この記事はSRA Advent Calender 2025 19日目の記事です。
PostgreSQLを使用している方は、トランザクションIDの周回問題という言葉を聞いたことがあるかと思います。トランザクションIDの周回問題は、発生する頻度が少ない一方で、一度発生するとサービスの提供に重大な悪影響を及ぼします。本記事では、PostgreSQLを使用する方にぜひ押さえていただきたい、トランザクションIDの周回問題について解説します。
トランザクションIDとは?
そもそも、トランザクションIDとはどのような場面で使用されているものでしょうか?
前提として、PostgreSQLは追記型のMVCC(多版型同時実行制御)を採用しており、1つの論理的なデータに対して複数の物理的なバージョンの行を持っています。例えば、UPDATEで行が更新されたとき、更新前の行を残しておきつつ、新しく行を追加します。
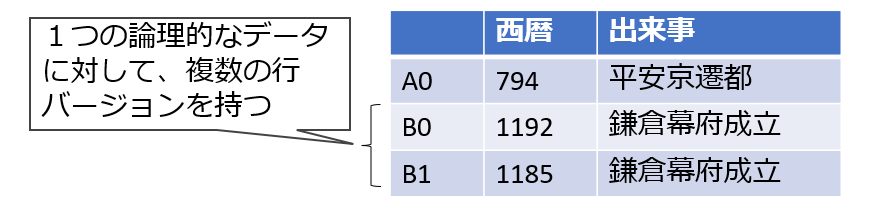
これは、トランザクションの開始タイミングや分離レベルによって、見えるべきデータのバージョンが違うためです。
(更新前の物理行は不要となった段階でVACUUMにより回収されます。)
可視性判断
テーブルにはバージョン違いの行が複数格納されているため、参照処理の実行時には、トランザクションごとに、どのバージョンの行を見せるべきかの可視性判断を行っています。
可視性判断の簡単な例を示します。
トランザクションID 101のトランザクションまでコミット済みの状態から、トランザクションA, トランザクションBが開始しました。トランザクションAがtest2というデータをINSERTし、未コミットの状態です。 この時、トランザクションAからはtest2というデータを見ることができますが、トランザクションBからはtest2というデータは見えてはいけません。
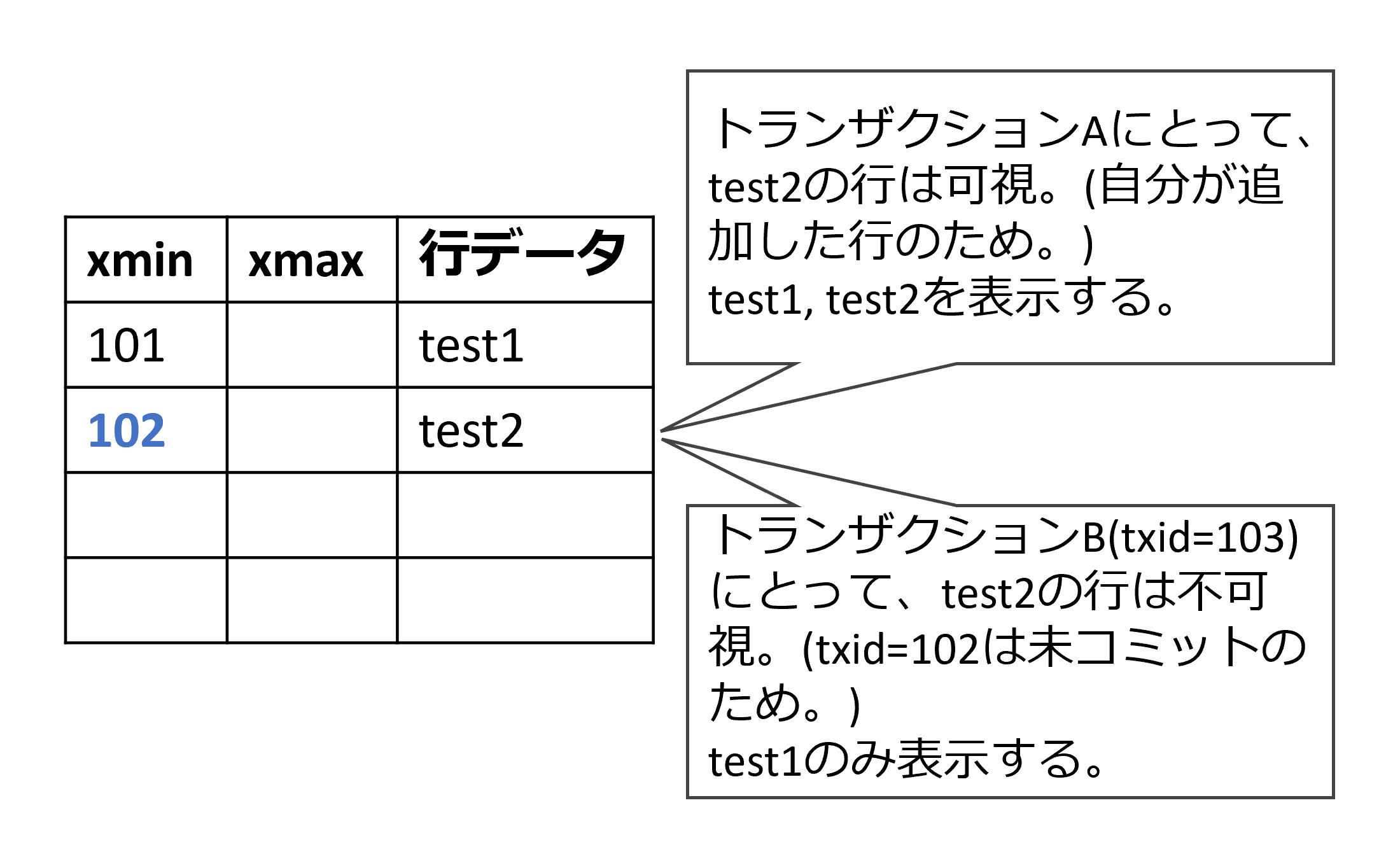
このような可視性判断を行うため、PostgreSQLは、各行のメタデータに、どのトランザクションがその行を追加したかを格納しています。PostgreSQLは内部的に、各トランザクション固有のIDを払い出しています(トランザクションID)。その行を作成したトランザクションのIDをxmin, その行を無効にしたトランザクションのIDをxmaxに格納しています。
=# BEGIN; BEGIN -- 現在のトランザクションIDを確認 =*# SELECT pg_current_xact_id(); pg_current_xact_id 765 (1 row) -- テーブルにデータをINSERT =*# INSERT INTO members VALUES (1, '佐藤', 'sato@example.com'); INSERT 0 1 -- xmin に現在のトランザクションIDが格納されている =*# SELECT xmin, xmax, * FROM members; xmin | xmax | id | name | email ------+------+----+------+------------------ 765 | 0 | 1 | 佐藤 | sato@example.com (1 row)
トランザクションIDの周回問題
このように、可視性判断において重要な役割を担っているトランザクションIDですが、こちらは32bitの非負数であり、約42億で循環します。また、トランザクションIDは、約21億で分割され、基準点より新しい値を未来、古い値を過去として扱います。ですので、約21億を超えてトランザクションIDが払い出されると問題が発生します。
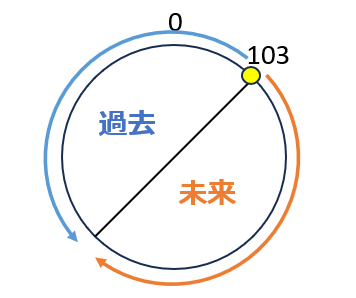
ここで具体的な例を考えてみます。
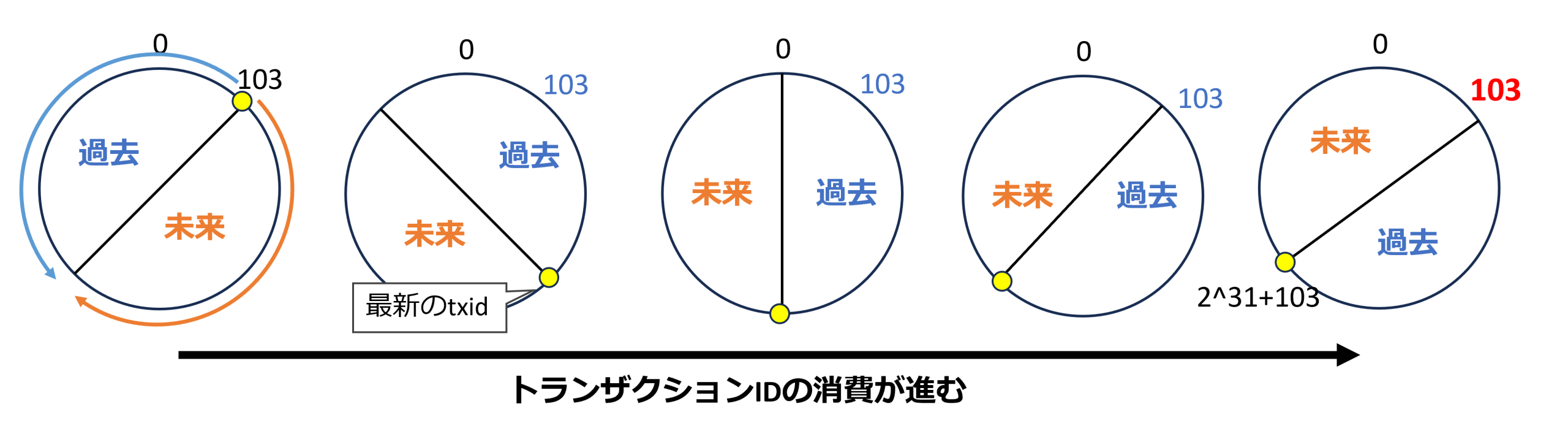
あるテーブルに対し、トランザクションIDが103のトランザクションが行をINSERTし、COMMITしました。
その後、データの変更処理が行われ、トランザクションIDが払い出されてゆきます。
トランザクションIDが進むと、どの値が未来/過去かの判定が変化していきます。
しばらくの間、トランザクションIDが103という値は過去として扱われます。つまり、トランザクションID 103のトランザクションがINSERTした行は過去のものとして扱うことができます。
しかし、トランザクションIDが約21億消費されると、トランザクションIDが103という値は未来として扱われるようになります。
こうなると、いままで過去のトランザクションが作成したものとして認識されていた行は、未来のトランザクションが作成したものとして認識されるようになってしまいます。
このような状態になってしまうと、今まで取り出されていた行が取り出せなくなってしまいます。
これが、トランザクションIDの周回問題です。
長期間運用するようなシステムや、更新量が多いようなシステムであればこの周回問題が発生する危険性は現実的なものです。ただし、PostgreSQLはトランザクションIDが約21億を超えても使用し続けるための仕組み(FREEZE)を用意しています。
FREEZE
トランザクションIDによって未来の行と判断される可能性があるのは、その行を作成したトランザクションより古いトランザクションがまだ実行中の場合です。逆に言うと、その行を作成したトランザクションより古いトランザクションがすでに終了している場合、その行は可視性判断の結果が常に可視となります。そこで、比較するトランザクションIDがどのような値であっても、それより過去に更新された行として扱うようにフラグを立てる処理を行っています。これがFREEZE(凍結)です。
FREEZEはVACUUM実行時に行われています。問題なくFREEZEが行われていれば、周回問題は回避できます。
FREEZEのタイミング
FREEZEのタイミングは以下のパラメータにより制御されています。
- vacuum_freeze_min_age(デフォルト5000万)
- 行に記録されているxminの年代がこの値を超えたらFREEZEを行うようになる
- vacuum_freeze_table_age(デフォルト1.5億)
- pg_class.relfrozenxid(※)がこの年代に達すると、VACUUM時に積極的にFREEZEを行う
- 通常は無効行が存在しているページのみをスキャンするところ、未凍結の行が存在するすべてのページをスキャンして未凍結の行をFREEZEする
- autovacuum_freeze_max_age(デフォルト2億)
- pg_class.relfrozenxidがこのパラメータで指定した年代に達したら、凍結状態でない行を含む可能性のあるテーブルに対し自動VACUUMを開始する
- autovacuum = offでも発生
- vacuum_failsafe_age(デフォルト16億)
- pg_class.relfrozenxidがこの年代に達すると、トランザクションID周回回避のために全力でVACUUMを行うようになる
- コストベースの遅延を行わず、インデックスのバキュームなど緊急でない作業はスキップする
- バッファアクセスストラテジは無効になり、VACUUMが共有バッファのすべてを自由に使用するようになる
※pg_classには、そのテーブル内ですでにFREEZEが完了したトランザクションIDを格納するrelfrozenxidという列が存在します。relfrozenxidに格納されているものより古いトランザクションIDはすべてFREEZEが完了しています。pg_databaseにもdatfrozenxidという列が同様に存在しています。
周回問題発生時の動作
しかしながら、FREEZEを阻害するような要因があると、やはり周回問題が発生してしまいます。実行中のトランザクション以後のトランザクションIDはFREEZEすることができないので、ロングトランザクションは典型的な阻害要因になります。その他、孤児となったプリペアドトランザクション(2相コミット)や、使用されていないレプリケーションスロットも阻害要因になります。
周回問題が近づくと、PostgreSQLはどのような動作になるのでしょうか?
まず、使用可能なトランザクション数が残り4000万を切ると、データ変更処理を行った際にWARNINGメッセージが出力されるようになります。これはWARNINGですので、データ変更処理自体は行われます。
WARNING: database "mydb" must be vacuumed within 39985967 transactions
HINT: To avoid XID assignment failures, execute a database-wide VACUUM in that database.
WARNINGメッセージが発生した後もFREEZEを阻害する要因を排除できず、周回までのトランザクション数が残り300万未満になると、PostgreSQLは新しいトランザクションIDの割り当てを拒否するようになります。
実は、トランザクションIDはそのトランザクションで初めてデータ変更処理が行われたときに割り当てられるものですので、つまりはデータの変更処理が不可能になります。
ERROR: database is not accepting commands that assign new XIDs to avoid wraparound data loss in database "mydb"
HINT: Execute a database-wide VACUUM in that database.
補足
以前のドキュメントでは、周回問題が発生したときの挙動として、以下のように記述されていました。
システムは停止し、新しいトランザクションの起動を拒絶します。
しかしながら、実際にはデータベースは停止することはありません。参照処理のみであれば実行することができます。(もっとも、更新処理は不可能になる以上サービスの提供に重大な悪影響を及ぼすことには違いありません)
周回問題発生時の対処法
周回問題が発生し、データが更新できないような状態になってしまったらどうしたらよいのでしょうか?
まずは、FREEZEを阻害する要因を特定する必要があります。
--ロングトランザクション SELECT * FROM pg_stat_activity ORDER BY xact_start LIMIT 10; -- 古いプリペアドトランザクション SELECT * FROM pg_prepared_xacts ORDER BY prepared LIMIT 10; --使用されていないレプリケーションスロット SELECT * FROM pg_replication_slots;
FREEZEを阻害する要因を特定したら、それを取り除いてください。
--ロングトランザクション
SELECT pg_terminate_backend(《PID》);
--古いプリペアドトランザクション
ROLLBACK PREPARED '《transactionid》';
--使用されていないレプリケーションスロット
SELECT pg_drop_replication_slot('《スロット名》');
次に、通常のVACUUMを実行します。データベース全体に行っても良いですし、最も古いトランザクションIDを持つテーブル(relfrozenxidが最も古いテーブル)に対して個別に実行してもよいです。注意点として、VACUUM FULLは実行してはいけません。VACUUM FULLはトランザクションIDが必要な処理のため、周回問題発生時には失敗します。また、VACUUM FREEZEも実行しないでください。「通常の操作を回復するために必要な最小限の作業以上の作業を行う」ためです。
補足
以前のバージョンでは、「postmasterを停止してVACUUMをシングルユーザーモードで実行する」ように指示がありました。
PostgreSQLを使い慣れている方であれば、見覚えのある方も多いのではないかと思います。
しかしながら、少なくともVACUUMにフェイルセーフモードが導入されたPostgreSQL 14以降では、シングルユーザーモードにすることは不要です。
シングルユーザーモードにするとVACUUMに時間がかかるうえ、VACUUMのモニタリングも難しいことから、PostgreSQL 14以降をお使いの場合はシステムは停止せずに通常のVACUUMを行ってください。
モニタリング
周回問題が発生すると重大な影響を及ぼすことから、PostgreSQLを使用する場合は周回問題が発生していないか、モニタリングすることが重要です。
pg_database, pg_classのdatfrozenxid,relfrozenxid列に対し、age関数(現在のトランザクションIDと引数として与えたトランザクションIDとの差を求める関数)を使用して、FREEZEが完了していないトランザクションIDがどの程度あるかを監視します。
SELECT datname, age(datfrozenxid) FROM pg_database ORDER BY age DESC;
SELECT relname, age(relfrozenxid) FROM pg_class WHERE relkind IN ('r', 'm') ORDER BY age DESC;
上記SQLを定期的に実行し、ageが増加傾向にあれば、FREEZEが阻害されている可能性を疑ってください。FREEZEが阻害されている要因を探して、対処してください。
まとめ
本記事では、PostgreSQLの周回問題についての解説を行いました。FREEZE処理が上手くいっている場合は、周回問題は発生しませんが、FREEZEを阻害するような要因(ロングトランザクション、孤児となったプリペアドトランザクション、使用していないレプリケーションスロット)が存在していると最終的にデータの変更処理が不可能になります。そうならないように、定期的にモニタリングを行うことが重要です。