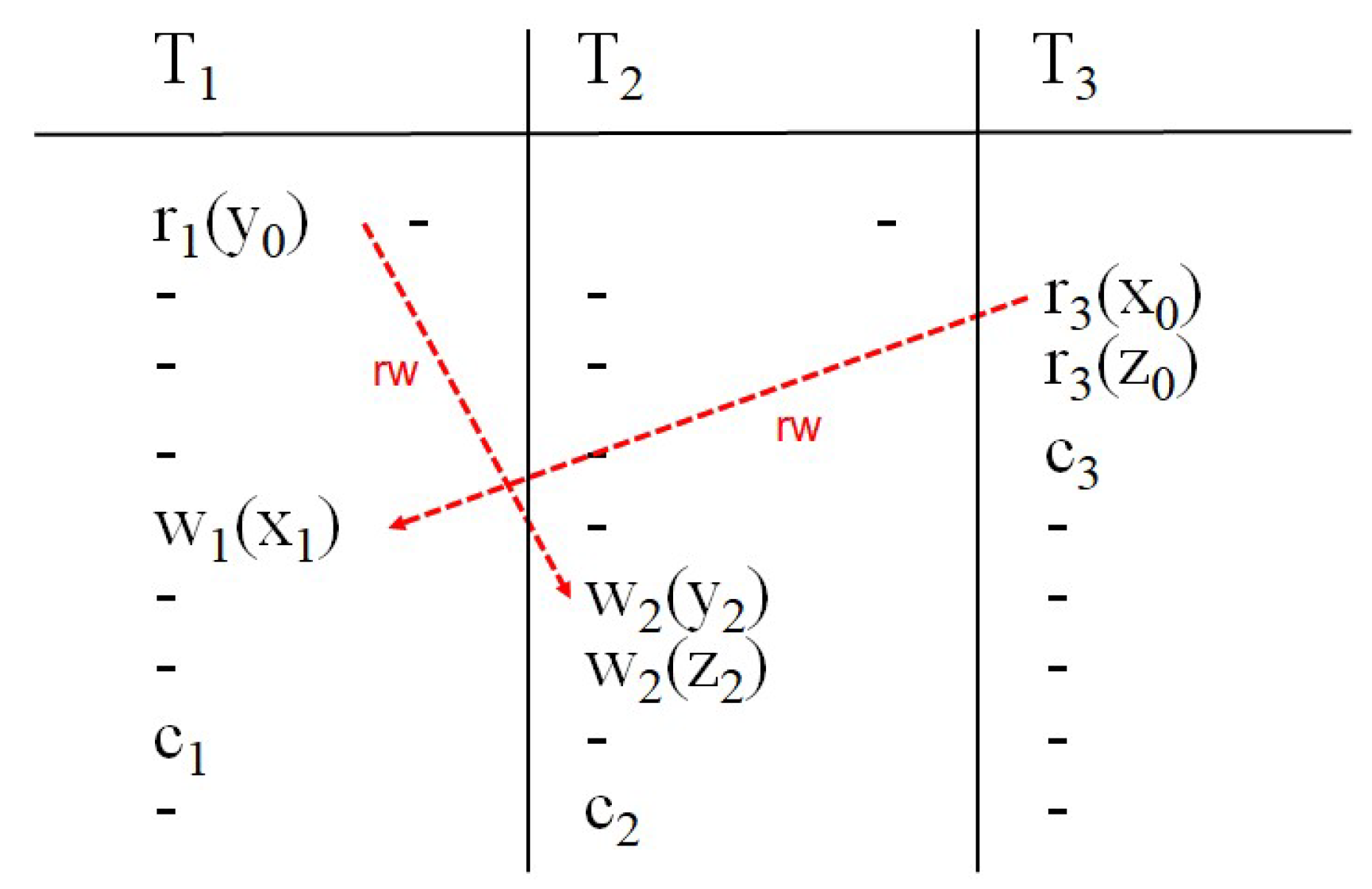
図 8 擬陽性が発生するトランザクションの同時実行例
ちなみに,図 8 で示されたトランザクションの同時実行の MVSG を描くと図 9 に示すとおりです.明らかに,そこには「危険な構造」があります.したがって,トランザクションの直列化可能性を損なう恐れがあるということで,ピボットの T1 あるいは T2 でも T3 でも構いませんが,いずれかのトランザクションをアボートすることを SSI スケジューラは行うということです.
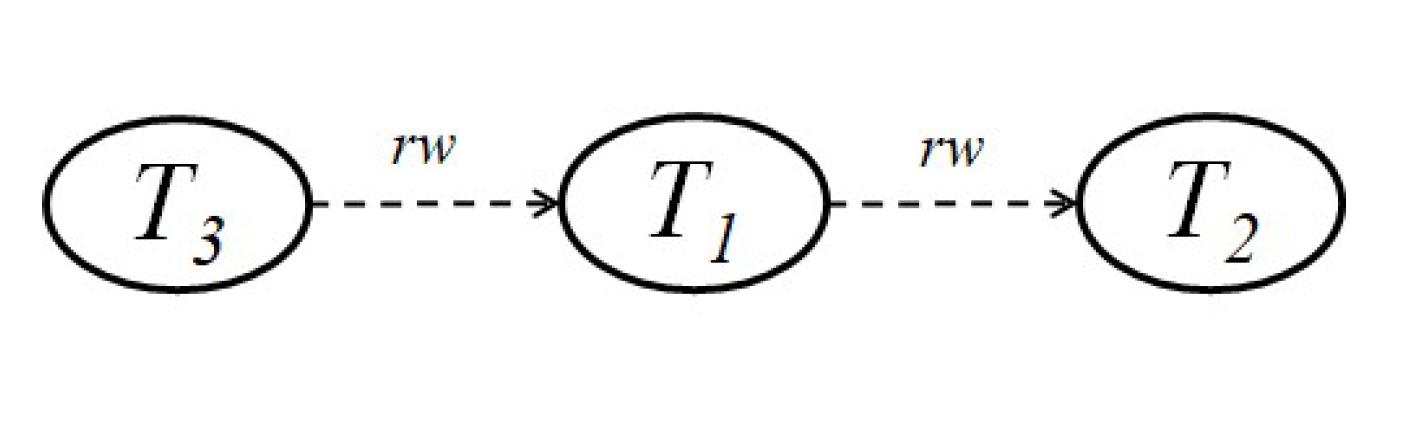
図 9 擬陽性が発生するトランザクションの同時実行例(図 8)の MVSG
では,何が,問題だったのでしょうか?この原因は明らかです.図 6 に示したように,本来は危険な構造をその一部とする rw/wr/ww-従属性の「サイクル」が存在するときに初めて直列化可能ではないと言えるのですが,SSI ではサイクル検出には膨大なコストが掛かることを懸念して,「危険な構造」ではなく「2 つの連続した脆弱なエッジが発生する状況」を検出したら,それだけで直列化可能ではないと判定してしまったということです.ただ,これに関しては,擬陽性はめったに起こらないと釈明しています[10].
4. おわりに
MVCC とは多版の概念を持ち込むことによりトランザクションの同時実行性の向上を目指した技術です.本稿では,MVCC の原型であるMVTO にまず焦点を当てて,2PL では同時実行できないトランザクションが MVCC では同時実行できることを示して,その考え方の基本を示しました.続いて,MVCC の考え方に則った SI に焦点を当てて,その考え方と,それが SQL の隔離性水準である SERIALIZABLE を実現するが,書込みスキュー異状や読取り専用トランザクション異状が発生し,理論的な意味での真の直列化可能性を実現するものではないことに言及しました.SI は真の直列化可能性を実現できる SSI に進化しましたが,SSI の現実的な実装では擬陽性という異状が発生してしまう可能性のあることも紹介しました.SI 並びに SSI の性能評価については先に紹介した通り,SI の下で TPC-C ベンチマークが異状を発生することなく実行可能であること,SSI の性能は様々なケースで 2PL より大幅に改善し,往々にして SI と同程度であったとの報告があることを紹介しました.
PostgreSQL では隔離性水準を REPETABLE READ に設定すると SI が,SERIALIZABLE に設定すると SSI が駆動するように実装されています.また,PostgreSQL 14.1 Documentation(Chapter 13. Concurrency Control. 13.1 Introduction)[13] には次のような記載があります(アンダーラインは筆者による).“Table- and row-level locking facilities are also available in PostgreSQL for applications which don’t generally need full transaction isolation and prefer to explicitly manage particular points of conflict. However, proper use of MVCC will generally provide better performance than locks.”このように,PostgreSQL はロック法ではなく MVCC の使用を推奨しているようです.
このような状況ですが,隔離性水準を READ COMMITTED に設定して(このレベルでは lost update,すなわち ww-conflict が発生することがある),表レベル及び行レベルのロック機能を使って特定の競合ポイントを明示的に管理することで,ちゃんとアプリケーション開発を行っている事例のあることは筆者の耳にするところです.ベンチマークテストの結果はもちろん参考になるとは思いますが,2PL vs. MVCC の議論の要は,データベースアプリケーション開発の現場で発生するトランザクション群の同時実行制御にどちらが適しているのか,雰囲気や時代に流されるのではなく,それを見極める「力」が現場に求められているということではないでしょうか.
【文献】
[1]
| D.P. Reed. Naming and Synchronization in a Decentralized Computer System. MIT-LCS-TR-205, September, 1978. |
[2]
| P.A. Bernstein and N. Goodman. Concurrency Control in Distributed Database Systems. ACM Computing Surveys, Vol.13, No.2, pp.185-221, 1981. |
[3]
| P.A. Bernstein and N. Goodman. Multiversion concurrency control—theory and algorithms. ACM Transactions on Database Systems, Vol.8, No.4, pp.65-483, 1983. |
[4]
| P.A. Bernstein, V. Hadzilacos and N. Goodman. Concurrency Control and Recovery in Database Systems (Book). Addison-Wesley Publishing Company, 1987. |
[5]
| H. Berenson, P. Bernstein, J. Gray, J. Melton, E. O’Neil and P. O’Neil. A Critique of ANSI SQL Isolation Levels. Proceedings of the ACM SIGMOD International Symposium on Management of Data, pp.1-10, 1995. |
[6]
| Per-Åke Larson, Spyros Blanas, Cristian Diaconu, Craig Freedman, Jignesh M. Patel and Mike Zwilling. High-Performance Concurrency Control Mechanisms for Main-Memory Databases. Proceedings of the VLDB Endowment, Vol. 5, No. 4, 298-309, 2012. |
[7]
| H.-T. Kung and J.T. Robinson. On Optimistic Methods Concurrency Control. ACM Transactions on Database Systems, Vol.6, No.2, pp.213–226, 1981. |
[8]
| A. Fekete, E. O’Neil and P. O’Neil. A Read-Only Transaction Anomaly Under Snapshot Isolation. ACM SIGMOD Record, Vol. 33, No. 3, pp.12–13, 2004. |
[9]
| A. Fekete, D. Liarokapis, E. O’Neil, P. O’Neil and D. Shasha. Making Snapshot Isolation Serializable. ACM Transactions on Database Systems, Vol. 30, No. 2, pp.492–528, 2005. |
[10]
| M.J. Cahill, U. Roehm and A. Fekete. Serializable Isolation for Snapshot Databases. Proceedings of the ACM SIGMOD International Symposium on Management of Data, pp.729-738, 2008. |
[11]
| 増永良文.リレーショナルデータベース入門[第3版].サイエンス社,2017年. |
[12]
| D.R.K. Ports and K. Grittner. Serializable Snapshot Isolation in PostgreSQL. Proceedings of the International Conference on Very Large Data Bases, pp.1850-1861, 2012. |
[13]
|
PostgreSQL 14.1 Documentation. https://www.postgresql.org/docs/14/index.html |