前回の Crunchy PostgreSQL Operatorの紹介 では、Kubernetes で PostgreSQL を運用するための Operator として Crunchy PostgreSQL Operator を紹介しました。
今回はマルチクラウド Kubernetes 構成に対応した Crunchy PostgreSQL Operator の高可用性とディザスタリカバリ (DR) について紹介します。
マルチクラウド Kubernetes とは
マルチクラウド Kubernetes は特定の地域やクラウドサービスに依存せず、 複数のクラウドにまたがって Kubernetes クラスタをデプロイすることで、アプリケーションの可用性と耐障害性を向上させる構成です。
Kubernetes では Pod レベルもしくはノードレベルの障害を自動復旧させることはできますが、Kubernetes クラスタが所属している地域に災害が起きた場合、またはクラウドサービスが利用不能になった場合には、Kubernetes クラスタ全体がダウンしてしまいます。
マルチクラウド Kubernetes 構成を組むことで、一方の Kubernetes クラスタがダウンしても、別のクラスタでサービスを継続させることで、システムのダウンタイムを最小限に抑え、迅速に障害や災害から復旧することが可能になります。
しかし、複数の Kubernetes クラスタやクラウドをまたいでデータベースを管理し、データの同期を行うのは極めて困難です。Crunchy PostgreSQL Operator を利用することで、クラウド間で自動的にレプリケーションされている複数の PostgreSQL クラスタを容易に構築・運用できます。
マルチクラウド Kubernetes に対応した Crunchy PostgreSQL Operator
Crunchy PostgreSQL Operator は PostgreSQL インスタンスレベルの可用性を実現することもできますが、複数の Kubernetes クラスタにデプロイしている PostgreSQL クラスタを同期させ、クラスタ間でもフェイルオーバーさせることが可能です。さらに、複数の Kubernetes クラスタを物理的に独立した地域やクラウドに分散配置することでディザスタリカバリにも活用できます。
次の図は、Crunchy PostgreSQL Operator を用いたマルチクラウド Kubernetes の構成図になります。2つの独立した Kubernetes クラスタを異なるクラウドサービス、異なるリージョンに配置します。PostgreSQL クラスタをそれぞれの Kubernetes クラスタにデプロイし、アクティブ/スタンバイ構成で冗長化します。
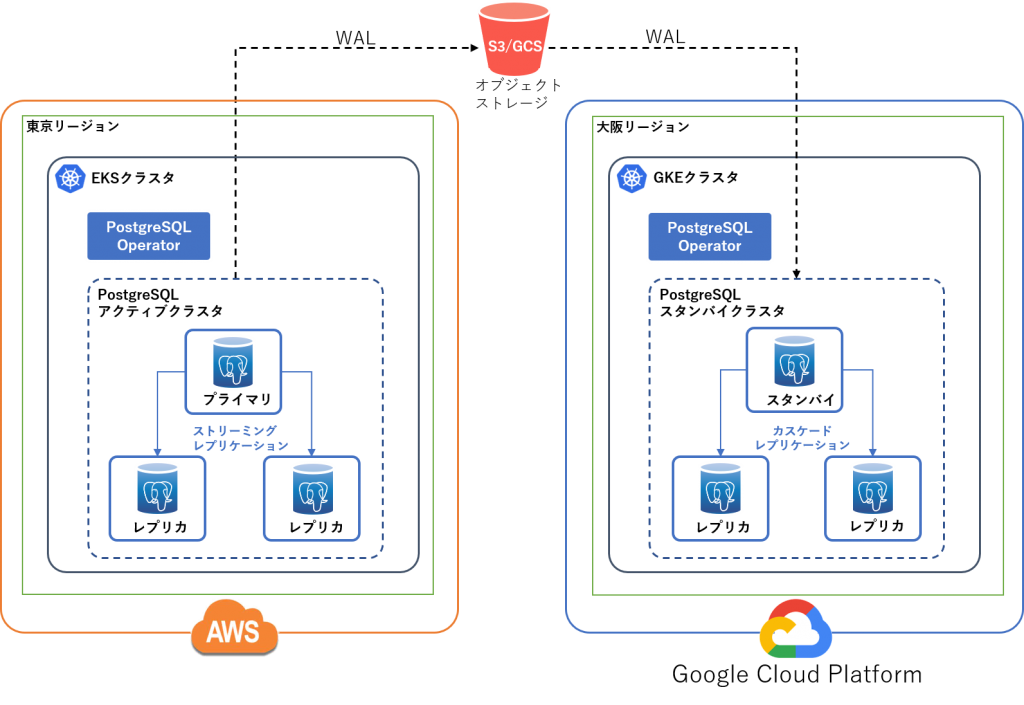
上記の構成図では、例として PostgreSQL アクティブクラスタを AWS に、スタンバイクラスタを GCP にデプロイしていますが、基本的には Crunchy PostgreSQL Operator が対応しているクラウド環境であれば、どの環境でも使用できます。また、オブジェクトストレージとしては S3 (もしくは S3と互換性のあるオブジェクトストレージ) と GCS のどちらでも利用できます。
上記構成の仕組みについて詳しく説明すると、
- PostgreSQL アクティブクラスタが定期的にバックアップと WAL アーカイブをオブジェクトストレージに保存します。
- PostgreSQL スタンバイクラスタが継続的にオブジェクトストレージから WAL を読み込んで、PostgreSQL のアクティブ・スタンバイクラスタ間で同期を行います。
- アクティブクラスタに障害が発生した場合は、手動でスタンバイクラスタをアクティブクラスタに昇格し、サービスを継続させることができます。
- また、ダウンしていた旧アクティブクラスタは手動操作により、スタンバイクラスタとして復旧することも可能です。
検証環境
本記事では、Crunchy PostgreSQL Operator を利用し、AWS と GCP を組み合わせたマルチクラウド環境で動作確認を行いました。検証環境の構成は以下の通りです。
- PostgreSQL アクティブクラスタ
- Kubernetes クラスタ: EKS (AWS が提供するマネージド Kubernetes サービス)
- リージョン: 東京リージョン
- PostgreSQL スタンバイクラスタ
- Kubernetes クラスタ: GKE (Google が提供するマネージド Kubernetes サービス)
- リージョン: 大阪リージョン
- オブジェクトストレージ
- Amazon S3
- リージョン: 東京リージョン
本記事では投稿時点での各ソフトウェアの最新バージョンを用いて以下の項目について動作確認を行いました。
- バージョン情報
- Crunchy PostgreSQL Operator 4.7.0
- PostgreSQL 13.3
- Kubernetes 1.20
- 動作確認項目
- PostgreSQL アクティブクラスタのデプロイ
- PostgreSQL スタンバイクラスタのデプロイ
- クラスタ間レプリケーションの確認
- PostgreSQL スタンバイクラスタの昇格
- 旧 PostgreSQL アクティブクラスタの復旧
なお、動作確認を行う前に、以下項目がすでに完了しているものとします。
PostgreSQL Operator および pgo のインストール・設定
動作確認を行う前に、それぞれの Kubernetes クラスタにおいて、Crunchy PostgreSQL Operator および pgo クライアントコマンドのインストール・設定を行います。クラスタの切り替えは kubectl config use-context <クラスタ名> コマンドを使用します。クラスタの一覧は kubectl config get-contexts コマンドで確認できます。
まず、Amazon EKS クラスタに接続します。
Crunchy PostgreSQL Operator をインストールします。
$ kubectl config use-context <EKSクラスタ名> $ curl -LO https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.0/installers/kubectl/postgres-operator.yml $ kubectl create namespace pgo $ kubectl apply -f postgres-operator.yml
pgo コマンドのインストール・設定を行います。本記事では、ローカル環境から各 Kubernetes クラスタに接続し、各種操作を行いますので、それぞれのクラスタに接続するための情報を $HOME/.pgo/eks と $HOME/.pgo/gke に格納します。
$ curl -LO https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.0/installers/kubectl/client-setup.sh $ chmod +x client-setup.sh $ ./client-setup.sh $ mv $HOME/.pgo/pgo/pgo /usr/local/bin/pgo $ mv $HOME/.pgo/pgo $HOME/.pgo/eks $ cat >> $HOME/env-eks <<EOF export PGOUSER=$HOME/.pgo/eks/pgouser export PGO_CA_CERT=$HOME/.pgo/eks/client.crt export PGO_CLIENT_CERT=$HOME/.pgo/eks/client.crt export PGO_CLIENT_KEY=$HOME/.pgo/eks/client.key export PGO_APISERVER_URL='https://127.0.0.1:8443' export PGO_NAMESPACE=pgo EOF $ source $HOME/env-eks $ kubectl -n pgo port-forward svc/postgres-operator 8443:8443 &
設定完了後、pgo コマンドを実行してみます。バージョン番号が表示されれば、正しく設定できています。
$ pgo version pgo client version 4.7.0 Handling connection for 8443 pgo-apiserver version 4.7.0
次に、GKE クラスタに切り替えて、同様の設定を行います。
$ kubectl config use-context <GKEクラスタ名> $ kubectl create namespace pgo $ kubectl apply -f postgres-operator.yml $ ./client-setup.sh $ mv $HOME/.pgo/pgo $HOME/.pgo/gke
ローカルの 8443 ポートがすでにアクティブクラスタへの接続で使われていますので、スタンバイクラスタへの接続はローカルの 8444 ポートを使用します。
$ cat >> $HOME/env-gke <<EOF export PGOUSER=$HOME/.pgo/gke/pgouser export PGO_CA_CERT=$HOME/.pgo/gke/client.crt export PGO_CLIENT_CERT=$HOME/.pgo/gke/client.crt export PGO_CLIENT_KEY=$HOME/.pgo/gke/client.key export PGO_APISERVER_URL='https://127.0.0.1:8444' export PGO_NAMESPACE=pgo EOF $ source $HOME/env-gke $ kubectl -n pgo port-forward svc/postgres-operator 8444:8443 &
正しく設定されているかを確認します。
$ pgo version pgo client version 4.7.0 Handling connection for 8444 pgo-apiserver version 4.7.0
以上で、PostgreSQL Operator および pgo コマンドのインストール・設定が完了です。
ここからは、Crunchy PostgreSQL Operator を用いたマルチクラウド Kubernetes の動作確認を行います。
PostgreSQL アクティブクラスタのデプロイ
まず、EKS クラスタ上に、PostgreSQL アクティブクラスタをデプロイします。
$ kubectl config use-context <EKSクラスタ名> && source $HOME/env-eks $ pgo create cluster hippo \ --replica-count=2 \ --pgbackrest-storage-type="s3" \ --pgbackrest-s3-bucket="crunchy-pg-backup" \ --pgbackrest-s3-region="ap-northeast-1" \ --pgbackrest-s3-endpoint="s3.ap-northeast-1.amazonaws.com" \ --pgbackrest-s3-key="XXXXXXXX" \ --pgbackrest-s3-key-secret="XXXXXXXXXXXXXXXXXXXXXXXXX" \ --password-superuser="postgres" \ --password-replication="postgres" \ --password="postgres"
それぞれのオプションの意味は以下の通りです。
--replica-count: レプリカの数。2を指定すると、プライマリ1台、レプリカ2台がストリーミングレプリケーションを構成します。--pgbackrest-storage-type: バックアップと WAL アーカイブの保存先。s3 または gcs を指定します。Kubernetes の永続ボリュームにも保存したい場合は、local,s3 または local,gcs を指定します。--pgbackrest-s3-bucket: Amazon S3 の Bucket 名。--pgbackrest-s3-region: Amazon S3 のリージョン。--pgbackrest-s3-endpoint: Amazon S3 のエンドポイント。--pgbackrest-s3-key: アクセスキーID。--pgbackrest-s3-key-secret: シークレットアクセスキー。--password-superuser: postgres スーパーユーザのパスワード。--password-replication: レプリケーション用のユーザのパスワード。--password: クラスタ作成時に作られる一般ユーザのパスワード。
--password-superuser や--password-replication、--password にそれぞれのユーザのパスワードを指定します。指定しない場合はランダムに生成されます。ここでは、検証目的のため、すべてのユーザのパスワードを「postgres」と指定しています。
しばらくしたら、クラスタの状態を確認します。プライマリ、レプリカそれぞれの Pod (Instance) と Serviceが UP 状態になっていれば、正常に起動できています。PostgreSQL アクティブクラスタが定期的に WAL アーカイブを S3 に転送します。
$ pgo test hippo cluster : hippo Services primary (10.100.113.239:5432): UP replica (10.100.57.205:5432): UP Instances primary (hippo-7b8b78bf8f-2pd7c): UP replica (hippo-fmju-7d7586ffcf-mlzxj): UP replica (hippo-hyrz-789c4bb98c-fkgbf): UP
PostgreSQL スタンバイクラスタのデプロイ
次に、GKE クラスタ上に、PostgreSQL スタンバイクラスタをデプロイします。PostgreSQL スタンバイクラスタが継続的に S3 から WAL を読み込み、変更を適用します。
$ kubectl config use-context <GKEクラスタ名> && source $HOME/env-gke $ pgo create cluster hippo-standby \ --standby \ --replica-count=2 \ --pgbackrest-storage-type="s3" \ --pgbackrest-s3-bucket="crunchy-pg-backup" \ --pgbackrest-s3-region="ap-northeast-1" \ --pgbackrest-s3-endpoint="s3.ap-northeast-1.amazonaws.com" \ --pgbackrest-s3-key="XXXXXXXX" \ --pgbackrest-s3-key-secret="XXXXXXXXXXXXXXXXXXXXXXXXX" \ --pgbackrest-repo-path="/backrestrepo/hippo-backrest-shared-repo" \ --password-superuser="postgres" \ --password-replication="postgres" \ --password="postgres"
それぞれのオプションの意味は以下の通りです。
--standby: スタンバイクラスタとして起動します。--replica-count: レプリカの数。2を指定すると、スタンバイ1台、レプリカ2台がカスケードレプリケーションを構成します。--pgbackrest-storage-type: アクティブクラスタのバックアップと WAL アーカイブの保存先。s3 または gcs を指定します。--pgbackrest-s3-bucket: Amazon S3 の Bucket 名。--pgbackrest-s3-region: Amazon S3 のリージョン。--pgbackrest-s3-endpoint: Amazon S3 のエンドポイント。--pgbackrest-s3-key: アクセスキーID。--pgbackrest-s3-key-secret: シークレットアクセスキー。--pgbackrest-repo-path: バックアップや WAL アーカイブを格納するディレクトリのパス。--password-superuser: アクティブクラスタで設定している postgres スーパーユーザのパスワード。--password-replication: アクティブクラスタで設定しているレプリケーション用のユーザのパスワード。--password: アクティブクラスタで設定している一般ユーザのパスワード。
--password-superuser や --password-replication、--password に指定しているパスワードとアクティブクラスタで指定しているパスワードが一致している必要があるので、注意してください。
しばらくしたら、クラスタの状態を確認します。
$ pgo test hippo-standby cluster : hippo-standby Services primary (10.8.7.45:5432): UP replica (10.8.2.146:5432): UP Instances primary (hippo-standby-5848d9d45c-j52n5): UP replica (hippo-standby-eezm-b757c4d98-qt6pr): UP replica (hippo-standby-jgom-5976f8bf8-lb54f): UP
レプリケーションの確認
PostgreSQL アクティブ/スタンバイクラスタのデプロイが完了したら、クラスタ間でレプリケーションが正しく動作するかを確認します。
まず、アクティブクラスタのプライマリに接続し、データの更新を行います。
$ kubectl config use-context <EKSクラスタ名> && source $HOME/env-eks
$ kubectl port-forward svc/hippo 5432:5432 -n pgo &
$ PASSWORD=$(kubectl get secret hippo-postgres-secret -n pgo -o 'jsonpath={.data.password}' | base64 -d)
$ PGPASSWORD=$PASSWORD psql -h 127.0.0.1 -U postgres
postgres=# create table t1 (id int);
postgres=# insert into t1 select generate_series(1,10);
次に、スタンバイクラスタに接続し、データが同期されていることを確認します。
$ kubectl config use-context <GKEクラスタ名> && source $HOME/env-gke
$ kubectl port-forward svc/hippo-standby 5433:5432 -n pgo &
$ PASSWORD=$(kubectl get secret hippo-standby-postgres-secret -n pgo -o 'jsonpath={.data.password}' | base64 -d)
$ PGPASSWORD=$PASSWORD psql -h 127.0.0.1 -U postgres -p 5433
postgres=# select * from t1;
id
----
1
2
3
4
5
6
7
8
9
10
アクティブクラスタで行った更新がスタンバイクラスタに反映されているので、レプリケーションが正しく設定されていることがわかります。
PostgreSQL スタンバイクラスタの昇格
アクティブクラスタに障害が発生した場合、手動でスタンバイクラスタをアクティブクラスタに昇格することが可能です。
ここではアクティブクラスタを停止し、疑似的にクラスタ障害を起こします。
$ kubectl config use-context <EKSクラスタ名> && source $HOME/env-eks $ pgo update cluster hippo --shutdown WARNING: Are you sure? (yes/no): yes Handling connection for 8443 updated pgcluster hippo
スプリットブレイン状態にならないように、アクティブクラスタが完全に停止しているかを確認します。
$ pgo test hippo cluster : hippo Services Instances primary (): DOWN
アクティブクラスタが DOWN という状態になったら、スタンバイクラスタを昇格させます。
$ kubectl config use-context <GKEクラスタ名> && source $HOME/env-gke $ pgo update cluster hippo-standby --promote-standby Disabling standby mode will enable database writes for this cluster. Please ensure the cluster this standby cluster is replicating from has been properly shutdown before proceeding! WARNING: Are you sure? (yes/no): yes Handling connection for 8444 updated pgcluster hippo-standby
上記コマンドを実行すると、スタンバイクラスタがアクティブクラスタに昇格され、書き込みクエリ/読み取りクエリを処理できるようになります。
$ PASSWORD=$(kubectl get secret hippo-standby-postgres-secret -n pgo -o 'jsonpath={.data.password}' | base64 -d)
$ PGPASSWORD=$PASSWORD psql -h 127.0.0.1 -U postgres -p 5433
postgres=# insert into t1 select generate_series(11,20);
INSERT 0 10
スタンバイクラスタ昇格後、新しいタイムラインが生成され、新しいアクティブクラスタが定期的に WAL アーカイブを S3 に転送します。以下のコマンドで WAL アーカイブを格納するディレクトリの中身を確認できます。
$ aws s3 ls --recursive s3://crunchy-pg-backup/backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/ 2021-06-24 15:45:48 1861462 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000001-f8f3f3cf686b527c734c658cd6225294e708d398.gz 2021-06-24 15:46:47 16882 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000002-b354378ca96866d80fb0ce5dde0bc20e5e97811c.gz 2021-06-24 15:47:22 370 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000002.00000028.backup 2021-06-24 15:47:22 16834 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000003-d19c52e43342f0677293844fce0e9763bd4dc0fd.gz 2021-06-24 15:49:21 16936 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000004-e4353d933eee841030b4a644d457645510501e38.gz 2021-06-24 15:51:22 16461 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000005-f3692f7a98b733e2a16db695d03d85ec7e36a76a.gz 2021-06-24 16:23:28 38823 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000006-54001cf223598aaa70dab09817a960c77186712a.gz 2021-06-24 16:26:27 16457 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000100000000/000000010000000000000007-768ad2fa8f6a87db51bf0a7e199341a93f7839d7.gz 2021-06-24 17:13:36 41 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/00000002.history 2021-06-24 17:13:55 16518 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000200000000/000000020000000000000008-edfd6aae39a79700c091d0be5786fb322288f2cc.gz 2021-06-24 17:14:01 16479 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000200000000/000000020000000000000009-d43396f9558ba42ed492f3085d93edf3d995891f.gz 2021-06-24 17:14:02 370 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000200000000/000000020000000000000009.00000028.backup 2021-06-24 17:16:02 18147 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000200000000/00000002000000000000000A-5732b47a4a1a9a7069f567a5e8379104cfe2c32e.gz 2021-06-24 17:19:02 16462 backrestrepo/hippo-backrest-shared-repo/archive/db/13-1/0000000200000000/00000002000000000000000B-298ede92cecd0d1a1dd09852660c1164f9e73b69.gz
旧 PostgreSQL アクティブクラスタの復旧
Kubernetes クラスタが障害から回復したら、ダウンしていた PostgreSQL アクティブクラスタをスタンバイクラスタとして復旧させることも可能です。
以下のコマンドを実行し、PostgreSQL クラスタをスタンバイクラスタとして起動します。以下のコマンドを実行すると、既存の PVC が削除され、再作成されます。永続ボリュームを残したい場合は、利用している StorageClass の reclaimPolicy を Retain に設定してください。
$ kubectl config use-context <EKSクラスタ名> && source $HOME/env-eks $ pgo update cluster hippo --enable-standby Enabling standby mode will result in the deltion of all PVCs for this cluster! Data will only be retained if the proper retention policy is configured for any associated storage classes and/or persistent volumes. Please proceed with caution. WARNING: Are you sure? (yes/no): yes Handling connection for 8443 updated pgcluster hippo
ConfigMap からスタンバイクラスタとして設定されていることを確認できます。
$ kubectl get cm hippo-config -n pgo -o yaml | grep standby
archive-get %f \"%p\""},"use_pg_rewind":true,"use_slots":false},"standby_cluster":{"create_replica_methods":["pgbackrest_standby"],"restore_command":"source
上記設定を確認できたら、スタンバイクラスタを起動します。
$ pgo update cluster hippo --startup WARNING: Are you sure? (yes/no): yes Handling connection for 8443 updated pgcluster hippo
正常に起動していることを確認します。
$ pgo test hippo cluster : hippo Services primary (10.100.113.239:5432): UP replica (10.100.57.205:5432): UP Instances primary (hippo-7b8b78bf8f-kdhk4): UP replica (hippo-fmju-7d7586ffcf-5kxw5): UP replica (hippo-hyrz-789c4bb98c-l2c4w): UP
PVC の状態を確認します。「AGE」から PVC が再作成されていることがわかります。
$ kubectl get pvc -n pgo NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE hippo Bound pvc-51b396c1-7204-45ed-9a03-5542a77dda8f 1Gi RWO gp2 1m40s hippo-fmju Bound pvc-5223e924-abdb-45a9-bd05-cf4c4ecc4dbd 1Gi RWO gp2 1m40s hippo-hyrz Bound pvc-fadc8764-1b7c-4004-8c69-70afe9f5142f 1Gi RWO gp2 1m39s hippo-pgbr-repo Bound pvc-48d60253-4928-4bd3-967a-727d61c71d7d 1Gi RWO gp2 1m39s
マルチクラウド Kubernetes の運用
マルチクラウド Kubernetes 構成では、S3/GCS を介して PostgreSQL アクティブ/スタンバイクラスタがデータの同期を行っていますので、WAL アーカイブが行われる間隔 archive_timeout の設定値が大きすぎると、スタンバイクラスタに適用されるまで大きな遅延が発生する可能性がありますので、運用方針に合わせて設定値を調整してください。Crunchy PostgreSQL Operator のデフォルト値は archive_timeout = 60 となります。
また、すでに運用している単一 Kubernetes クラスタをマルチクラスタ構成に変更することも可能です。S3/GCS にベースバックアップおよびベースバックアップ取得後の WAL アーカイブがあれば、いつでも PostgreSQL スタンバイクラスタを追加できます。
終わりに
今回は、Crunchy PostgreSQL Operator を用いて複数のクラウドサービス、複数のリージョンにまたがって PostgreSQL を冗長化する方法、障害時の復旧、運用の注意点などについて紹介しました。マルチクラウド Kubernetes 構成により、迅速に障害や災害から復旧することが可能になります。PostgreSQL の高可用性や災害対策を検討する際に、マルチクラウド Kubernetes が1つの有効な選択肢になるでしょう。
本記事の執筆時点では、障害発生時に自動的にスタンバイクラスタを昇格させる機能がなく、手動操作によりフェイルオーバーさせる必要がありますが、開発元が積極的に機能追加を行っており、今後の機能拡張が期待できます。