前回の記事では、スプリットブレインの発生メカニズムおよび Pacemaker/Corosync におけるその対策について解説しました。
本記事では、スプリットブレイン対策の中でも、2 ノードクラスタにおけるクォーラム確立を支援する「クォーラムデバイス」に焦点を当て、その仕組みと基本的な使い方について紹介します。
クォーラムデバイスの仕組み
クォーラムデバイスは、ノード間通信が切断された際に、どのノード (またはパーティション) がクラスタの運用を継続すべきかを判断するための外部投票ノードです。
偶数ノードで構成されたクラスタでは、ネットワーク分断時に投票数が同数となり、クォーラム (過半数) が成立しないという問題があります。特に2ノードクラスタでは、インターコネクトが切断されると双方が相手を障害と誤認し、スプリットブレイン状態に陥るリスクが高くなります。
このような構成では、クラスタノードとは別に調停役となるクォーラムデバイスを追加することで、クラスタ全体の投票数が奇数となり、過半数による多数決が成立します。その結果、スプリットブレイン発生時でも、どちらのノードがクラスタを継続すべきかを適切に判断できるようになります。
2ノードクラスタの場合、通常は各ノードが1票ずつを持ちますが、クォーラムデバイスを追加すると合計3票となります。ネットワーク分断が発生した際には、クォーラムデバイスの投票を含めた多数決により、過半数を得たノードのみがクラスタ管理を継続できます。これにより、両ノードが同時にリソースを稼働させる事態を防止できます。
偶数ノード構成、特に2ノードクラスタではスプリットブレインのリスクが高いため、クォーラムデバイスの利用が推奨されます。
クォーラムデバイスを利用したクラスタ構成
以下は、クォーラムデバイスを利用したクラスタ構成です。
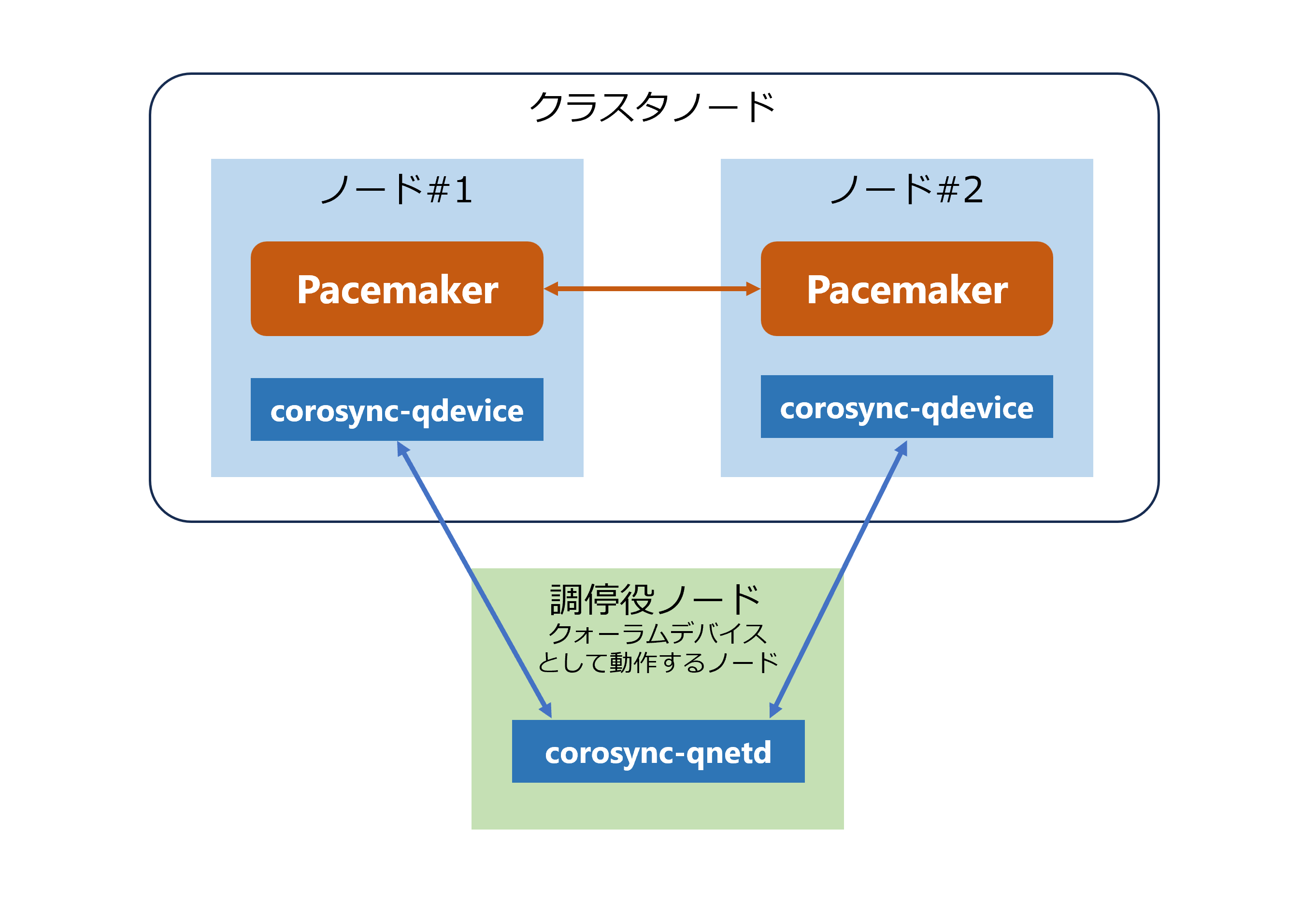
クォーラムデバイスを利用する場合、クラスタノードには corosync-qdevice をインストールし、調停役となるサーバには corosync-qnetd をインストールします。corosync-qnetd デーモンはクラスタ外部で動作し、投票を行います。分断時には corosync-qnetd の判定結果に基づき、過半数を得たノードのみがクラスタを維持し、過半数を得られなかったノードはクラスタサービスを停止します。
corosync-qnetd の判定アルゴリズム
corosync-qnetd は、以下の判定アルゴリズムに対応しています。
- ffsplit (fifty-fifty split):デフォルトのアルゴリズムです。アクティブなノード数が最も多いパーティションに 1 票を与えます。クラスタが同数(1:1)に分断された場合は、
tie_breakerの設定に基づいて投票先を決定します。デフォルトでは、最も小さな node ID を含むパーティションに 1 票を与えます。 - lms (last-man-standing):corosync-qnetd サーバと通信できるノードが 1 台のみになった場合、そのノードに 1 票を与えます。
クォーラムデバイス構成時の注意点
クォーラムデバイスを構成する際には、以下の点を考慮する必要があります。
- クォーラムデバイスはクラスタノードとは別のサーバで動作させる必要があります。既存のクラスタノード上で実行しないでください。
- 可能であれば、クォーラムデバイスを Corosync が使用するネットワークとは異なるネットワークに配置します。
- 複数のクラスタで 1 つのクォーラムデバイスを共有できますが、1 つのクラスタに複数のクォーラムデバイスを構成することはできません。
検証環境と前提条件
本記事では、クォーラムデバイスを利用した 2 ノードクラスタ構成で動作検証を行います。
クラスタ構成およびクォーラムデバイスは以下になります。
| ホスト名 | IPアドレス | |
|---|---|---|
| クラスタノード | node1 | 192.168.100.101 |
| node2 | 192.168.100.102 | |
| クォーラムデバイスとして動作するノード | qdevice | 192.168.100.100 |
今回は検証目的で RHEL クローン OS の Rocky Linux 環境を用いて検証を行います。Rocky Linux では Red Hat High Availability Add-On 相当のパッケージが highavailability リポジトリに含まれているため、今回はそちらのリポジトリを利用してインストールします。バージョン情報は以下になります。
| OS | Rocky Linux 10.1 |
|---|---|
| Pacemaker | 3.0.1 |
| Corosync | 3.1.9 |
| PCS | 0.12.1 |
| corosync-qdevice | 3.0.3 |
| corosync-qnetd | 3.0.3 |
すべてのクラスタノードおよびクォーラムデバイスとして動作するノードにおいて、/etc/hosts にホスト名と IP アドレスを設定します。
# vi /etc/hosts (以下を追加) 192.168.100.101 node1 192.168.100.102 node2 192.168.100.100 qdevice
Pacemaker のインストールおよびクラスタの初期設定
1. Pacemaker をインストールします。
各クラスタノードで highavailability リポジトリを有効にし、Pacemaker 関連パッケージをインストールします。
(node1、node2 で実行) # dnf install -y --enablerepo=highavailability pacemaker pcs
※ RHEL 環境を利用している場合は、Red Hat 社によって提供される Red Hat High Availability Add-On のパッケージを利用してインストールしてください。詳細についてはこちらを参照してください。
2. firewalld デーモンが起動している場合は、クラスタ通信に必要なポートを許可するように以下のコマンドを実行します。
(node1、node2 で実行)
# firewall-cmd --permanent --add-service=high-availability
# firewall-cmd --reload
3. 両ノードで hacluster ユーザのパスワードを設定します。
(node1、node2で実行) # passwd hacluster Changing password for user hacluster. New password: (haclusterユーザのパスワードを入力) Retype new password: (haclusterユーザのパスワードを入力) passwd: all authentication tokens updated successfully.
4. 両ノードで以下のコマンドを実行し、pcsd の自動起動を有効化します。
(node1、node2 で実行) # systemctl start pcsd.service # systemctl enable pcsd.service
5. いずれかのノードからクラスタを構成するノードに対して、hacluster ユーザの認証を行います。
(node1 または node2 のいずれかで実行) # pcs host auth node1 node2 -u hacluster Password: (haclusterユーザのパスワードを入力) node1: Authorized node2: Authorized
6. クラスタを作成します。クラスタの名前を test_cluster とします。
(node1 または node2 のいずれかで実行) # pcs cluster setup test_cluster node1 addr=192.168.100.101 node2 addr=192.168.100.102 Destroying cluster on hosts: 'node1', 'node2'... node1: Successfully destroyed cluster node2: Successfully destroyed cluster Requesting remove 'pcsd settings' from 'node1', 'node2' node1: successful removal of the file 'pcsd settings' node2: successful removal of the file 'pcsd settings' Sending 'corosync authkey', 'pacemaker authkey' to 'node1', 'node2' node1: successful distribution of the file 'corosync authkey' node1: successful distribution of the file 'pacemaker authkey' node2: successful distribution of the file 'corosync authkey' node2: successful distribution of the file 'pacemaker authkey' Sending 'corosync.conf' to 'node1', 'node2' node1: successful distribution of the file 'corosync.conf' node2: successful distribution of the file 'corosync.conf' Cluster has been successfully set up.
7. クラスタを起動します。
(node1 または node2 のいずれかで実行) # pcs cluster start --all
pcs status コマンドを使用して、作成したクラスタのステータスを表示します。node1、node2 が Online になっていることを確認します。
(node1 または node2 のいずれかで実行) # pcs status Cluster name: test_cluster ... Node List: * Online: [ node1 node2 ]
8. クラスタを安全に運用するために、フェンシングの設定が必要になりますが、今回はクォーラムデバイスを検証することを目的としているため、以下のコマンドを実行し、フェンシングを無効にします。
(node1 または node2 のいずれかで実行) # pcs property set stonith-enabled=false
9. 検証用の Dummy リソースを作成します。
(node1 または node2 のいずれかで実行) # pcs resource create Dummy ocf:heartbeat:Dummy
リソースが作成されていることを確認します。
(node1 または node2 のいずれかで実行) # pcs status Cluster name: test_cluster ... Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Started node1
以上で、Pacemaker クラスタの初期設定は完了です。
クォーラムデバイスを使わない場合の動作確認
ここでは、クォーラムデバイスを使用しない状態で、2 ノード間のインターコネクト通信を切断した場合の挙動を確認します。
まず、疑似障害を起こすため、node1 と node2 間のインターコネクト通信を切断します。
しばらく待ってから pcs status コマンドを実行し、クラスタの状態を確認します。すると、両ノードがそれぞれ DC (Designated Controller) として選出され、それぞれのノード上でリソースが起動していることが確認できます。
(node1 で実行) [root@node1 ~]# pcs status Cluster name: test_cluster Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: node1 (version 3.0.1-3.el10-b1a23a6) - partition with quorum ... Node List: * Online: [ node1 ] * OFFLINE: [ node2 ] Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Started node1
(node2 で実行) [root@node2 ~]# pcs status Cluster name: test_cluster Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: node2 (version 3.0.1-3.el10-b1a23a6) - partition with quorum ... Node List: * Online: [ node2 ] * OFFLINE: [ node1 ] Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Started node2
これは、両ノードが自身を稼働系と誤認識している状態であり、典型的なスプリットブレイン状態です。
クォーラムデバイスのインストールおよび設定
ここでは、既存のクラスタ (node1、node2) にクォーラムデバイスを追加し、スプリットブレイン防止について動作検証を通して効果を検証します。
クォーラムデバイスのインストール
1. 既存のクラスタノード node1 と node2 に corosync-qdevice をインストールします。
(node1、node2 で実行) # dnf install -y --enablerepo=highavailability corosync-qdevice
2. クォーラムデバイスとして使用されるノード qdevice に pcs および corosync-qnetd をインストールします。
(qdevice で実行) [root@qdevice ~]# dnf install -y --enablerepo=highavailability pcs corosync-qnetd
3. qdevice 上で pcsd サービスを起動し、自動起動の設定を行います。
(qdevice で実行) [root@qdevice ~]# systemctl start pcsd.service [root@qdevice ~]# systemctl enable pcsd.service
4. firewalld デーモンが起動している場合は、クラスタで必要なポートを有効化するように以下のコマンドを実行します。
(qdevice で実行) [root@qdevice ~]# firewall-cmd --permanent --add-service=high-availability [root@qdevice ~]# firewall-cmd --reload
クォーラムデバイスの設定
ここでは、既存のクラスタにクォーラムデバイスを追加する手順を記載します。
1. クォーラムデバイスモデル net を指定し、クォーラムデバイスのセットアップおよび起動を行います。また、システム起動時にクォーラムデバイスが起動するように設定します。
(qdevice で実行) [root@qdevice:~]# pcs qdevice setup model net --enable --start Quorum device 'net' initialized quorum device enabled Starting quorum device... quorum device started
起動後、pcs qdevice status net --full を実行し、クォーラムデバイスの状態を確認します。
(qdevice で実行) [root@qdevice ~]# pcs qdevice status net --full QNetd address: *:5403 TLS: Supported (client certificate required) Connected clients: 0 Connected clusters: 0 Maximum send/receive size: 32768/32768 bytes
2. クラスタノードの pcs がクォーラムデバイス qdevice にアクセスできるように、hacluster ユーザの認証を行います。
(node1 または node2 のいずれかで実行) # pcs host auth qdevice -u hacluster Password: (hacluster ユーザのパスワードを入力) qdevice: Authorized
3. クォーラムデバイスをクラスタに追加します。
クォーラムデバイスを追加する前に、後で比較するために、クォーラムデバイスの現在の設定と状況を確認できます。
このコマンドの出力から、クラスタがクォーラムデバイスを使用しておらず、各ノードの Qdevice メンバーシップのステータスが NR (Not Registered:登録されていない) であることが分かります。
[root@node1 ~]# pcs quorum config
[root@node1 ~]# pcs quorum status
Quorum information
------------------
Date: Sun Feb 2 11:39:03 2026
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1.1d
Quorate: Yes
Votequorum information
----------------------
Expected votes: 2
Highest expected: 2
Total votes: 2
Quorum: 1
Flags: 2Node Quorate WaitForAll
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 NR node1 (local)
2 1 NR node2
以下のコマンドを実行し、クォーラムデバイスをクラスタに追加します。host にクォーラムデバイスとして動作するノードのホスト名、algorithm に使用するアルゴリズム (ffsplit) を指定します。
(node1 または node2 のいずれかで実行) # pcs quorum device add model net host=qdevice algorithm=ffsplit Setting up qdevice certificates on nodes... node1: Succeeded node2: Succeeded Enabling corosync-qdevice... node1: not enabling corosync-qdevice: corosync is not enabled node2: not enabling corosync-qdevice: corosync is not enabled Sending updated corosync.conf to nodes... node2: Succeeded node1: Succeeded node1: Corosync configuration reloaded Starting corosync-qdevice... node2: corosync-qdevice started node1: corosync-qdevice started
上記コマンドを実行後、クォーラムデバイスの設定を確認するには、pcs quorum config を実行します。
(node1 または node2 のいずれかで実行)
# pcs quorum config
Device:
votes: 1
Model: net
algorithm: ffsplit
host: qdevice
4. クラスタノード側からクォーラムデバイスの状態を確認します。
クォーラムデバイスをクラスタに追加した後、まずはクラスタノード側から、クォーラムデバイスが正しく認識・動作しているかを確認します。
(node1 または node2 のいずれかで実行)
# pcs quorum status
Quorum information
------------------
Date: Sun Feb 2 11:45:38 2026
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1.1d
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate Qdevice
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 A,V,NMW node1 (local)
2 1 A,V,NMW node2
0 1 Qdevice
この Membership information は、現在のクォーラム判定に参加しているメンバー (投票者) 一覧を表しています。Qdevice が 1 vote を持つメンバーとして参加していることが分かります。
なお、A,V,NMW は votequorum におけるノード状態フラグであり、それぞれの意味は次のとおりです。
- A/NA
- A (Active):クォーラムデバイスがそのノードに対して有効な状態
- NA (Not Active):クォーラムデバイスがそのノードに対して無効な状態
- V/NV
- V (Voting):クォーラムデバイスがそのノードへ投票を与えている
- NV (Not Voting):クォーラムデバイスがそのノードに投票を与えていない
- MW/NMW
- MW (Master Wins):master_wins フラグが有効
- NMW (Not Master Wins):master_wins フラグが無効 (デフォルト)
続いて、pcs quorum device status コマンドを使って、クォーラムデバイスとの接続状態やアルゴリズム設定を確認します。
(node1 または node2 のいずれかで実行)
[root@node1 ~]# pcs quorum device status
Qdevice information
-------------------
Model: Net
Node ID: 1
Configured node list:
0 Node ID = 1
1 Node ID = 2
Membership node list: 1, 2
Qdevice-net information
----------------------
Cluster name: test_cluster
QNetd host: qdevice:5403
Algorithm: Fifty-Fifty split
Tie-breaker: Node with lowest node ID
State: Connected
Qdevice-net information の結果から、判定アルゴリズムと決定ルールを確認できます。
- Algorithm: Fifty-Fifty split は、クラスタが同数に分断された場合(2 ノードクラスタでは 1:1 の分断)に適用される判定アルゴリズムです。
- Tie-breaker: Node with lowest node ID は、分断時に最も小さな node ID を含むパーティションを primary component(quorum を持つ側)として選択する決定ルールを示しています。
5. 次に、クォーラムデバイス側で、corosync-qnetd デーモンの状態を確認します。
以下のコマンドを実行します。
(qdevice サーバで実行)
[root@qdevice:~]# pcs qdevice status net --full
QNetd address: *:5403
TLS: Supported (client certificate required)
Connected clients: 2
Connected clusters: 1
Maximum send/receive size: 32768/32768 bytes
Cluster "test_cluster":
Algorithm: Fifty-Fifty split (KAP Tie-breaker)
Tie-breaker: Node with lowest node ID
Node ID 1:
Client address: ::ffff:192.168.100.101:33624
HB interval: 8000ms
Configured node list: 1, 2
Ring ID: 1.1d
Membership node list: 1, 2
Heuristics: Undefined (membership: Undefined, regular: Undefined)
TLS active: Yes (client certificate verified)
Vote: No change (ACK)
Node ID 2:
Client address: ::ffff:192.168.100.102:32998
HB interval: 8000ms
Configured node list: 1, 2
Ring ID: 1.1d
Membership node list: 1, 2
Heuristics: Undefined (membership: Undefined, regular: Undefined)
TLS active: Yes (client certificate verified)
Vote: ACK (ACK)
両ノードとも、同一の Membership node list、正常な ACK 応答となっており、qnetd から見てもクラスタは健全な状態であることが確認できます。
クォーラムデバイスを使ったクラスタの動作確認
前の検証では、クォーラムデバイスを使用しない 2 ノードクラスタにおいて、ノード間のネットワークを切断すると、両ノードがそれぞれ DC となり、リソースを起動してしまう (いわゆるスプリットブレイン状態) ことを確認しました。
ここでは、クォーラムデバイスを導入した場合に、同じ障害を発生させたときの挙動がどのように変わるのかを確認します。
正常時の状態確認
まずは、ネットワーク切断前の状態を確認します。
[root@node1 ~]# pcs status Cluster name: test_cluster Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: node1 (version 3.0.1-3.el10-b1a23a6) - partition with quorum * Last updated: Mon Feb 2 13:51:22 2026 on node1 * Last change: Mon Feb 2 13:36:39 2026 by root via root on node1 * 2 nodes configured * 1 resource instance configured Node List: * Online: [ node1 node2 ] Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Started node1
Quorum 情報を確認すると、Qdevice が投票に参加していることが分かります。
[root@node1:~]# pcs quorum status
Quorum information
------------------
Date: Mon Feb 2 13:55:20 2026
Quorum provider: corosync_votequorum
Nodes: 2
Node ID: 1
Ring ID: 1.26
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 3
Quorum: 2
Flags: Quorate Qdevice
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 A,V,NMW node1 (local)
2 1 A,V,NMW node2
0 1 Qdevice
ノード間ネットワークの切断
次に、疑似障害として node1 と node2 間のインターコネクト通信を切断します。(Qdevice との通信は維持された状態)
障害発生後の状態確認
node1 と node2 間のネットワークを切断した後、それぞれのノードで pcs status を実行し、クラスタの状態を確認します。
[root@node1 ~]# pcs status Cluster name: test_cluster Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: node1 (version 3.0.1-3.el10-b1a23a6) - partition with quorum * Last updated: Mon Feb 2 15:14:59 2026 on node1 * Last change: Mon Feb 2 15:14:13 2026 by root via root on node1 * 2 nodes configured * 1 resource instance configured Node List: * Online: [ node1 ] * OFFLINE: [ node2 ] Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Started node1
node1 は クォーラムデバイスからの投票を含めて quorum を維持しており、引き続き DC として選出され、リソースを起動した状態で稼働しています。
[root@node2 ~]# pcs status Cluster name: test_cluster Cluster Summary: * Stack: corosync (Pacemaker is running) * Current DC: node2 (version 3.0.1-3.el10-b1a23a6) - partition WITHOUT quorum * Last updated: Mon Feb 2 15:15:04 2026 on node2 * Last change: Mon Feb 2 15:14:14 2026 by root via root on node1 * 2 nodes configured * 1 resource instance configured Node List: * Online: [ node2 ] * OFFLINE: [ node1 ] Full List of Resources: * Dummy (ocf:heartbeat:Dummy): Stopped
node2 はクラスタ内では単独ノードとなり、クォーラムを満たせない状態 (partition WITHOUT quorum) となっています。その結果、DC にはなっているものの、quorum を持たないため、リソースは起動されない、という状態になっています。
クォーラム状態の確認
次に、node1 側で pcs quorum status を実行し、クォーラム状態を確認します。
[root@node1 /]# pcs quorum status
Quorum information
------------------
Date: Mon Feb 2 15:16:14 2026
Quorum provider: corosync_votequorum
Nodes: 1
Node ID: 1
Ring ID: 1.86
Quorate: Yes
Votequorum information
----------------------
Expected votes: 3
Highest expected: 3
Total votes: 2
Quorum: 2
Flags: Quorate Qdevice
Membership information
----------------------
Nodeid Votes Qdevice Name
1 1 A,V,NMW node1 (local)
0 1 Qdevice
この結果から分かる通り、node1 と Qdevice がそれぞれ 1 vote を保持し、合計 2 votes(quorum=2)となるため、node1 側では quorum が維持されています。クォーラムデバイスは、デフォルト設定では存続しているノードのうち、最も小さな node ID を持つノードを含むパーティションを選択します。今回の構成では node1 が選択され、node2 側は quorum を失う結果となりました。
ログの確認
node2 側のログを確認すると、quorum 喪失に伴う挙動が明確に分かります。
(node2ログ) Feb 2 15:14:48 node2 pacemaker-controld[4354]: notice: Node node1 state is now lost Feb 2 15:14:48 node2 corosync[4330]: [QUORUM] This node is within the non-primary component and will NOT provide any services.
このログは、このノードは non-primary component (quorum を持たない側) に属しており、サービスを提供してはならない、ことを示しています。
続く Pacemaker のログでも、quorum 喪失によりリソース管理が抑止されていることが分かります。
(node2ログ) Feb 2 15:14:49 node2 pacemaker-schedulerd[4353]: warning: Fencing and resource management disabled due to lack of quorum Feb 2 15:14:49 node2 pacemaker-schedulerd[4353]: notice: Actions: Start Dummy ( node2 ) due to no quorum (blocked)
おわりに
本記事では、2 ノードクラスタにおけるスプリットブレイン対策として、クォーラムデバイスの仕組みと設定方法、そして実際の動作検証結果について解説しました。
クォーラムデバイスを導入しない場合、ノード間のネットワーク分断時に双方が自身を正当なクラスタと判断し、同時にリソースを起動してしまう可能性があります。一方で、クォーラムデバイスを追加することで投票数が奇数となり、外部の調停役による判定が加わることで、過半数を得た側のみがサービスを継続できるようになります。これにより、2 ノードクラスタ特有のスプリットブレインリスクを大きく低減できます。
特に、コストや設計上の理由から 2 ノード構成を採用せざるを得ない環境や、環境要件や構成上の制約により電源制御を用いたフェンシングを採用しない場合には、クォーラムデバイスは有効な補完策となります。
本記事が、2 ノードクラスタの設計やスプリットブレイン対策を検討されている方の参考になれば幸いです。