本記事では、コンテナ管理ツールのKubernetes上でPostgreSQLのHAクラスタを構築できるZalando Postgres Operatorについて解説します。
Zalando Postgres Operatorとは
Zalando Postgres Operator (以下 Postgres Operator)は、コンテナの管理ツールであるKubernetes上でHA構成のPostgreSQLクラスタを容易に構築できるようにするoperatorです(operatorはKubernetesの機能を拡張するプラグインのような機構です)。本ソフトウェアはドイツのファッション系eコマース企業であるZalando SEによって開発され、自社のサービスで運用されています。本ソフトウェアはMITライセンスの元公開されています。
Operatorについて
OperatorはKubernetes上で動作するアプリケーションの各種管理を自動化するための機能です。従来システム管理者が手動で行っていた、監視、障害時の対応、バックアップ、スケーリングといった様々な操作をプログラムとして記述し、Kubernetesに組み込むことでKubernetesの動作を拡張できます。
また、PostgreSQLに新たなoperatorが必要となるもう一つの要因として、PostgreSQLクラスタはプライマリとレプリカ(スタンバイ)の役割を考慮する必要があり、ステートレスなアプリケーション(例:Webサーバ)のように簡単にレプリカ(複製)を複数台用意することができないことが挙げられます。
Postgres Operatorの機能
Postgres Operatorによりストリーミングレプリケーションを用いたプライマリ1台、レプリカ(スタンバイ)複数台のPostgreSQLクラスタを簡単に構築することができます。
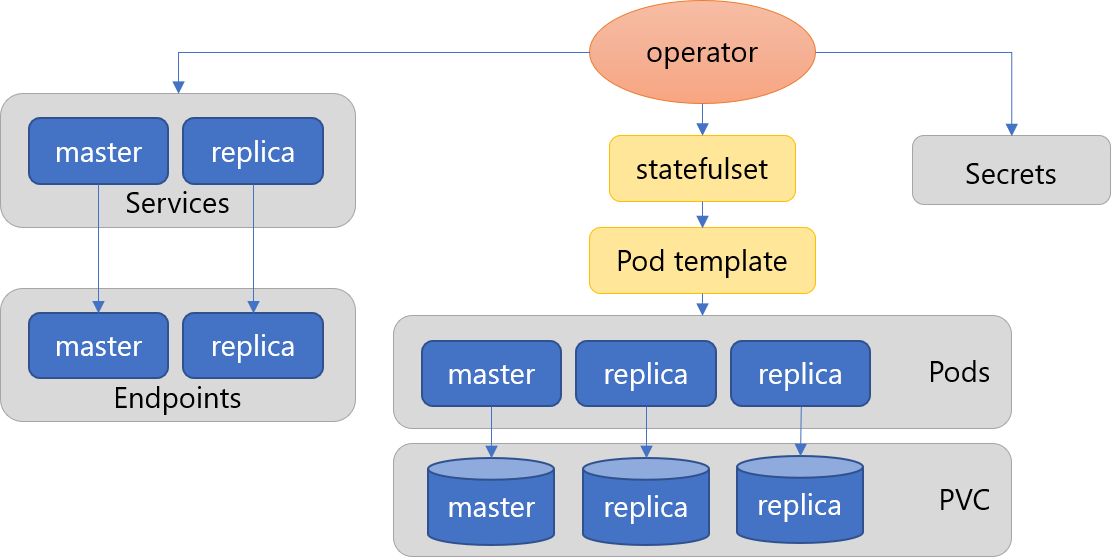
Postgres Operatorの主な機能は以下になります。
- PostgreSQL HAクラスタの管理
- ストリーミングレプリケーション (同期・非同期)
- コネクションプール (PgBouncer使用)
- フェイルオーバー (pg_rewindにより高速な復旧が可能)
- ローリングアップデート
- 論理バックアップ (S3使用)
- WALアーカイブ・PITR (WAL-E、S3使用)
Zalando社による講演
PGCon 2020カンファレンスイベントにてZalando社により行われた講演の資料が公開されています。こちらもあわせて参照ください。
PostgreSQL on K8s at Zalando: Two years in production
検証環境
本記事ではKubernetesのマネージドサービスであるAmazon EKS上でZalando Postgres Operatorを動作させます。
本記事では以下の構成で解説を行います。
- Kubernetes: Amazon EKS (Kubernetesのマネージドサービス)
- ワーカーノード: t3.medium 2ノード
- アーカイブ用ストレージ: Amazon S3
- 作業環境: CentOS 8.1 (VirtualBox上のVM)
なお、EKSクラスタの作成は既に完了しているものとします。EKSの使用方法についてはこちらを参照ください。
検証内容
今回はPostgres Operatorの以下の項目について確認しました。
- Postgres Operator のデプロイ
- Web UI
- PostgreSQL クラスタの作成
- PostgreSQLの動作確認
- フェイルオーバー
- スケーリング
- ローリングアップグレード
- 論理バックアップ
- WALアーカイブ・PITR
- ログ
Postgres Operatorのデプロイ
Postgres OperatorはKubernetesとしては基本的な構成のため、導入は比較的簡単です。
Githubのリポジトリを作業環境にcloneします(もしくはtarballを展開します)。
$ git clone https://github.com/zalando/postgres-operator.git $ cd postgres-operator/
グローバルな設定はconfigmap.yamlファイルに記述されているので、必要に応じて修正します。
ここではバックアップ先のS3の設定などのグローバルな設定を記述します。
kubectl create -fで各YAMLファイルを適用していきます。
$ kubectl create -f configmap.yaml $ kubectl create -f operator-service-account-rbac.yaml $ kubectl create -f postgres-operator.yaml $ kubectl create -f api-service.yaml
オブジェクトが作成され、正常に動作していることを確認します。
$ kubectl get all NAME READY STATUS RESTARTS AGE pod/postgres-operator-85978df8cf-zqwjd 1/1 Running 0 48s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 168m service/postgres-operator ClusterIP 10.100.197.174 <none> 8080/TCP 22s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/postgres-operator 1/1 1 1 48s NAME DESIRED CURRENT READY AGE replicaset.apps/postgres-operator-85978df8cf 1 1 1 49s
Web UI
Postgres OperatorにはWeb UIが同梱されており、ブラウザから以下の操作が可能です。
- クラスタの作成・削除
- 複製
- 設定編集
- 状態確認
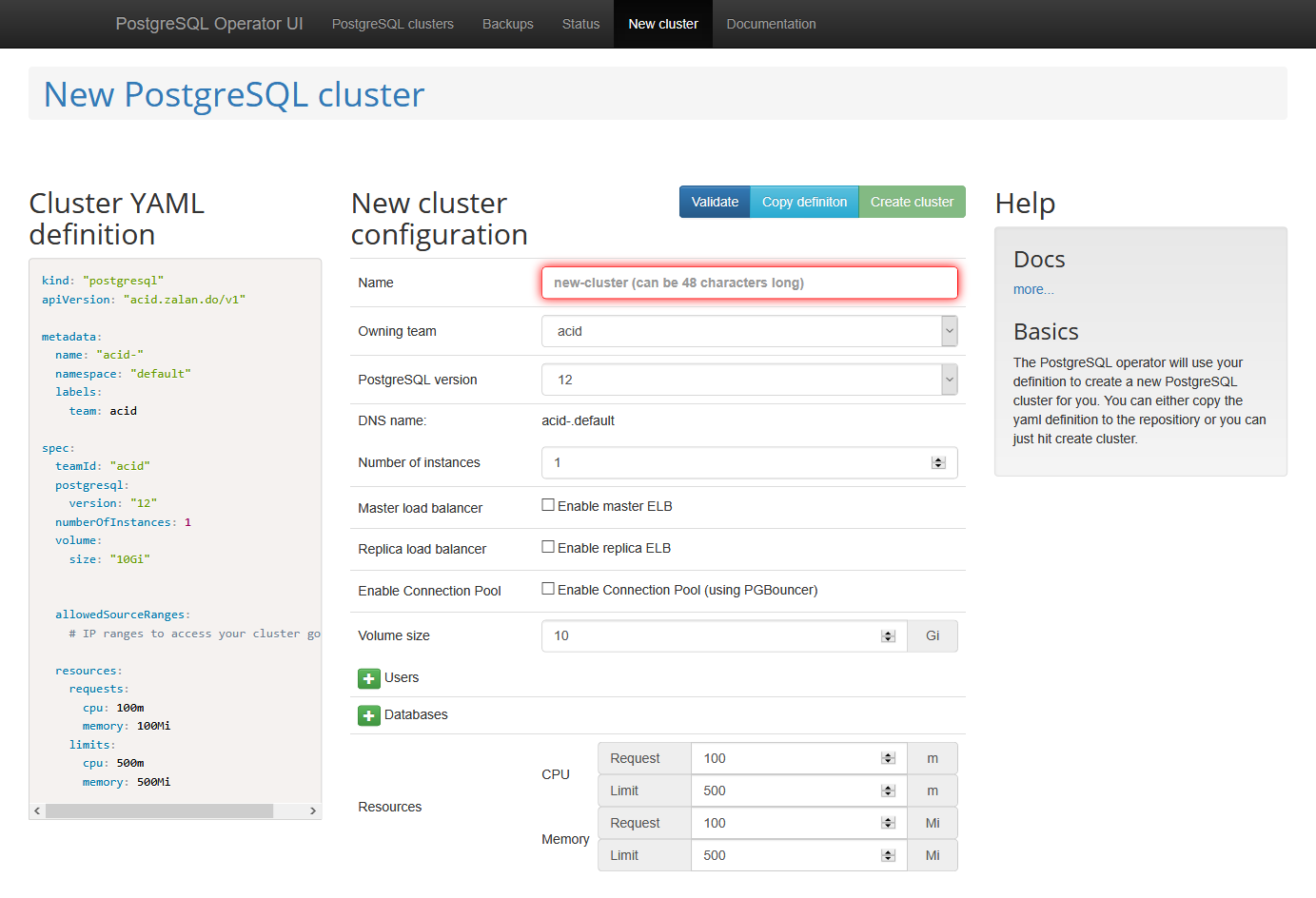
Web UIのデプロイは同様にkubectlを使用して行います。
$ kubectl create -f ui/manifests/
Postgresクラスタの作成
PostgresクラスタのデプロイはYAMLファイルを作成して適用するか、前述のWeb UIで作成操作を行います。
サンプルのYAMLファイルが同梱されていますので、それを元に設定ファイルを作成します。
- minimal-postgres-manifest.yaml: 最小限の設定
- complete-postgres-manifest.yaml: 各種設定を網羅
- standby-manifest.yaml: スタンバイ専用クラスタ設定
基本的な設定を含む設定ファイルは以下になります。
apiVersion: "acid.zalan.do/v1"
kind: postgresql
metadata:
name: sraoss-minimal-cluster # クラスタ名の指定
spec:
teamId: "sraoss"
volume:
size: 1Gi # ボリュームサイズの指定
numberOfInstances: 2 # インスタンス数(マスター+レプリカ)の指定
users: # DBユーザーの作成
zalando: # database owner
- superuser
- createdb
foo_user: [] # role for application foo
databases: # データベースの作成
foo: zalando # dbname: owner
preparedDatabases:
bar: {}
postgresql:
version: "12" # PostgreSQLバージョンの指定(9.6~12)
enableLogicalBackup: true # 論理バックアップの有効化
logicalBackupSchedule: "30 00 * * * *" # cron形式のバックアップスケジュール
enableConnectionPooler: true # コネクションプールの有効化
connectionPooler:
numberOfInstances: 2
これに加え、PostgreSQLのpostgresql.conf、pg_hba.confに相当する追加の設定を行うこともできます。
...
postgresql:
version: "12“
parameters: # postgresql.conf内のパラメータの指定
shared_buffers: "64MB"
max_connections: "50"
log_statement: "all“
patroni:
initdb: # initdb時のパラメータの指定
encoding: "UTF8"
locale: "ja_JP.UTF-8"
data-checksums: "true"
pg_hba: # pg_hba.conf内のパラメータの指定
- hostssl all all 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
同様にkubectlで適用します。
$ kubectl create -f test-postgres-manifest.yaml
クラスタの状態を確認します。numberOfInstances: 2の場合は2つのPodが作成されます。各Podがmasterかreplicaかはspilo-roleラベルで確認できます。
$ kubectl get postgresql NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS sraoss-minimal-cluster sraoss 12 2 1Gi 113s Running $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-minimal-cluster-0 1/1 Running 0 2m19s master sraoss-minimal-cluster-1 1/1 Running 0 95s replica
PostgreSQLの動作確認
Kubernetesクラスタ内の他のPodからは上記のmasterおよびreplicaにアクセスすることができます。
作業環境からpsqlでアクセスしたい場合はkubectlのport-forward機能を利用します。
※ PGMASTERにはmasterのPod名が入ります。
$ export PGMASTER=$(kubectl get pods -o jsonpath={.items..metadata.name} -l application=spilo,cluster-name=sraoss-minimal-cluster,spilo-role=master)
$ kubectl port-forward $PGMASTER 6432:5432
別端末からlocalhost:6432に接続します。なお、接続時にはSSLが必須となります。
※ パスワードはPostgresクラスタ作成時に自動生成されます。
$ kubectl get secret postgres.sraoss-minimal-cluster.credentials -o 'jsonpath={.data.password}' | base64 -d
(パスワード文字列が表示される)
$ export PGSSLMODE=require
$ psql -U postgres -h localhost -p 6432
ユーザ postgres のパスワード:(上記パスワード文字列)
postgres=# create table t (t text); postgres=# insert into t values ('hoge'); postgres=# select * from t; t ------ hoge (1 行)
フェイルオーバー
masterのPodに故障が発生した場合は、自動的にフェイルオーバーしてreplicaがmasterに昇格します。これはPostgres Operatorが使用している、SpiloというPostgreSQLおよびHAを実現するためのテンプレート(Patroni)を含むDockerイメージにより実現しています。
master Podを削除した場合は元replicaがmasterに昇格し、削除したPodが再作成されてreplicaとして復帰します。データサイズが少ない状態ではあるものの、フェイルオーバーは数10秒程度ですばやく完了します。
$ kubectl delete pod sraoss-minimal-cluster-0 pod "sraoss-minimal-cluster-0" deleted $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-minimal-cluster-0 0/1 ContainerCreating 0 6s sraoss-minimal-cluster-1 1/1 Running 0 12m master $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-minimal-cluster-0 1/1 Running 0 23s replica sraoss-minimal-cluster-1 1/1 Running 0 12m master
masterのプロセス故障が発生した場合は元replicaがmasterに昇格し、元masterはPodを維持したままプロセスを再起動しreplicaに降格します。以下の例ではmaster Pod内に入り、initプロセスを停止させて疑似的にプロセス故障を起こしています。
$ kubectl exec sraoss-minimal-cluster-0 -it /bin/sh # kill 1
スケーリング
デプロイ済みのPostgresクラスタの設定を変更すると、変更内容に応じてクラスタの状態を自動的に追従させます。
クラスタのPodの数を指定するnumberOfInstancesを2から3に変更すると、Statefulsetsのレプリカ数も2から3に変更され、新しいreplica Podが起動します。
$ kubectl edit postgresql
spec:
numberOfInstances: 2 -> 3 に修正
$ kubectl get postgresql
NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS
sraoss-minimal-cluster sraoss 12 3 1Gi 53m Running
$ kubectl get statefulsets
NAME READY AGE
sraoss-minimal-cluster 3/3 14m
$ kubectl get po -l application=spilo -L spilo-role
NAME READY STATUS RESTARTS AGE SPILO-ROLE
sraoss-minimal-cluster-0 1/1 Running 0 50m master
sraoss-minimal-cluster-1 1/1 Running 0 50m replica
sraoss-minimal-cluster-2 1/1 Running 0 7m21s replica
ローリングアップデート
PostgreSQLのマイナーバージョンアップ(Dockerイメージの更新)、およびPostgreSQLの設定変更はローリングアップデートによりサービスの停止なしに行うことができます。なお、メジャーバージョンアップはローリングアップデートでは行えないため、ベースバックアップからクラスタの複製により行う必要があります。
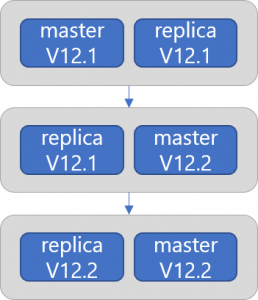
以下、Dockerイメージを更新した場合にローリングアップデートが行われる様子を実際に確認してみます。
Dockerイメージの更新
$ kubectl edit postgresql sraoss-test-cluster
dockerImage: (旧Dockerイメージ) -> (新Dockerイメージ)
postgresql:
version: "12"
ローリングアップデート開始
$ kubectl get postgresql NAME TEAM VERSION PODS VOLUME CPU-REQUEST MEMORY-REQUEST AGE STATUS sraoss-test-cluster sraoss 12 2 1Gi 9m19s Updating $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 1/1 Running 0 9m24s master sraoss-test-cluster-1 1/1 Terminating 0 8m42s $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 1/1 Running 0 9m34s master sraoss-test-cluster-1 0/1 ContainerCreating 0 8s
元replica Podが再作成され、masterに昇格
$ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 1/1 Running 0 9m39s sraoss-test-cluster-1 1/1 Running 0 13s promoted
元master Podの再作成
$ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 1/1 Terminating 0 9m49s sraoss-test-cluster-1 1/1 Running 0 23s master $ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 0/1 ContainerCreating 0 4s sraoss-test-cluster-1 1/1 Running 0 30s master
元master Podがreplicaとして復帰
$ kubectl get pods -l application=spilo -L spilo-role NAME READY STATUS RESTARTS AGE SPILO-ROLE sraoss-test-cluster-0 1/1 Running 0 14s replica sraoss-test-cluster-1 1/1 Running 0 40s master
論理バックアップ
Postgres Operatorでは定期的にAmazon S3に論理バックアップ(pg_dumpall)を取ることができます。なお、論理バックアップからの自動リストア機能はないので、リストアはクラスタ作成後手動で行う必要があります。
前述のconfigmap.yamlでバックアップ先のS3の設定を行います。
logical_backup_s3_bucket: "zalando-backup" logical_backup_s3_access_key_id: "xxxxxxxxxxxxxxxx" logical_backup_s3_secret_access_key: "xxxxxxxxxxxxxxxx
Postgresクラスタの設定で論理バックアップを有効にします。スケジュールはcron表記で指定します(以下は毎日0:30に実行)。
enableLogicalBackup: true logicalBackupSchedule: “30 00 * * *"
指定時刻にKubernetesのCronJobとしてバックアップが実行されます。
$ kubectl get cronjob NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE logical-backup-sraoss-minimal-cluster 30 00 * * * False 0 6m48s 27m $ kubectl get job NAME COMPLETIONS DURATION AGE logical-backup-sraoss-minimal-cluster-1593418800 1/1 3s 6m46s $ kubectl describe job logical-backup-sraoss-minimal-cluster-1593418800 ... Pods Statuses: 0 Running / 1 Succeeded / 0 Failed
S3の以下の場所にバックアップファイルがアップロードされます。
s3://<bucket-name>/spilo/<cluster-name>/<UUID>/logical_backups/<job ID>.sql.gz
WALアーカイブ・PITR
前述のconfigmap.yamlでバックアップ先のS3の設定を行います。なお、EKSクラスタからS3 bucketへのアクセスが許可されている必要があります。
wal_s3_bucket: "zalando-wal-backup"
S3の以下の場所にWALがアーカイブされます。
s3://<bucket-name>/spilo/<cluster-name>/<UUID>/wal/basebackups_00x/ s3://<bucket-name>/spilo/<cluster-name>/<UUID>/wal/wal_00x/
S3のバックアップからクラスタを複製(clone)することでPITRが可能です。PITRの復元位置を指定することもできます。
spec:
clone:
uid: "efd12e58-5786-11e8-b5a7-06148230260c"
cluster: “sraoss-test-cluster"
timestamp: "2017-12-19T12:40:33+01:00"

ログ
Postges Operator自体はログ管理に関する機能を持ちません。Podのsidecarコンテナをユーザが追加することは可能なので、ログ収集のための補助コンテナを導入し、fluentdと連携するなどの作り込みは必要となります。また、Kubernetesクラスタのログを集約するKubernetes Log WatcherというツールがZalando社によって公開されています。
クラスタの各Podのログはkubectl logsコマンドにより確認できます。
$ kubectl logs sraoss-minimal-cluster-0
また、Pod内のPostgreSQLログは以下のように格納されています。
/home/postgres/pgdata/pgroot/pg_log/ -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-0.csv -rw-r--r-- 1 postgres postgres 277783 Jun 29 06:58 postgresql-1.csv -rw-r--r-- 1 postgres postgres 205 Jun 29 06:12 postgresql-1.log -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-2.csv -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-3.csv -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-4.csv -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-5.csv -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-6.csv -rw-r--r-- 1 postgres postgres 0 Jun 29 06:12 postgresql-7.csv
おわりに
手動でPostgreSQL HAクラスタを構築するとなるとかなりの手間がかかります。また、Kubernetes上にそれを構築しようとするのはかなり困難です。Zalando Postgres Operatorを用いることで、Kubernetes上のPostgreSQL HAクラスタの構築が非常に容易になります。実際に開発元のサービスで運用されている実績があり、機能的にまだ不十分なところもあるものの、フェイルオーバーなどの重要な機能に関してはしっかりと作り込まれていると感じました。今後の発展が楽しみなソフトウェアといえます。