本記事では、コンテナ管理ツールであるKubernetes上でPostgreSQLクラスタを動かすためのOperatorと呼ばれるソフトウェアについて概要を紹介します。また、代表的なPostgreSQL OperatorとしてZalandoとCrunchyを紹介します。各ソフトウェアの詳細については以下の記事を参照ください。
Kubernetesの特長
Kubernetesは宣言的設定(マニフェスト)で「あるべき状態」を定義することにより自律的にシステムの管理を行うことが特長です。例えばWebサーバのレプリカ数を3とした場合、現在の状態を定期的にチェックし、サーバの数がそれに満たない場合は新たに起動します。この繰り返しの動作をReconciliation Loop(突合せループ)と呼びます。

Kubernetesでは、これまでシステム管理者が手作業で行っていたサーバの構築と運用管理を自動化することができます。例えば以下のような作業です。
- 定期バックアップ・リストア
- スケールアウト・スケールイン
- ローリングアップデート
Kubernetes上でPostgreSQLを運用するメリット
従来のPostgreSQLデータベースの管理は以下のような問題を抱えていました。
- HA クラスタ環境の構築が面倒
- 監視、バックアップ、障害対策など、運用の手間がかかる
- 負荷の急な増加に即座に対応できない
- データ量増加に伴うディスク容量の不足
- テスト・開発環境の用意が大変
Kubernetes上でPostgreSQLを運用すると以下のようなメリットがあります。
- PostgreSQL HA クラスタ環境を自動的に構築・運用管理できる
- PostgreSQL の検証環境・テスト環境をすぐに構築・削除できる
- バックアップ・リカバリの自動化
- 負荷に応じて、レプリカの台数を増減可能
- Namespace により、PostgreSQL クラスタをサービスごとに隔離可能 (Multi-Tenant)
- 高可用性・耐障害性の向上 (Multi-Cluster、Multi-Zone)
- 必要に応じて、ボリュームサイズ拡張可能
- PostgreSQLのバージョン管理が容易
PostgreSQL Operator
Operatorとは
Operatorとは、Kubernetesの機能を拡張し、様々な運用管理の手順をコードとして記述したものです。Operatorにより、運用の自動化が可能になります。
PostgreSQL Operator
PostgreSQL OperatorはPostgreSQLのデプロイ、バックアップ、障害対応、クラスタ管理、監視などの管理タスクを自動化します。PostgreSQL Operatorの基本的な構成は以下のようになります。
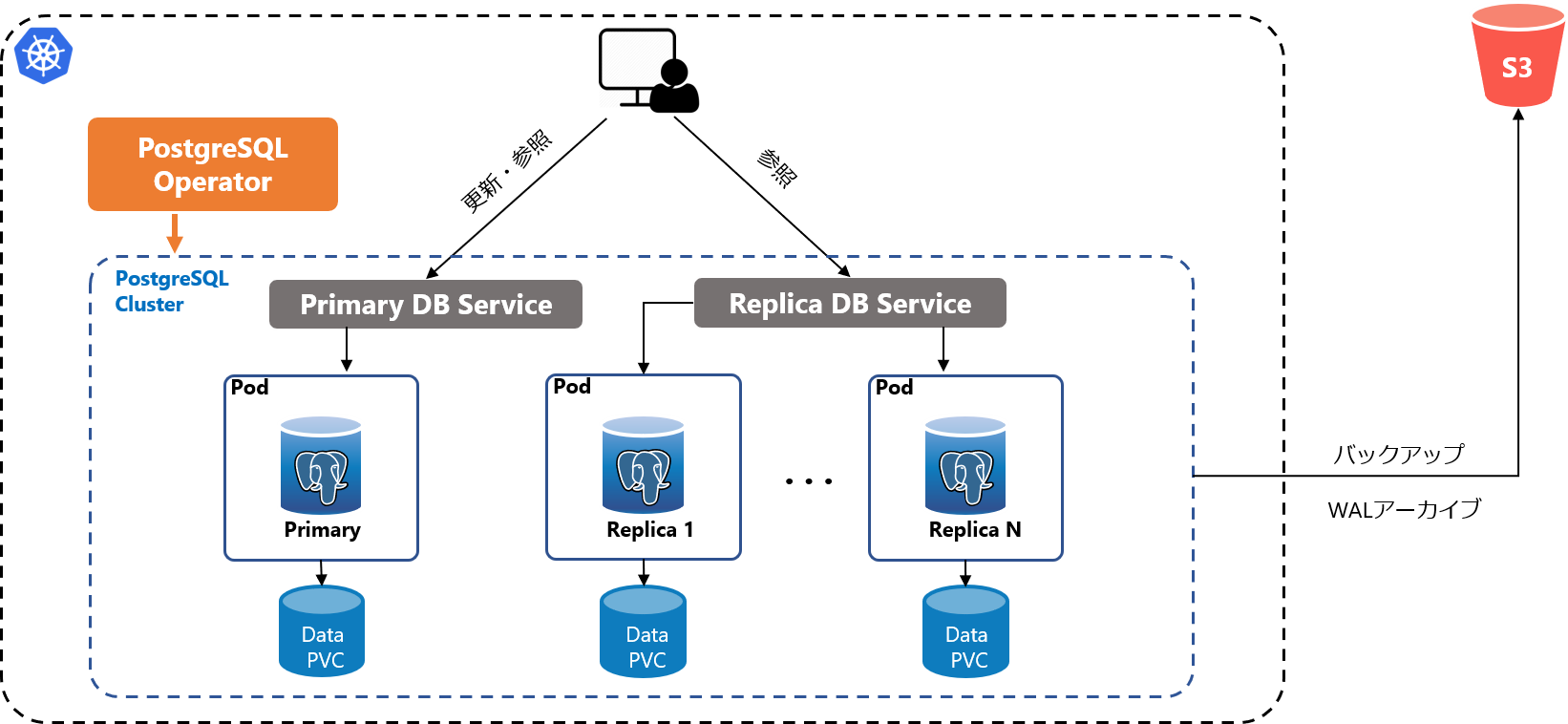
PostgreSQL Operatorの活用例
バックアップ
バックアップジョブを定期的に実行してDBのバックアップを行うことができます。また、WALアーカイブを随時保存します。取得したバックアップやWALアーカイブはAmazon S3(もしくはその互換サービス)に保存できます。
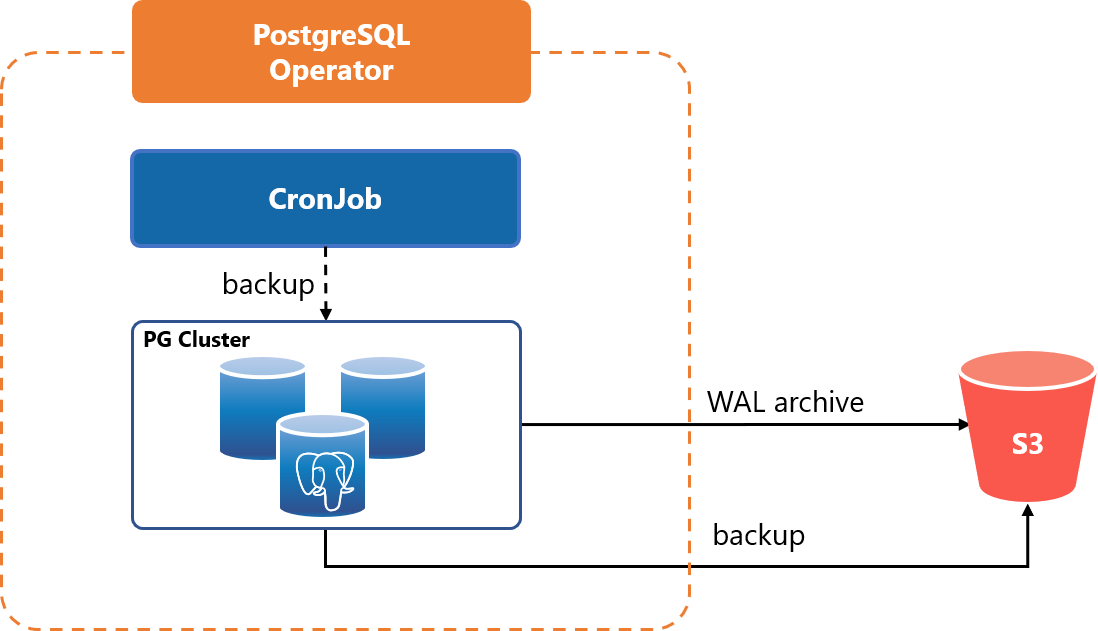
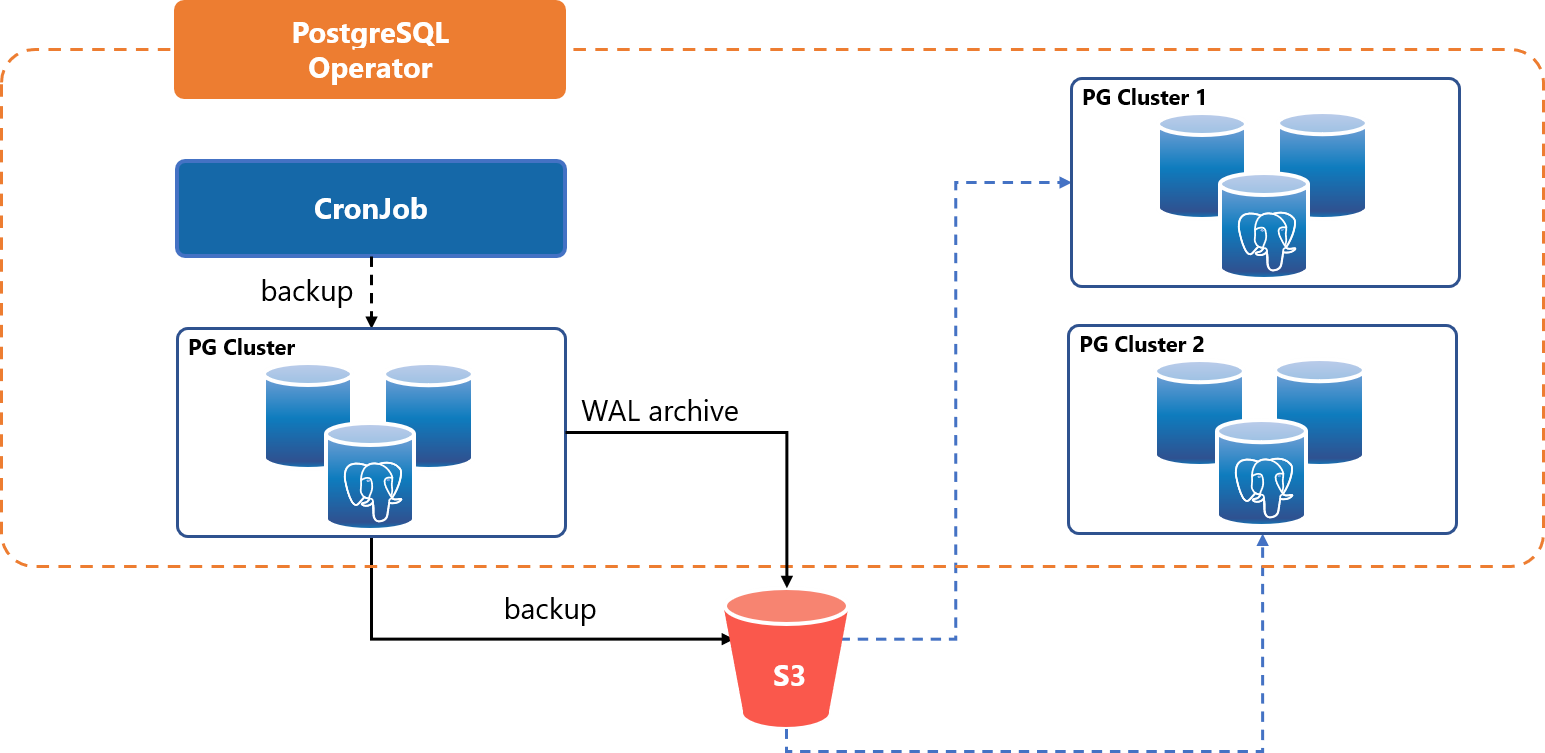
バックアップから複数のテスト環境を複製
保存しておいたWALアーカイブから環境を復元できます。また、これを利用して本番環境のバックアップから複数の環境を複製して、テスト環境として用いるといった用途にも使えます。
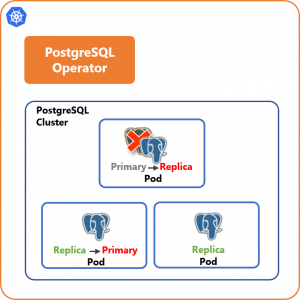
高可用性:クラスタ内フェイルオーバー
プライマリのPodに障害が発生した場合、レプリカの1つが自動的にプライマリに昇格します。元プライマリのPodはレプリカに降格して動作を続けます。また、Podが削除された場合は自動的に新しいPodが再作成されます。
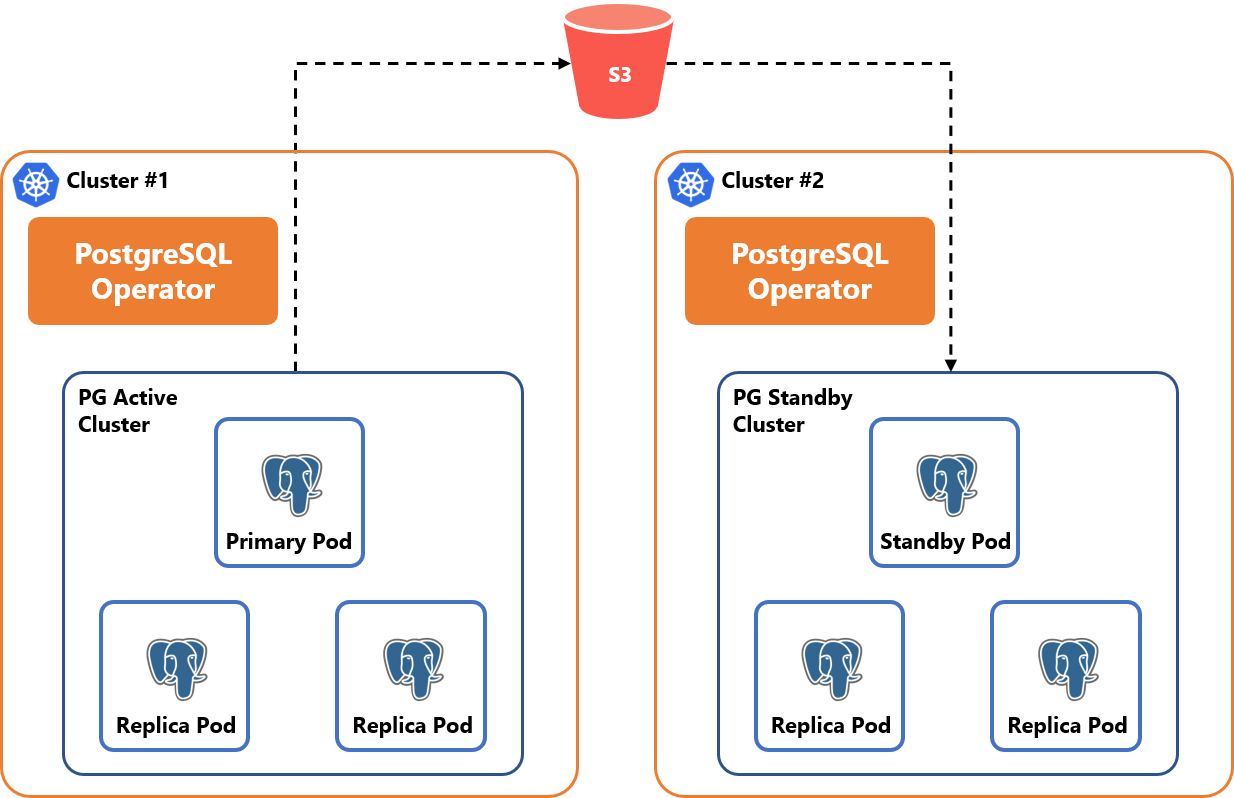
高可用性:クラスタ間フェイルオーバー
2つの独立したKubernetesクラスタ間で、S3に保存したWALアーカイブ経由でPostgreSQLのアクティブ・スタンバイクラスタが同期を取ります。アクティブ側のクラスタに障害が発生した場合は手動でフェイルオーバーを行います。
Kubernetesクラスタを物理的に独立した場所に分散配置することでディザスタリカバリに利用することができます。
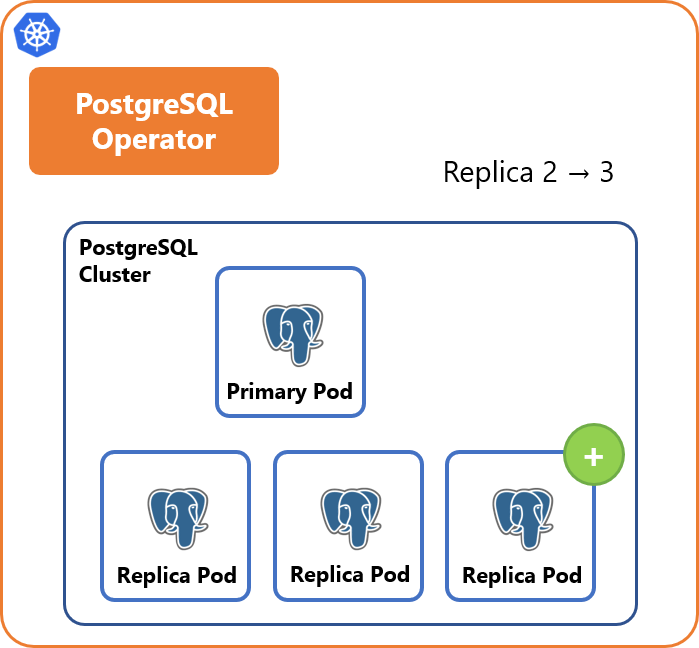
スケーリング
設定変更によりレプリカの数を動的に増減させることができます。レプリカ数を増やした場合、不足分のレプリカPodが自動的に作成されます。レプリカ数を減らした場合は、余分なレプリカPodが削除されます。
ZalandoとCrunchyについて
現在開発が続けられている代表的なPostgreSQL OperatorとしてZalandoとCrunchyがあります。ここではそれぞれの特長について概要を紹介します。各Operatorの詳細については別記事を参照ください。
基本情報
| Zalando | Crunchy | |
| 開発元 | Zalando SE | Crunchy Data |
| ライセンス | MIT License | Apache License 2.0 |
| 対応バージョン | PostgreSQL 9.6+ | PostgreSQL 9.5+ |
| 動作環境 | Amazon AWS, Google Cloud, OpenShift | Amazon AWS, Google Cloud, OpenShift, VMWare Enterprise, IBM Cloud Pak Data |
| URL | https://github.com/zalando/postgres-operator | https://github.com/CrunchyData/postgres-operator |
機能一覧
| Zalando | Crunchy | |
| 自動デプロイ | 〇 | 〇 |
| CLI | × | 〇 |
| GUI | 〇 | × |
| バックアップ | 〇 ※S3対応 | 〇 ※S3対応 |
| リストア | △ ※手動リストアが必要 | 〇 |
| PITR | 〇 | 〇 |
| 自動フェイルオーバ・フェイルバック | 〇 | 〇 |
| Multi-Kubernetes クラスタ | 〇 | 〇 |
| Multi-Zone | 〇 | 〇 |
| スケーリング | 〇 | 〇 |
| 自動アップグレード | 〇 | 〇 |
| ローリングアップデート | 〇 ※バージョンアップに伴う停止時間なし | × ※バージョンアップに伴う停止時間あり |
| コネクションプーリング | 〇 | 〇 |
| 監視 | × | 〇 |
| ボリュームサイズ拡張 | 〇 | 〇 |
それぞれの特長
ZalandoもCrunchyも多くの基本的な機能は共通しており、PostgreSQLクラスタに求められる機能は一通り用意されています。
実績の面では、Zalandoは自社のECサイトで実際に数年運用されている実績があります。CrunchyはPostgreSQLの専門家が開発しているという強みがあります。
Zalandoの基本的にKubernetesの標準的な機能を用いて各種操作を行います。Kubernetesの操作に慣れており、設定追加や変更内容を履歴として残すことを重視するのであればZalandoを選択するメリットがあります。また、ZalandoはGUI(Webインタフェース)が同梱されており、ブラウザから管理を行えます。対してCrunchyは専用の管理コマンドが用意されており、操作が容易で効率的というメリットがあります。
Zalandoはローリングアップデートによりダウンタイムなしでマイナーバージョンアップを行えるメリットもあります。対してCrunchyはアップデート時にある程度のダウンタイムが発生します。
Zalandoは監視などの補助的な機能は標準では用意されておらず、用意されている枠組みを使用してユーザーがある程度作り込みを行う必要があります。対してCrunchyはpgAdmin、ログ解析、監視などの便利な機能が標準で含まれていいるため、導入コストは低くなります。
おわりに
本記事では、Kubernetes上でPostgreSQLを運用するメリット、PostgreSQL Operatorの概要と活用例、ZalandoとCrunchyそれぞれの特長について説明しました。
Kubernetes上のアプリケーションでDBを使用する場合や、多数のDBクラスタを迅速に構築したい場合など、PostgreSQL Operatorは様々な活用方法が想定できます。
ZalandoもCrunchyも発展途上のソフトウェアですが、既に多数の機能が実装されており、今後の発展も期待が持てます。