前回の記事Zalando Postgres Operatorの紹介ではKubernetes上でPostgreSQLのHAクラスタを構築するためのOperatorの1つZalando Postgres Operatorについて解説しました。
今回の記事では、前回の記事に続いてCrunchy Postgres Operatorについて解説します。
本記事の説明は Crunchy Postgres Operator 4.7 を対象にします。2021 年にリリースされたバージョン 5 (v5) についてはCrunchy Postgres Operator v5 の紹介を参照してください。
Crunchy Postgres Operatorとは
Crunchy Postgres Operatorは、コンテナの管理ツールであるKubernetes上でPostgreSQL HAクラスタを容易に構築ためのOperatorの1つです(OperatorはKubernetesの機能を拡張するプラグインのような機構です)。Crunchy Postgres OperatorはPostgreSQLの関連サービスを提供しているアメリカの会社であるCrunchy Dataによって開発され、Apache License 2.0で公開されています。PostgreSQL 9.5以降に対応しています。
全体構成図
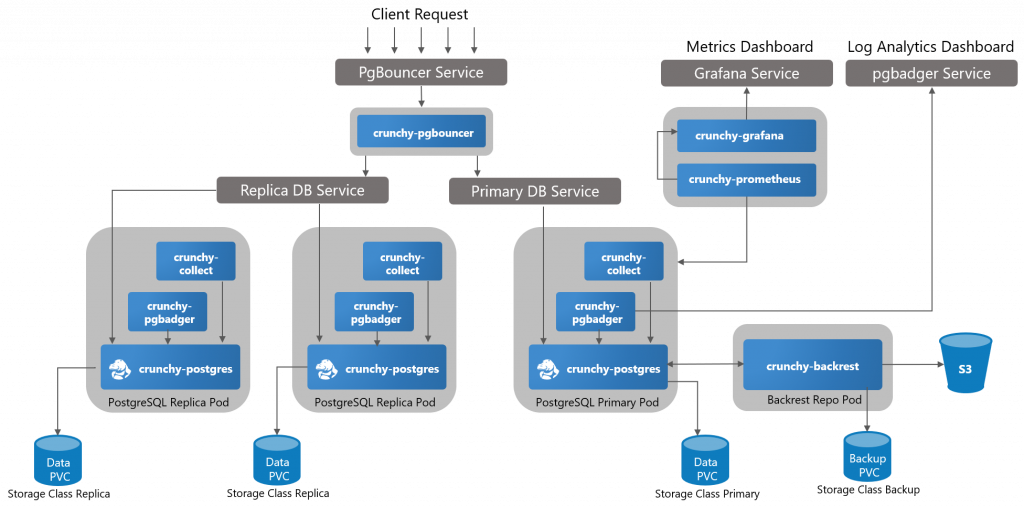
Crunchy Postgres Operatorの機能
Crunchy Postgres Operatorの主な機能は以下の通りです。
- PostgreSQL HAクラスタのデプロイ・管理
- CLI (pgo)
- ストリーミングレプリケーション (同期・非同期)
- フェイルオーバー
- バックアップ (S3対応)
- WALアーカイブ (S3対応)
- リストア・PITR
- 自動アップグレード
- コネクションプール (PgBouncer使用)
- PostgreSQLのログ解析
- 監視
検証環境
本記事ではKubernetesのマネージドサービスであるAmazon EKS上でCrunchy Postgres Operatorの動作確認を行いました。
環境の構成およびバージョン情報は以下の通りです。
- Crunchy Postgres Operator 4.7.0
- Kubernetes: Amazon EKS (Kubernetesのマネージドサービス)
- ワーカーノード: t3.medium 2ノード
- アーカイブ用ストレージ: Amazon S3
- 作業環境: CentOS 7.6 (AWS上のEC2)
なお、EKSクラスタの作成は既に完了しているものとします。EKSの使用方法についてはこちらを参照ください。
検証内容
本記事はCrunchy Postgres Operator 4.7.0を用いて以下の項目について動作確認を行いました。
- Crunchy Postgres Operatorのデプロイ
- pgoクライアントコマンドのインストール
- PostgreSQLクラスタの作成
- psql による接続確認
- PostgreSQLの設定
- フェイルオーバー
- スケーリング
- バックアップ
- リストア・PITR
- アップグレード
Crunchy Postgres Operatorのデプロイ
以下の方法でPostgreSQL Operatorをデプロイできます。
– Ansible
– Bashスクリプト
– pgo-deploy Job (※推奨、v4.3.0 ~)
v4.3.0から追加された「pgo-deploy Job」を用いたデプロイ方法は他の方法より簡単にPostgreSQL Operatorをインストール/アップデート/アンインストールできるため、こちらの方法の利用が推奨されています。
以下では「pgo-deploy Job」を用いたデプロイ方法を紹介します。
1. まず、デプロイの設定を記述したマニフェストを取得します。
$ curl -LO https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.0/installers/kubectl/postgres-operator.yml
2. 環境に合わせて、マニフェストを編集します。
最低限Operatorが利用するストレージの設定が必要になります。指定しない場合は、Amazon EKSデフォルトのストレージクラスを利用します。
デフォルトのストレージクラスが定義されていることを確認します。
$ kubectl get sc NAME PROVISIONER AGE gp2 (default) kubernetes.io/aws-ebs 5h49m
3. デフォルトではOperatorがpgoというNamespaceにインストールされるため、pgoというNamespaceを作成し、マニフェストを適用します。
$ kubectl create namespace pgo $ kubectl apply -f postgres-operator.yml
4. インストール後、PostgreSQL Operatorが正常にインストールされていることを確認します。
$ kubectl get pod -n pgo NAME READY STATUS RESTARTS AGE pgo-deploy-bq9fs 0/1 Completed 0 4m50s postgres-operator-5d5ff486c7-jtdc6 4/4 Running 1 3m52s $ kubectl get svc -n pgo NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE postgres-operator ClusterIP 10.100.180.218 <none> 8443/TCP,4171/TCP,4150/TCP 19m
5. 終了した 「pgo-deploy」Jobを削除するには以下のコマンドを実行します。
$ kubectl delete -f postgres-operator.yml
pgoクライアントコマンドのインストール
1. client-setup.shスクリプトをダウンロード・実行し、pgoクライアントをインストールします。
$ curl -LO https://raw.githubusercontent.com/CrunchyData/postgres-operator/v4.7.0/installers/kubectl/client-setup.sh $ chmod +x client-setup.sh $ ./client-setup.sh
2. 以下の環境変数を設定します。
$ cat >> ~/.bashrc <<EOF export PATH="$HOME/.pgo/pgo:$PATH" export PGOUSER="$HOME/.pgo/pgo/pgouser" export PGO_CA_CERT="$HOME/.pgo/pgo/client.crt" export PGO_CLIENT_CERT="$HOME/.pgo/pgo/client.crt" export PGO_CLIENT_KEY="$HOME/.pgo/pgo/client.key" export PGO_NAMESPACE=pgo EOF $ source ~/.bashrc
3. インストール後、pgoクライアントが正常にインストールされていることを確認します。
postgres-operatorをローカルの8443へポートフォワードを行います。
$ kubectl -n pgo port-forward svc/postgres-operator 8443:8443 &
APIサーバの環境変数をローカルの8443ポートに設定します。
$ cat >> ~/.bashrc <<EOF export PGO_APISERVER_URL="https://127.0.0.1:8443" EOF
clientとAPIサーバのバージョン番号が表示されれば、正しくインストールできています。
$ pgo version pgo client version 4.7.0 Handling connection for 8443 pgo-apiserver version 4.7.0
PostgreSQLクラスタの作成
pgo create clusterコマンドを用いて PostgreSQLクラスタを作成します。
$ pgo create cluster hippo --replica-count=1 --sync-replication
上記コマンドで以下のような構成のクラスタが作成されます。
- primary 1台、replica 1台
- 同期レプリケーション
- 自動フェイルオーバー (デフォルト)
- バックアップ (デフォルト)
- WAL アーカイブ (デフォルト)
- ローカルストレージにバックアップと WALアーカイブを保存 (デフォルト)
postgresスーパーユーザのパスワードを設定したい場合は--password-superuserオプションで設定可能です。指定しない場合は自動生成されます。また、バックアップの保存先やサイドカー機能などのオプションの詳細については、後述する「バックアップ」や「サイドカー機能」を参照ください。
クラスタの状態を確認します。正常に起動できれば、primary、replicaそれぞれのPod (Instance)とServiceがUP状態になっています。
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
primary (hippo-646dfd49f5-lbc8l): UP
replica (hippo-gfps-65f776cc6-mhdcw): UP
psql による接続確認
Kubernetesクラスタ内のノードからは上記primary及びreplicaのServiceに接続することができます。
作業環境からpsqlでprimary及びreplicaのServiceに接続したい場合はkubectlのport-forward機能を利用します。
ここではprimary Serviceの5432ポートをローカルの5432へポートフォワードを行います。
※ PGPRIMARYにはprimaryのService名が入ります。
$ export PGPRIMARY=$(kubectl get svc -o jsonpath={.items..metadata.name} -l name=hippo,pg-cluster=hippo,vendor=crunchydata -n pgo)
$ kubectl -n pgo port-forward svc/$PGPRIMARY 5432:5432 &
psqlで接続します。
接続時にパスワード入力プロンプトが表示されるため、クラスタ作成時に指定したパスワードを入力します。
$ psql -h localhost -U postgres
ユーザ postgres のパスワード:
postgres=# select application_name, state, sync_state from pg_stat_replication;
application_name | state | sync_state
----------------------------+-----------+------------
hippo-gfps-65f776cc6-mhdcw | streaming | sync
(1 行)
クラスタ作成時にパスワードを設定していない場合はランダムに生成されています。生成されたパスワードはkubectl get secretコマンドで確認できます。
$ kubectl get secret hippo-postgres-secret -n pgo -o 'jsonpath={.data.password}' | base64 -d
PostgreSQLの設定
PostgreSQLのpostgresql.confやpg_hba.conf、pg_ident.conf などの設定はConfigMapで設定できます。
事前に作成したConfigMapはクラスタ作成時に--custom-configオプションで適用可能です。
指定しない場合は、クラスタ作成時に<clusterName>-pgha-configというConfigMapが作成されます。
ConfigMap <clusterName>-pgha-configは以下で構成されます。
- Distributed Configuration Store (DCS) : クラスタ全体の設定
- local Database : PostgreSQLサーバごとの設定
kubectl describe configmapコマンドを用いてConfigMapの設定を確認できます。
$ kubectl describe configmap hippo-pgha-config -n pgo
設定を変更するには kubectl edit configmap コマンドを利用します。
例えば、log_statementをnoneからallに変更するには以下のコマンドを実行します。
変更するとOperatorによって変更が検出され、自動的にPostgreSQLに反映されます。
$ kubectl edit configmap hippo-pgha-config -n pgo data: hippo-dcs-config: | postgresql: parameters: ... log_statement: none -> all に変更
ただし、PostgreSQLの再起動が必要になるパラメータもあり、再起動が必要かどうかはpgo restart hippo --queryコマンドで確認できます。
例えば、max_wal_sendersの設定値を変更した場合、PostgreSQLの再起動が必要になります。
$ kubectl edit configmap hippo-pgha-config -n pgo
data:
hippo-dcs-config: |
postgresql:
parameters:
...
max_wal_senders: 6 -> 8 に変更
設定変更後pgo restart hippo --queryを実行し、PENDING RESTARTカラムがtrueになっていれば、再起動が必要なことを意味しています。
$ pgo restart hippo --query Handling connection for 8443 Cluster: hippo INSTANCE ROLE STATUS NODE REPLICATION LAG PENDING RESTART hippo primary running ip-192-168-84-180.us-west-2.compute.internal 0 MB true hippo-gfps replica running ip-192-168-30-254.us-west-2.compute.internal 0 MB true
上記結果より、hippo及びhippo-gfpsの再起動が必要なので、それぞれのPod (Instance)名をpgo restartコマンドの--targetオプションに指定し、再起動します。
$ pgo restart hippo --target hippo $ pgo restart hippo --target hippo-gfps
フェイルオーバー
primaryのPodに故障が発生した場合は、自動的にフェイルオーバーしてreplicaがprimaryに昇格します。これはPostgreSQL HAのテンプレートであるPatroniを利用して実現しています。
Podを削除した場合
primaryのPodを削除した場合、replicaがprimary に昇格し、新たなreplicaが生成され、復旧します。
replicaの生成はpgBackRestのdelta restoreの機能で、迅速に復旧することができます。
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
primary (hippo-646dfd49f5-lbc8l): UP
replica (hippo-gfps-65f776cc6-mhdcw): UP
$ kubectl delete pods hippo-646dfd49f5-lbc8l -n pgo
pod "hippo-646dfd49f5-lbc8l" deleted
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
replica (hippo-646dfd49f5-x7m67): UP
primary (hippo-gfps-65f776cc6-mhdcw): UP
プロセス障害の場合
primaryの Podのプロセス障害が発生した場合は、replicaがprimaryに昇格し、
旧primaryはPodを維持したままreplicaとして再起動します。
以下の例ではPod内に入り、initプロセスを停止させて疑似的にプロセス障害を起こしています。
$ kubectl exec hippo-gfps-65f776cc6-mhdcw -it -n pgo -- /bin/sh
$ kill 1
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
primary (hippo-646dfd49f5-x7m67): UP
replica (hippo-gfps-65f776cc6-mhdcw): UP
スケーリング
PostgreSQLのreplicaのスケーリングンにより、データベースの負荷分散や耐障害性の向上を実現できます。
pgoクライアントコマンドを実行することで、簡単にスケールアップ/スケールダウンが可能です。
スケールアップ
replicaを1台から2台に増やします。
$ pgo scale hippo --replica-count=1
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
primary (hippo-646dfd49f5-x7m67): UP
replica (hippo-gfps-65f776cc6-mhdcw): UP
replica (hippo-zdlq-69dcc59d9-8hn6f): UP
スケールダウン
スケールダウン可能なreplicaを確認します。
$ pgo scaledown hippo --query Handling connection for 8443 Cluster: hippo REPLICA STATUS NODE REPLICATION LAG PENDING RESTART hippo-gfps running ip-192-168-30-254.us-west-2.compute.internal 0 MB false hippo-zdlq running ip-192-168-84-180.us-west-2.compute.internal 0 MB false
replica「hippo-zdlq」を削除します。
$ pgo scaledown hippo --target=hippo-zdlq
$ pgo test hippo
Handling connection for 8443
cluster : hippo
Services
primary (10.100.43.244:5432): UP
replica (10.100.157.106:5432): UP
Instances
primary (hippo-646dfd49f5-x7m67): UP
replica (hippo-gfps-65f776cc6-mhdcw): UP
バックアップ
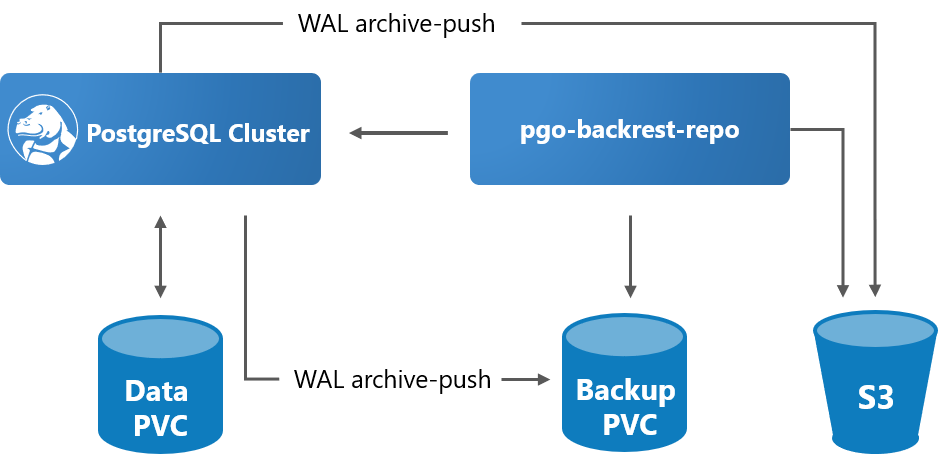
Crunchy Postgres Operatorのバックアップ/リストアは内部的にpgBackRestのバックアップ/リストアユーティリティを利用しています。
定期的にフルバックアップまたは差分バックアップを取得することができます。
取得したバックアップやWALアーカイブはローカルストレージもしくはAmazon S3に保存することができ、保存先の設定はPostgreSQLクラスタ作成時に設定可能です。
バックアップに関するクラスタ作成時のオプションは以下のようなものがあります。
$ pgo create cluster hippo \ --replica-count=1 \ --pgbackrest-storage-type="local,s3" \ --pgbackrest-s3-bucket="crunchy-postgres-backup" \ --pgbackrest-s3-region="us-west-2" \ --pgbackrest-s3-endpoint="s3.us-west-2.amazonaws.com" \ --pgbackrest-s3-key="xxxxxxxxxx" \ --pgbackrest-s3-key-secret="xxxxxxxxxxxxxxxxxxxx" \ --pgbackrest-s3-verify-tls=false
それぞれのオプションの意味は以下の通りです。
--pgbackrest-storage-type: バックアップとWALアーカイブの保存先。”local,s3″を指定した場合は、ローカルストレージとAmazon S3に保存します。デフォルトではローカルストレージに保存します。--pgbackrest-s3-bucket: Amazon S3のBucket名を指定します。--pgbackrest-s3-region: Amazon S3のリージョンを指定します。--pgbackrest-s3-endpoint: Amazon S3のエンドポイントを指定します。--pgbackrest-s3-key: Amazon S3 キーを指定します。--pgbackrest-s3-key-secret: Amazon S3 シークレットキーを指定します。--pgbackrest-s3-verify-tls: pgBackRestがAmazon S3に接続するときにTLS証明書を検証するかどうかを設定します。
定期バックアップを設定するにはpgo create scheduleコマンドを使います。
バックアップのスケジュールはcron表記で指定します。
(毎日午前1時にフルバックアップを実行) $ pgo create schedule hippo --schedule="0 1 * * *" \ --schedule-type=pgbackrest --pgbackrest-backup-type=full
差分バックアップを行いたい場合は、--pgbackrest-backup-type=incrを指定します。
(1時間ごとに差分バックアップを実行) $ pgo create schedule hippo --schedule="0 */1 * * *" \ --schedule-type=pgbackrest --pgbackrest-backup-type=incr
リストア
新しいPostgreSQLクラスタの作成
バックアップから新しいPostgreSQLクラスタを作成するにはpgo create clusterを利用します。
例えば、開発やテスト目的で本番環境と同じ環境を用意するときに、--restore-fromオプションを使用して本番環境の名前を指定するだけです。
pgo create cluster hippo2 --restore-from=hippo
デフォルトでは最新のデータに復元しますが、--restore-optsオプションを使用して、特定の時点まで復元可能です。
pgo create cluster hippo2 \ --restore-from=hippo \ --restore-opts="--type=time --target='2020-07-27 14:50:00.000000+00'"
また、Amazon S3に保存されているバックアップからPostgreSQLクラスタを作成する場合は、
--repo-type=s3を指定します。
pgo create cluster hippo2 --restore-from=hippo --restore-opts="--repo-type=s3"
起動中のPostgreSQLクラスタのPITR
起動中のPostgreSQLクラスタを以前の時点に復元するにはpgo restoreコマンドを使います。
pgo restoreコマンドは既存のデータディレクトリでリカバリを実行しますので、
クラスタが一旦停止され、作り直されます。
$ pgo restore hippo --pitr-target="2020-07-27 14:50:00.000000+00" \ --backup-opts="--type=time"
ログ
Crunchy PostgeSQL Operator自体にはログを収集する機能がありません。Podのsidecarコンテナとしてfluentdを導入し外部に転送するなどの作り込みは必要となります。
以下の方法でPodのログやPostgreSQLのログを確認可能です。
クラスタの各Podのログはkubectl logsコマンドにより確認できます。
kubectl logs hippo-646dfd49f5-x7m67 -c database -n pgo
また、Pod内のPostgreSQLログは以下のように格納されています。
kubectl exec -i -n pgo -t hippo-646dfd49f5-x7m67 -- ls -alt /pgdata/hippo/pg_log -rw------- 1 postgres postgres 588 Jul 1 12:00 postgresql-Wed.log
アップグレード
新しいバージョンにアップグレードするには、以下2段階のアップグレードを実行する必要があります。
- Crunchy Postgres Operator自身のアップグレード
- PostgreSQLクラスタのアップグレード
アップグレードに伴う注意点は以下の通りです。
- Operatorのアップグレード後、PostgreSQLクラスタのアップグレード完了まで既存のPostgreSQLクラスタの操作はできない。
- PostgreSQLクラスタアップグレード時、replica及びreplicaのPVCが削除されるが、primaryとbackrest-repoのPVCがそのまま残り、それぞれの新しいPodに引き継がれる。
- PostgreSQLクラスタのアップグレード中、primary Podが停止し、再作成されるので、PostgreSQLクラスタのダウンタイムが発生する。
Crunchy Postgres Operatorのアップグレード
前述の通り、pgo-deploy Jobにより、PostgreSQL Operatorをアップデートできるので、
新しいバージョンのpostgres-operator.ymlにてDEPLOY_ACTIONをupdateに変更し、適用します。
$ vi postgres-operator.yml ... - name: DEPLOY_ACTION value: "install" -> "update" に変更 $ kubectl apply -f postgres-operator.yml
PostgreSQLクラスタのアップグレード
PostgreSQLクラスタのアップグレードにはpgo upgradeコマンドを使います。
$ pgo upgrade <クラスタ名>
便利な機能
PostgreSQLクラスタ作成時に、オプションを指定することで、コネクションプールやpgbadgerによるPostgreSQLログ解析、Prometheus監視用のメトリクスの出力といった機能が利用できます。
例えば、pgo create clusterでクラスタ作成時に--pgbouncer --metrics --pgbadgerを指定することで、これら機能が有効になります。
$ pgo create cluster hippo \ --replica-count=1 \ --pgbouncer \ --metrics \ --pgbadger
それぞれのオプションの意味は以下の通りです。
--pgbouncer: pgbouncer Pod起動し、コネクションプール機能を有効にする--metrics: Prometheus Exporterコンテナを各それぞれのPostgreSQLのPodに追加し、データベースサーバのパフォーマンスや使用状況、PostgreSQLクラスタの状態などのPrometheusメトリクスを出力する--pgbadger: pgbadgerコンテナをそれぞれのPostgreSQLのPodに追加し、PostgreSQLのログを解析する
おわりに
今回はPostgreSQL Operatorの1つCrunchy Postgres Operatorについて紹介しました。Crunchy Postgres Operatorを用いることで、Kubernetes上のPostgreSQL HAクラスタの構築・管理が非常に容易になります。開発元が新機能の追加や機能改善に力をいれており、PostgreSQLの最新バージョンに対応するスピードも速く、Kubernets上でPostgreSQLクラスタの構築を検討する際に、1つの有力な選択肢だと言えるでしょう。