
はじめに
※本記事は、PGConf India 2025での講演内容を書き下ろしたものです。
プランナは、与えられたSQLに対して最適な実行方法を自動的に選択してくれるデータベースの最も重要なコンポーネントの1つです。ユーザはSQLを通じて何をしたいのかを伝えるだけで、プランナはどういう計算をどのような順序で行うと最適かを考えてくれます。
例えば、次のようなSQLがあるとします:
SELECT e.name, d.name FROM employees e JOIN departments d ON e.department_id = d.id WHERE d.location = 'Japan';
このSQLでは、日本にある部署に所属する従業員の名前と部門名を取得する、といういわば「ほしい結果」を記載しているだけです。一方で、プランナは次のような点を考慮して実行計画を決定します:
- employeesテーブルとdepartmentsテーブルへアクセスするにはどのような方法がとれるか
- 各テーブルおよび出力のデータ量はどの程度あるか
- これらを踏まえて最適なアクセス方法・結合方法はどれか
プランナのおかげでユーザはこのような点を検討する手間から解放されています。また、新たに効率的なプランの実行方法がPostgreSQLに実装されると、それと知らずにその恩恵を受けることができたりもします。
しかしながら、プランナも完璧ではありません。いまいちなプランを作成し、その結果クエリの実行が長時間に及び、真夜中にDBAが呼び出されてしまうこともあります。
本記事では、PostgreSQLの利用経験のある方を対象に、主に商用環境を想定し、プランナと仲良くやっていくためのポイントと、今後PostgreSQL側に求められる機能をご紹介します。
プランナが最適ではない実行計画を選ぶ理由
プランナは通常、最適なプランを選択することを意図して作られていますが、現実には常に最適な判断をするとは限りません。
まずデータ量やデータの分布といった要因によって、最適な実行計画は変動します。
例えば、100万件のレコードを持つテーブルにおいて、特定の条件に合致するレコードが1件のみであればインデックススキャンが効率的ですが、50万件が合致する場合にはシーケンシャルスキャンの方が通常適しています。
プランナは、事前に収集された統計情報に基づいて実行計画を立てますが、この統計情報は手動または自動で収集されます。統計情報収集後に更新処理が実行されれば、取得した統計情報と実際のデータは乖離します。
例えば、テーブルに対して大量の更新や削除が行われた直後・かつ統計情報がまだ更新されていない場合では、プランナは古い情報に基づいて非効率的な計画を選択しがちです。
また、統計情報はあくまでサンプリングであるため、実際のデータとは異なります。また、サンプリングしたデータもいくつかの前提をおいて利用されるため、実体とは乖離することがあります。例えば、WHERE句で複数列をANDで列挙した場合、各列に相関はないものとして見積を行います(注1)が、実際には相関があるケースも少なくないでしょう。
さらに、プランナは複数の実行計画を立ててそのコストが最も小さいものを選択しますが、このコストは、1行処理する際のCPUコスト、シーケンシャルアクセス時のディスクI/Oのコストなど”各処理1単位あたりのコスト”(注2)を決めて、コストを計算します。この各処理1単位あたりのコストが実体と乖離している場合や、コストを計算するモデルが実体と合っていない場合、不適切な実行計画を選択する可能性があがります。
このように様々な理由から、プランナは最善ではないプランを選択することがあります。また、それまでスムーズに実行されていたクエリが突然異なる実行計画を選択してパフォーマンスが悪化したり、開発環境では問題なく動作していたクエリが商用環境で極端に遅くなる、といった問題が発生することがあります。
プランナとうまくやっていくために
以下ではこのような不適切な実行計画によるクエリの実行が長時間化する問題に対して対処するための方法を、3つのステップに分けて概説していきます。(一部提案中の機能も含まれますが、その点は明記しています)。
これらのステップは1回実施したら終わりというものではなく、繰り返し実行します。
(1) 実行計画のモニタリングをする
(2) 長時間化したクエリがなぜ遅いのか分析する
(3) 分析結果に基づいたアクションをとる
実行計画のモニタリングをする
実行済のクエリのモニタリング
まずは長時間化したクエリの実行計画を把握する必要があります。
パラメータlog_min_duration_statementを設定し、一定時間以上かかったクエリをログに出力させ、その後EXPLAINを実行する..という方法をとることもありますが、EXPLAIN実行時と実際に長時間化した時とで、統計情報、OSリソース・並行して動作するプロセス、PostgreSQL/OSのキャッシュなどの状況が異なるため、この方法では問題が再現できないことがあります。
おすすめは、auto_explainの利用です。実行されたクエリの実行計画を自動でログに保存するPostgreSQL同梱のエクステンションですが、ログに記録する条件は、パラメータauto_explain.log_min_durationで実行にかかった時間、パラメータauto_explain.sample_rateで割合を指定できます。
パラメータauto_explain.log_analyzeを指定すれば、EXPLAIN ANALYZE相当の情報も記録されます。この情報があると、プランナが見積もった行数と実際の行数の違いなど、実行計画の問題点を発見するのに有用なことが多いのですが、一方で負荷が増加してしまいます。これはログ出力するクエリだけではなく、すべてのクエリに影響がある点注意が必要です。
負荷増加の主な原因は、実行計画の各ノードで実行するのにかかった時間を計測する点にあるため、パラメータauto_explain.log_timingをoffに設定すれば影響は大幅に緩和できます。ただ、どのノードがボトルネックか判断する上で実行時間はできれば記録しておきたいところです。
この点は、auto_explain.log_analyzeはロール単位で設定できる点を利用することで対処ができるケースが多いです。例えば、OLAP系のクエリを実行する専用のロールを用意し、そのロールにだけauto_explain.log_analyzeを設定します:
ALTER ROLE olap_user SET auto_explain.log_analyze TO on;
逆に、短時間に高頻度で実行されるクエリについては、同様に専用のロールを作成し、前述のauto_explain.sample_rateを設定し、一部のみログ出力するようにします。
実行中のクエリのモニタリング
さて、ここまで見てきたEXPLAIN, auto_explainを使った場合、実行計画が出力されるのはクエリ完了後です。今実行中のクエリが長時間化していてプランを確認したい場合はどうすればよいでしょうか?
このような今まさに実行中の実行計画を確認する方法は、現在のPostgreSQL本体では提供されていません。クエリの完了まで待つ必要があります。
PostgreSQL本体ではなく、エクステンションでこのような機能を提供するものとして、pg_show_plans, pg_query_stateがありますが、前者は性能影響があるとされており、後者はPostgreSQL本体のソースコードの変更が必要です。
この点SRA OSSでは、実行中のクエリのプランを任意のタイミングでログに出力する機能をPostgreSQL本体機能としてコミュニティに提案しています。
長時間化したクエリがなぜ遅いのか分析する
実行計画の分析
実行計画を分析するためには読み方について多少の訓練が必要かと思います。実行計画の読み方について解説しているよい資料は多数あるので、そちらを参考にされるとよいでしょう(注3)。少し古いですが、日本語ではExplaing Explain ~PostgreSQLの実行計画を読む~は一読しておくとよいかと思います。
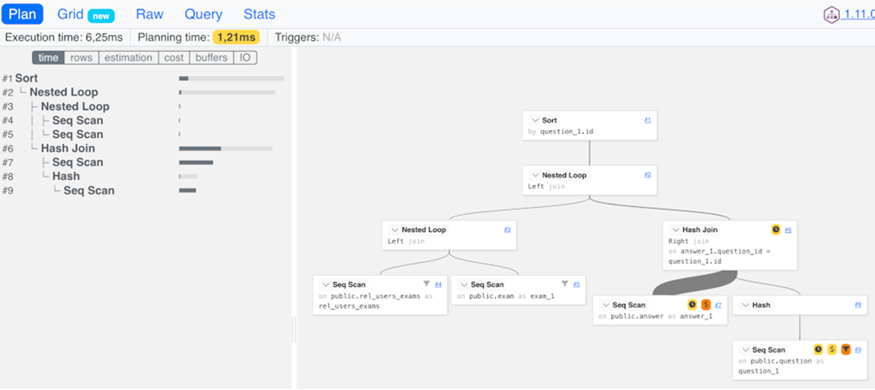
実行計画を可視化するオープンソースソフトウェアのツールも公開されており、活用すると分析が効率的に進められるケースがあります。例えば、pev2を利用すると、以下のように実行計画を可視化できます。インターネット上のサービスは利用せずに、ローカルで利用することも可能です。手順はこちらに記載されています。
実行計画以外の分析
実行計画を分析する際に少し気を付けたいのは、実行計画以外の理由でクエリの実行に時間がかかっている可能性もある点です。たとえば、OSリソース利用状況や問題のクエリを実行しているプロセス以外のPostgreSQLのプロセス、あるいはPostgreSQL以外のプロセスの影響を受けていないかも気にしておくとよいでしょう。
OSリソースの中でも、ストレージへのI/Oは性能問題の要因になりやすいポイント(注4)です。EXPLAINのBUFFERSオプション、auto_explainであればパラメータauto_explain.log_buffersを利用することでPostgreSQLの共有バッファへのヒット状況が確認できるため、この点確認されている方も多いでしょう。
一方で現在これらのオプションを利用しても、共有バッファにヒットしなかった場合にOSのキャッシュにヒットしたのか、それともストレージへのI/Oまで発生したのかはわからない点には注意が必要です。OSのキャッシュにヒットした場合、共有バッファにヒットした場合と大きな差はない性能が得られることが多いですが、ストレージへのI/Oまで発生した場合は通常大きな遅延が発生します。
この点、SRA OSSが提案中の機能の1つに、BUFFERSオプションを利用した場合ストレージへのI/O量も出力するという提案があります。本機能が採用され、auto_explainでも同様の機能が加われば、実行が遅延したクエリについて、ストレージI/Oがどの程度の回数発生していたのかが把握できるようになり、原因の切り分けがより進めやすくなると考えています。
分析結果に基づいたアクションをとる
分析した結果得られた長時間化の原因に基づいて、アクションをとります。
原因や対応の方針・環境によって様々なアクションがとれますが、いくつか列挙し、そのうちいくつかについて注意点などを記載します:
-
- PostgreSQL本体
- 運用
- ANALYZEコマンドを実行し、統計情報を更新
- 拡張統計情報の追加
- 設定
- テーブルスキャン方式を指定(例. enable_seqscan)
- 結合方式を指定(例. enable_nestloop)
- join_collapse_limitを1に設定し、結合順序を制御
- force_generic_plan/force_custom_planによるジェネリックプラン/カスタムプランの制御
- default_statistics_targetによる収集する統計情報の量の調整
- cpu_tuple_costなど各処理1単位あたりのコストの調整
- PostgreSQL本体以外のエクステンション
- pg_hint_planによるヒント句の付与
- pg_dbms_statsによる統計情報の固定化
- クエリの変更
- WITH句でAS MATERIALIZEDを利用し、結合順序を制御
- サブクエリのWindow関数への書き換え
- インデックスを利用させないよう、+0を追加し式にするなど結果に影響のない変更の追加
ANALYZEコマンドを実行し、統計情報を更新
まずANALYZEコマンドの実行は有効なことが多いです。
バッチ処理などにより大量の更新が定期的に実施されるテーブルは、更新処理後にANALYZEを実行するようスケジュールしておくとよいでしょう。
ANALYZEは、VACUUM等に比べ一般的に負荷が低く、ANALYZE自体の性能影響については通常そこまで気にする必要性は低いです。結合方式を指定(例. enable_nestloop)
enable_nestloopのような結合方式を指定するパラメータをoffに設定しても、その結合方式が選ばれることがあります。
enable_*をoffに設定すると、通常所定の大きなコスト値が当該結合方式のコストに加算されますが、その加算されたコストより他のプランのコストが大きい場合、enable_*を指定したプランが選択されてしまうためです。
なお、PostgreSQL18からは、この方式が変更され、コストを比較する前に、enable_*をoffにした数を比較するようになる予定です。pg_hint_planによるヒント句の付与
pg_hint_planはよく使われるエクステンションかと思いますが、しばしばヒント句が効かないという話を伺います。
以下のような原因が考えられますので、該当していないか確認するとよいでしょう:- ヒント句の場所が間違っている。特にPL/pgSQLでは制限があるので注意
- 大文字・小文字の指定が間違っている。pg_hint_planはPostgreSQLと異なり、ヒント句に含まれるオブジェクト名とデータベース内部のオブジェクト名の大文字・小文字を区別する
- 選択させたい実行計画を、プランナが候補にあげていない
まとめ
プランナは、利用者があれこれ指示しなくても、適切なクエリの実行の仕方を選択してくれる優れものですが、ユーザの手助けが必要なときもあります。
具体的には以下のサイクルを回すことになります:- ユーザの手助けが必要かどうかわかるように、実行時間や実行計画のモニタリングをする
- ツールなども利用しつつ実行計画を読み、ボトルネックを把握する
- ボトルネックを解消するためのアクションを検討、実施する
プラン周りの話に限りませんが、問題が起こってからでは対処しきれないことが多いので、設計段階から準備しておくことが重要です。
必要に応じ、PostgreSQLのサポートサービスの利用も検討されるとよいと思います。注1: 拡張統計情報を作成すればこの動作は改善が可能です。
注2: GUCパラメータ cpu_tuple_cost, seq_page_costなどで設定可能です。詳細は、マニュアルをご参照ください。
注3: 例えば、PostgreSQLの公式のWikiではこちらに参考資料のリンクがあります。
注4: SSDではHDDに比べると特にランダムI/Oは改善されるものの、RAMに比べると通常数桁倍は遅いので、PostgreSQLのようなディスクベースのDBではボトルネックになることが多いです
- 運用
- PostgreSQL本体