TimescaleDB は、IoT 機器のセンサーやスマートメーターが生成するデータのように、時系列に沿って発生するデータを扱うのに適した時系列データベースの機能を、リレーショナルデータベース PostgreSQL に追加する拡張モジュールです。
この記事では、TimescaleDB の備える時系列データ向けの分析機能について紹介します。TimescaleDB の概要やインストール、基本的な使い方については前回の TimescaleDB の紹介 を参照してください。
時系列データの分析関数
TimescaleDB には時系列データの分析に便利な関数がいくつかあります。ここでは、前回生成したデータを使って各関数の概要と使い方について紹介していきます。それには、まず、test データベースに接続しておきます。
$ psql test psql (13.2) "help"でヘルプを表示します。 =#
time_bucket 関数
time_bucket 関数は時間を任意の間隔で丸める関数です。同じような関数は PostgreSQL にもあって date_trunc 関数と言います。
date_trunc 関数を使うと、例えば、1 分間隔で収集した温度のデータに対し、1 時間ごとの平均を求められます。
=# SELECT date_trunc('hour', time) AS time_1h,
location,
avg(temperature)
FROM conditions
GROUP BY time_1h, location
ORDER BY time_1h, location;
time_1h | location | avg
---------------------+----------+--------------------
2020-01-30 00:00:00 | nagoya | 19.883333333333333
2020-01-30 00:00:00 | osaka | 20.68333333333333
2020-01-30 00:00:00 | tokyo | 20.73
2020-01-30 01:00:00 | nagoya | 19.65666666666666
2020-01-30 01:00:00 | osaka | 20.82
2020-01-30 01:00:00 | tokyo | 20.04000000000001
2020-01-30 02:00:00 | nagoya | 18.854999999999993
2020-01-30 02:00:00 | osaka | 19.89833333333333
2020-01-30 02:00:00 | tokyo | 20.345000000000006
2020-01-30 03:00:00 | nagoya | 20.338333333333335
2020-01-30 03:00:00 | osaka | 20.395
2020-01-30 03:00:00 | tokyo | 20.781666666666673
(省略)
同じことは time_bucket 関数でもできます。
=# SELECT time_bucket('1 hour', time) AS time_1h,
location,
avg(temperature)
FROM conditions
GROUP BY time_1h, location
ORDER BY time_1h, location;
time_1h | location | avg
---------------------+----------+--------------------
2020-01-30 00:00:00 | nagoya | 19.883333333333333
2020-01-30 00:00:00 | osaka | 20.68333333333333
2020-01-30 00:00:00 | tokyo | 20.73
2020-01-30 01:00:00 | nagoya | 19.65666666666666
2020-01-30 01:00:00 | osaka | 20.82
2020-01-30 01:00:00 | tokyo | 20.04000000000001
2020-01-30 02:00:00 | nagoya | 18.854999999999993
2020-01-30 02:00:00 | osaka | 19.89833333333333
2020-01-30 02:00:00 | tokyo | 20.345000000000006
2020-01-30 03:00:00 | nagoya | 20.338333333333335
2020-01-30 03:00:00 | osaka | 20.395
2020-01-30 03:00:00 | tokyo | 20.781666666666673
(省略)
date_trunc 関数と time_bucket 関数の違いは、date_trunc 関数が 1 時間や 1 日など、固定の時間でしか丸められないのに対し、time_bucket 関数は 3 時間や 5 日など、任意の時間で丸められることです。time_bucket 関数を使うと、例えば、3 時間ごとの平均を求められます。
=# SELECT time_bucket('3 hours', time) AS time_3h,
location,
avg(temperature)
FROM conditions
GROUP BY time_3h, location
ORDER BY time_3h, location;
time_3h | location | avg
---------------------+----------+--------------------
2020-01-30 00:00:00 | nagoya | 19.465
2020-01-30 00:00:00 | osaka | 20.46722222222223
2020-01-30 00:00:00 | tokyo | 20.371666666666673
2020-01-30 03:00:00 | nagoya | 20.202777777777776
2020-01-30 03:00:00 | osaka | 19.89277777777778
2020-01-30 03:00:00 | tokyo | 21.122222222222224
2020-01-30 06:00:00 | nagoya | 19.99055555555557
2020-01-30 06:00:00 | osaka | 19.288333333333338
2020-01-30 06:00:00 | tokyo | 19.353333333333335
2020-01-30 09:00:00 | nagoya | 20.950000000000003
2020-01-30 09:00:00 | osaka | 20.285000000000007
2020-01-30 09:00:00 | tokyo | 20.203333333333326
(省略)
time_bucket_gapfill 関数
time_bucket_gapfill 関数は time_bucket 関数と同じく時間を任意の間隔で丸める関数ですが、欠落したデータを補ってくれることが異なります。
例えば、2020 年 2 月 1 日、東京のデータを削除し、人為的にデータを欠落させ、time_bucket 関数を使って 3 時間ごとの平均を求めると、6 時、9 時のデータが欠落しているのが分かります。
=# DELETE FROM conditions
WHERE time >= '2020-02-01 06:00:00'
AND time < '2020-02-01 12:00:00' AND location = 'tokyo';
DELETE 360
=# SELECT time_bucket('3 hours', time) AS time_3h, location, avg(temperature) FROM conditions WHERE time >= '2020-02-01'
AND time < '2020-02-02'
GROUP BY time_3h, location
ORDER BY time_3h, location;
time_3h | location | avg
---------------------+----------+--------------------
2020-02-01 00:00:00 | nagoya | 19.75833333333333
2020-02-01 00:00:00 | osaka | 20.46555555555556
2020-02-01 00:00:00 | tokyo | 19.315555555555555
2020-02-01 03:00:00 | nagoya | 19.328888888888887
2020-02-01 03:00:00 | osaka | 20.167777777777783
2020-02-01 03:00:00 | tokyo | 19.592777777777773
2020-02-01 06:00:00 | nagoya | 19.87055555555555
2020-02-01 06:00:00 | osaka | 20.07277777777777
2020-02-01 09:00:00 | nagoya | 19.240555555555563
2020-02-01 09:00:00 | osaka | 19.915
2020-02-01 12:00:00 | nagoya | 20.018888888888895
2020-02-01 12:00:00 | osaka | 19.66388888888888
2020-02-01 12:00:00 | tokyo | 19.437777777777782
2020-02-01 15:00:00 | nagoya | 19.904444444444444
2020-02-01 15:00:00 | osaka | 20.11388888888888
2020-02-01 15:00:00 | tokyo | 19.707222222222217
2020-02-01 18:00:00 | nagoya | 20.251111111111115
2020-02-01 18:00:00 | osaka | 20.023888888888884
2020-02-01 18:00:00 | tokyo | 20.571666666666676
2020-02-01 21:00:00 | nagoya | 19.91722222222222
2020-02-01 21:00:00 | osaka | 20.952777777777772
2020-02-01 21:00:00 | tokyo | 19.904444444444447
(22 行)
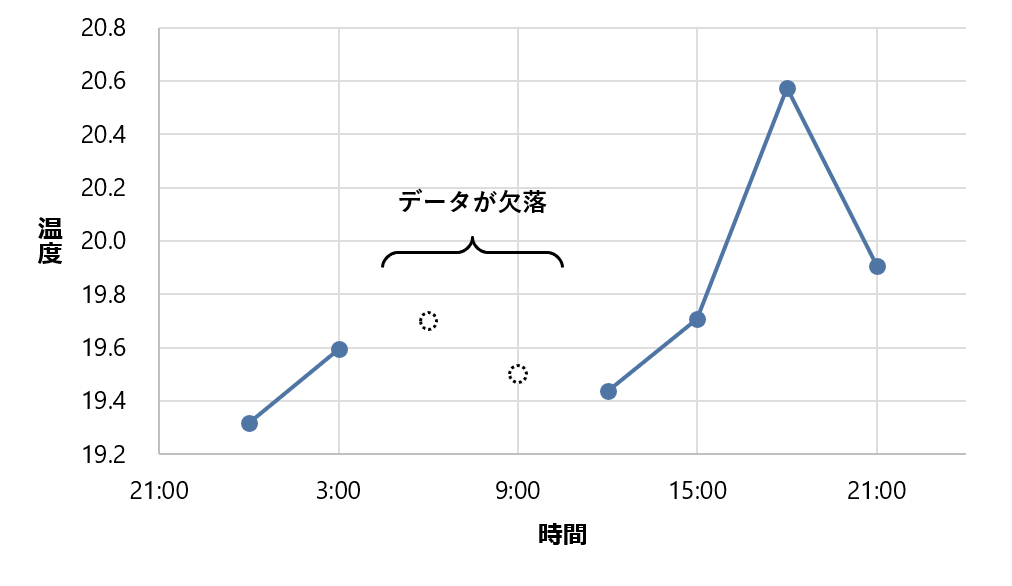
それに対し、time_bucket_gapfill 関数を使うと、欠落したデータに NULL が補われるようになります。
=# SELECT time_bucket_gapfill('3 hours', time) AS time_3h,
location,
avg(temperature)
FROM conditions
WHERE time >= '2020-02-01'
AND time < '2020-02-02'
GROUP BY time_3h, location
ORDER BY time_3h, location;
time_3h | location | avg
---------------------+----------+--------------------
2020-02-01 00:00:00 | nagoya | 19.75833333333333
2020-02-01 00:00:00 | osaka | 20.46555555555556
2020-02-01 00:00:00 | tokyo | 19.315555555555555
2020-02-01 03:00:00 | nagoya | 19.328888888888887
2020-02-01 03:00:00 | osaka | 20.167777777777783
2020-02-01 03:00:00 | tokyo | 19.592777777777773
2020-02-01 06:00:00 | nagoya | 19.87055555555555
2020-02-01 06:00:00 | osaka | 20.07277777777777
2020-02-01 06:00:00 | tokyo |
2020-02-01 09:00:00 | nagoya | 19.240555555555563
2020-02-01 09:00:00 | osaka | 19.915
2020-02-01 09:00:00 | tokyo |
2020-02-01 12:00:00 | nagoya | 20.018888888888895
2020-02-01 12:00:00 | osaka | 19.66388888888888
2020-02-01 12:00:00 | tokyo | 19.437777777777782
2020-02-01 15:00:00 | nagoya | 19.904444444444444
2020-02-01 15:00:00 | osaka | 20.11388888888888
2020-02-01 15:00:00 | tokyo | 19.707222222222217
2020-02-01 18:00:00 | nagoya | 20.251111111111115
2020-02-01 18:00:00 | osaka | 20.023888888888884
2020-02-01 18:00:00 | tokyo | 20.571666666666676
2020-02-01 21:00:00 | nagoya | 19.91722222222222
2020-02-01 21:00:00 | osaka | 20.952777777777772
2020-02-01 21:00:00 | tokyo | 19.904444444444447
(24 行)
time_bucket_gapfill 関数を使う場合には、どこからどこまでデータを補うかを指定するため、時間の範囲を WHERE 句か start、finish 引数で指定する必要があります。指定しないとエラーになります。
(以下、例示のため、実行不要)
=# SELECT time_bucket_gapfill('3 hours', time) AS time_3h,
location,
avg(temperature)
FROM conditions
GROUP BY time_3h, location
ORDER BY time_3h, location;
ERROR: missing time_bucket_gapfill argument: could not infer start from WHERE clause
HINT: Specify start and finish as arguments or in the WHERE clause.
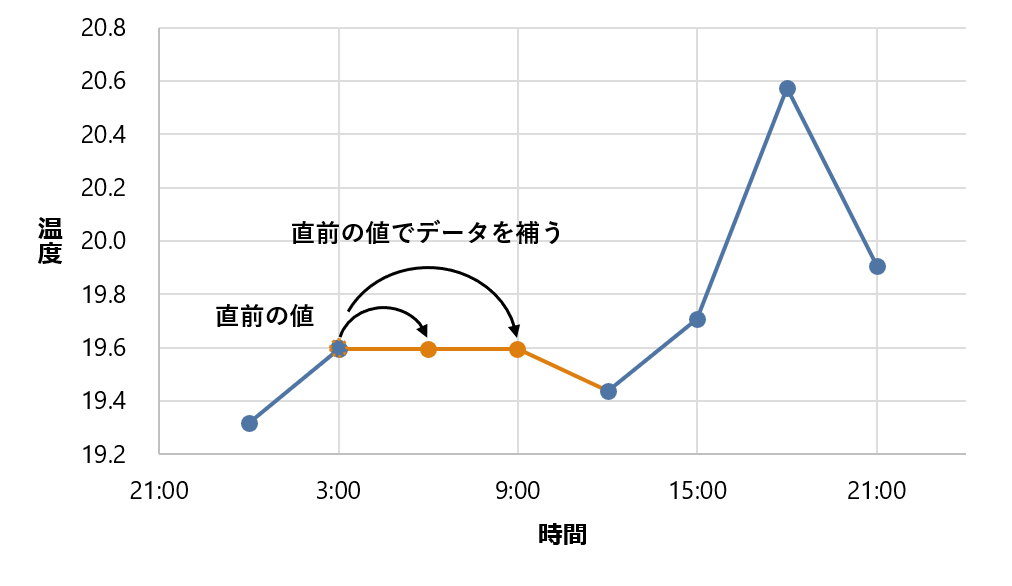
NULL の代わりに値を補うこともできます。それには、locf または interpolate 関数を使います。
locf (last observation carried forward; 最後に観測された値を繰り越す) 関数を使うと、直前の値がそのまま補われます。ここでは、6 時、9 時には直前の 3 時と同じ 19.592度 (以下、小数点第 4 位以下切り捨て) が補われます。
=# SELECT time_bucket_gapfill('3 hours', time) AS time_3h,
location,
locf(avg(temperature))
FROM conditions
WHERE time >= '2020-02-01'
AND time < '2020-02-02'
GROUP BY time_3h, location
ORDER BY time_3h, location;
time_3h | location | locf
---------------------+----------+--------------------
2020-02-01 00:00:00 | nagoya | 19.75833333333333
2020-02-01 00:00:00 | osaka | 20.46555555555556
2020-02-01 00:00:00 | tokyo | 19.315555555555555
2020-02-01 03:00:00 | nagoya | 19.328888888888887
2020-02-01 03:00:00 | osaka | 20.167777777777783
2020-02-01 03:00:00 | tokyo | 19.592777777777773
2020-02-01 06:00:00 | nagoya | 19.87055555555555
2020-02-01 06:00:00 | osaka | 20.07277777777777
2020-02-01 06:00:00 | tokyo | 19.592777777777773
2020-02-01 09:00:00 | nagoya | 19.240555555555563
2020-02-01 09:00:00 | osaka | 19.915
2020-02-01 09:00:00 | tokyo | 19.592777777777773
2020-02-01 12:00:00 | nagoya | 20.018888888888895
2020-02-01 12:00:00 | osaka | 19.66388888888888
2020-02-01 12:00:00 | tokyo | 19.437777777777782
2020-02-01 15:00:00 | nagoya | 19.904444444444444
2020-02-01 15:00:00 | osaka | 20.11388888888888
2020-02-01 15:00:00 | tokyo | 19.707222222222217
2020-02-01 18:00:00 | nagoya | 20.251111111111115
2020-02-01 18:00:00 | osaka | 20.023888888888884
2020-02-01 18:00:00 | tokyo | 20.571666666666676
2020-02-01 21:00:00 | nagoya | 19.91722222222222
2020-02-01 21:00:00 | osaka | 20.952777777777772
2020-02-01 21:00:00 | tokyo | 19.904444444444447
(24 行)
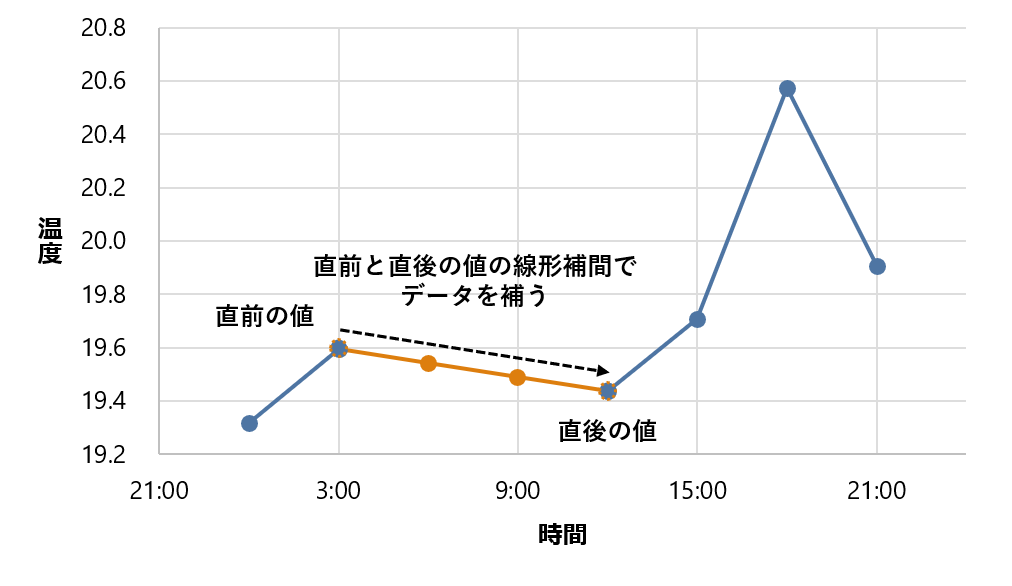
interpolate 関数を使うと、直前と直後の値をもとに線形補間によって値が補われます。ここでは、直前の 3 時は 19.592 度、直後の 12 時は19.437 度で、6 時は線形補間によって19.592 + (19.437 – 19.592) / 3 = 19.541 度、9 時も同じように 19.592 + (19.437 – 19.592) × 2 / 3 = 19.489 度が補われます。
=# SELECT time_bucket_gapfill('3 hours', time) AS time_3h,
location,
interpolate(avg(temperature))
FROM conditions
WHERE time >= '2020-02-01'
AND time < '2020-02-02'
GROUP BY time_3h, location
ORDER BY time_3h, location;
time_3h | location | interpolate
---------------------+----------+--------------------
2020-02-01 00:00:00 | nagoya | 19.75833333333333
2020-02-01 00:00:00 | osaka | 20.46555555555556
2020-02-01 00:00:00 | tokyo | 19.315555555555555
2020-02-01 03:00:00 | nagoya | 19.328888888888887
2020-02-01 03:00:00 | osaka | 20.167777777777783
2020-02-01 03:00:00 | tokyo | 19.592777777777773
2020-02-01 06:00:00 | nagoya | 19.87055555555555
2020-02-01 06:00:00 | osaka | 20.07277777777777
2020-02-01 06:00:00 | tokyo | 19.54111111111111
2020-02-01 09:00:00 | nagoya | 19.240555555555563
2020-02-01 09:00:00 | osaka | 19.915
2020-02-01 09:00:00 | tokyo | 19.489444444444445
2020-02-01 12:00:00 | nagoya | 20.018888888888895
2020-02-01 12:00:00 | osaka | 19.66388888888888
2020-02-01 12:00:00 | tokyo | 19.437777777777782
2020-02-01 15:00:00 | nagoya | 19.904444444444444
2020-02-01 15:00:00 | osaka | 20.11388888888888
2020-02-01 15:00:00 | tokyo | 19.707222222222217
2020-02-01 18:00:00 | nagoya | 20.251111111111115
2020-02-01 18:00:00 | osaka | 20.023888888888884
2020-02-01 18:00:00 | tokyo | 20.571666666666676
2020-02-01 21:00:00 | nagoya | 19.91722222222222
2020-02-01 21:00:00 | osaka | 20.952777777777772
2020-02-01 21:00:00 | tokyo | 19.904444444444447
(24 行)
first、last 関数
first、last 関数は別の列をキーに並び替え、最初、最後の値を取得する集約関数です。時間ごとに平均などでなく、素の値を抜き出すのに使います。並び替えにインデックスは使えないので、実行に時間がかかる場合があります。
例えば、2020 年 3 月 1 日、東京の温度のデータを 3 時間ごとに最初の値を取得してみます。
=# SELECT time_bucket('3 hours', time) AS time_3h,
first(temperature, time)
FROM conditions
WHERE time >= '2020-03-01'
AND time < '2020-03-02'
AND location = 'tokyo'
GROUP BY time_3h
ORDER BY time_3h;
time_3h | first
---------------------+-------
2020-03-01 00:00:00 | 24.4
2020-03-01 03:00:00 | 18.9
2020-03-01 06:00:00 | 25.1
2020-03-01 09:00:00 | 22.8
2020-03-01 12:00:00 | 25.8
2020-03-01 15:00:00 | 23.1
2020-03-01 18:00:00 | 11.6
2020-03-01 21:00:00 | 21.3
(8 行)
histogram 関数
histogram 関数はヒストグラムを取得する集約関数です。データの度数分布を確認するのに使います。
例えば、2020 年 3 月 1 日、東京の温度のデータを 3 時間ごとに 12.5 度から 27.5 度まで 2.5 度刻みで 6 つに区切ったヒストグラムを取得してみます。
=# SELECT time_bucket('3 hours', time) AS time_3h,
histogram(temperature, 12.5, 27.5, 5)
FROM conditions
WHERE time >= '2020-03-01'
AND time < '2020-03-02'
AND location = 'tokyo'
GROUP BY time_3h
ORDER BY time_3h;
time_3h | histogram
---------------------+---------------------------
2020-03-01 00:00:00 | {23,16,19,21,29,19,27,26}
2020-03-01 03:00:00 | {21,17,21,25,25,21,29,21}
2020-03-01 06:00:00 | {20,29,14,25,22,24,27,19}
2020-03-01 09:00:00 | {17,24,19,27,18,28,28,19}
2020-03-01 12:00:00 | {20,17,25,22,31,22,21,22}
2020-03-01 15:00:00 | {28,23,17,29,25,18,18,22}
2020-03-01 18:00:00 | {23,14,27,18,30,22,25,21}
2020-03-01 21:00:00 | {20,20,20,32,19,27,25,17}
(8 行)
ヒストグラムは波カッコ {} で囲まれ、カンマ , で区切られた配列として出力されます。配列の各要素が区間内の度数を表します。ここでは、最初の要素が 12.5 度未満、次が 12.5 度以上、15 度未満、その次が 15 度以上、17.5 度未満と続いていき、最後が 27.5 超過のデータの度数になります。
approximate_row_count 関数
approximate_row_count 関数は統計情報を使ってテーブルのおおよその行数を取得する関数です。結果が正確でない代わりに、count 関数に比べて高速に動作します。
\timing コマンドで実行時間を比べると、approximate_row_count 関数が高速なのが分かります。
=# \timing
タイミングは on です。
=# SELECT count(*) FROM conditions;
count
---------
1455480
(1 行)
時間: 246.751 ミリ秒
=# SELECT approximate_row_count('conditions');
approximate_row_count
-----------------------
1455840
(1 行)
時間: 4.144 ミリ秒
おわりに
今回は、TimescaleDB の分析関数として、時間を任意の間隔で丸める time_bucket 関数や、別の列をキーに並び替え、最初、最後の値を取得する first、last 関数を取り上げ、関数の概要や使い方について紹介しました。関数については TimescaleDB Documentation の API Reference もあわせて参照してください。
次回は、時系列データの自動集計や削除、圧縮の機能について紹介する予定です。