
Pgpool-II は、PostgreSQL 専用のクラスタ管理ツールであり、コネクションプーリング、負荷分散、自動フェイルオーバーといった重要な機能を提供することで、PostgreSQL の高可用性と性能向上を実現します。
本記事では、性能向上やサーバリソースの効率的な活用に役立つコネクションプーリングの仕組みについて解説します。あわせて、運用時に押さえておくべき設定のポイントについても紹介します。
コネクションプーリングとは
データベースへの接続には、ネットワークのハンドシェイクや認証といった初期処理が伴います。そのため、リクエストのたびに接続してすぐに切断するような動作を繰り返すと、システム全体に大きなオーバーヘッドが発生してしまいます。
そこで効果を発揮するのが、コネクションプーリングという仕組みです。この機能では、一度確立したデータベース接続をキャッシュしておき、次回のリクエスト時に再利用することで、接続処理の無駄を省きます。これにより、システム全体のパフォーマンスが向上し、リソースを無駄なく効率的に活用できるようになります。
Pgpool‑II コネクションプーリングの仕組み
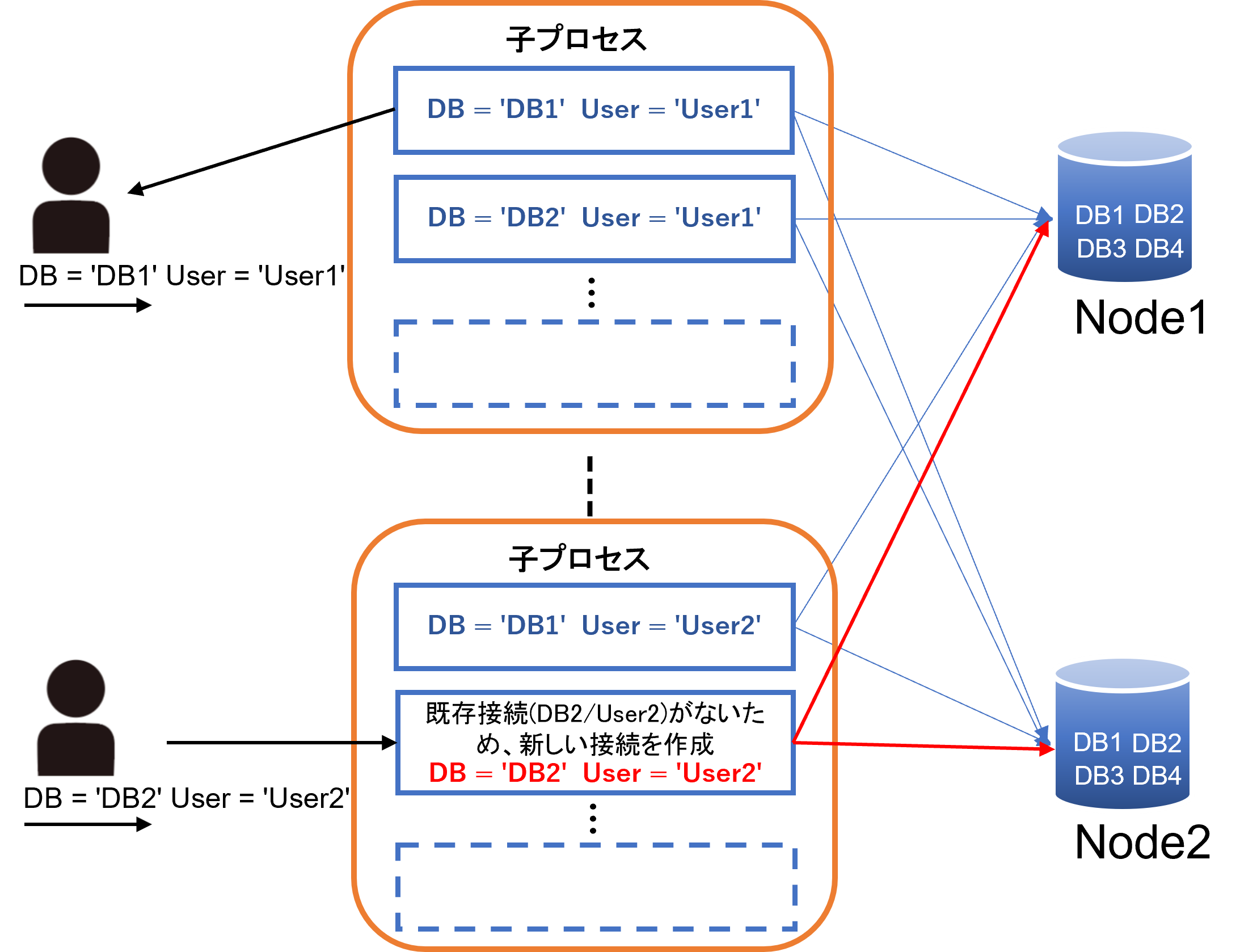
Pgpool-II は、ユーザ名・データベース名・プロトコルバージョンなどの接続プロパティが同一であるリクエストに対して、すでに確立された接続を再利用する仕組みを持っています。これにより、毎回の接続処理にかかるコストを削減し、全体の処理効率を高めることができます。
以下は、Pgpool-II コネクションプーリングの基本的な動作の流れです。
- 起動時に、Pgpool-II の親プロセスは num_init_children で指定された数の子プロセスをあらかじめフォークします。各子プロセスは max_pool の設定値まで接続をキャッシュします。
- Pgpool-II はクライアントからの接続要求を待ち受けます。
- いずれかの Pgpool-II の子プロセスが、クライアントからの接続要求を受け取ります。
- その子プロセスは、保持している接続内に、接続情報 (データベース/ユーザ) の一致するものがあるかどうかを探します。見つかったら再利用します。
- 見つからなければ、子プロセスは新たに PostgreSQL サーバへ接続し、それをプールに登録します。
プールに空きスロットがない場合は、最も古い接続を切断し、そのスロットを再利用します。 - クライアントがセッション終了要求を送るまで、クエリ処理を行います。
- クライアントが接続を終了します。Pgpool-II はクライアントへの接続をクローズしますが、PostgreSQL への接続を保持します。
主な設定パラメータ
以下は、コネクションプーリングに関連する設定項目です。
| パラメータ名 | 説明 | デフォルト値 |
|---|---|---|
| connection_cache | 接続のキャッシュを有効にするかどうか | on (有効) |
| max_pool | 各子プロセスがキャッシュできる接続の最大数 | 4 |
| connection_life_time | キャッシュされた接続を切断するまで時間 (秒) | 0 (無期限) |
| child_life_time | アイドル状態が続いた子プロセスを強制終了するまでの時間 (秒) | 300 秒 |
| child_max_connections | 一つの子プロセスが処理できるクライアント接続数の上限。上限に達したらプロセスが終了し、新プロセスが生成される | 0 (無制限) |
PostgreSQL では、接続ごとにプロセスが生成されますが、接続が切断されない限り、そのプロセスが使用するメモリは解放されません。Pgpool-II のコネクションプーリングを使用している場合、クライアントが切断しても PostgreSQL 側の接続は保持され続けるため、そのプロセスが使用するメモリも解放されません。
そのため、もし DB サーバのメモリ使用量が徐々に増加していく事象が発生している場合、Pgpool-II のコネクションプーリングが影響している可能性があります。このような事象やメモリリークのリスクを防ぐために、child_life_time を設定することが推奨されています。ただし、Pgpool-II の子プロセスがアイドル状態になる時間が child_life_time より短い場合、PostgreSQL への接続を終了する機会が得られません。そのため、child_max_connections も併せて設定しておくことで、一定回数の接続処理後に子プロセスを終了させ、より確実に接続とメモリを解放することができます。
設定上の注意点
Pgpool-II は、各 PostgreSQL サーバに対して以下の数の接続を確立する可能性があります。
num_init_children × max_pool
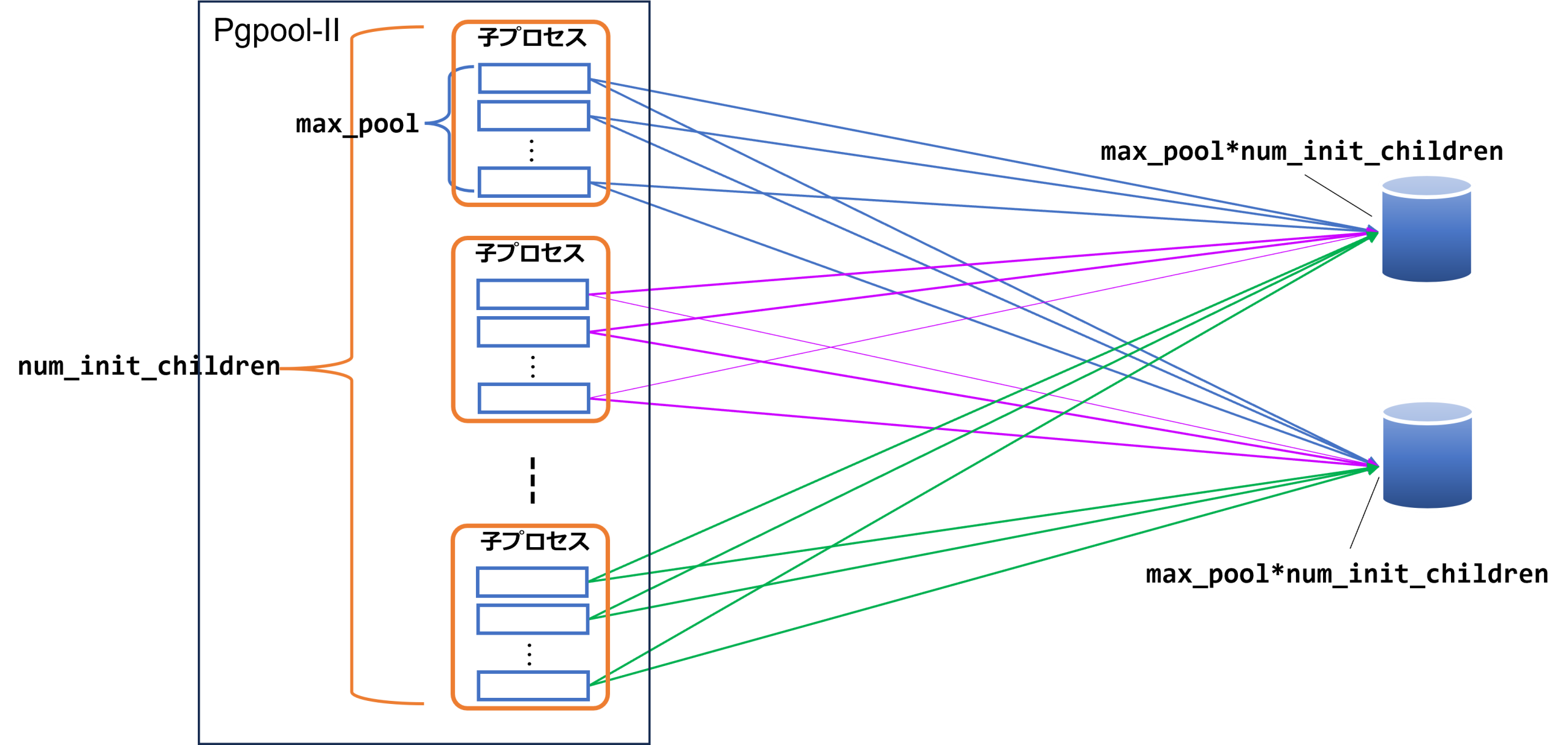
そのため、PostgreSQL 側の max_connections 設定と照らし合わせて、Pgpool-II の接続数を適切に設定する必要があります。
まず、PostgreSQL にはスーパーユーザ用の接続枠が superuser_reserved_connections によって確保されており、これは通常ユーザの接続には使用できません。したがって、Pgpool-II からの接続数は、この予約分を除いた枠内に収まるように調整する必要があります。
また、Pgpool-II はクエリキャンセルを行う際に、既存の接続とは別に新たな接続を PostgreSQL に確立するため、この追加分も接続数として考慮する必要があります。
さらに、Pgpool-II の Watchdog 機能を利用している場合、リーダー切り替えのタイミングで旧リーダーの接続が残ったまま、新しいリーダーが接続を開始するケースもあります。このような状況では一時的に接続数が増加し、PostgreSQL 側の制限を超えてしまうリスクがあります。
これらを踏まえると、Pgpool-II の接続数が PostgreSQL の接続数上限に収まるように、以下の条件を満たすように設計する必要があります。
- クエリキャンセルを考慮しない場合
max_pool × num_init_children × 2 ≤ max_connections − superuser_reserved_connections
- クエリキャンセルを考慮する場合
max_pool × num_init_children × 2 × 2 ≤ max_connections − superuser_reserved_connections
終わりに
今回は Pgpool-II のコネクションプーリング機能について紹介しました。この機能を活用することで、PostgreSQL の接続効率を高め、リソースの最適化が期待できます。Pgpool-II を導入する際は、ぜひコネクションプーリング機能の活用をご検討ください。