前回の記事「ストリーミングレプリケーションの紹介(1)」では、PostgreSQL におけるストリーミングレプリケーションの基本機能と構成手順を紹介しました。
ここでは引き続き、ストリーミングレプリケーションの実践的な機能と設定を解説します。
本記事で扱う題目は以下の通りです。
記事内の各リンクについて、特記のないものはすべて PostgreSQL16.4 文書(弊社ドメイン)の該当項目へのリンクとなっております。
同期と非同期
同期/非同期の概要
PostgreSQL のストリーミングレプリケーションには、同期と非同期、2通りのモードがあります。
同期と非同期の違いを簡単に言えば、スタンバイで WAL がどのような状態になったらクライアントにコミット完了を通知するかです。
以下にそれぞれの特徴を示します。
| 非同期モード | |
|---|---|
| 通知タイミング | スタンバイで行われる WAL の処理を待たずに、クライアントにコミット完了を通知する |
| データの整合性 | プライマリでのコミットがスタンバイでの処理を待たないため、プライマリ障害時にデータ損失のリスクがある |
| 処理性能 | レプリケーションを待機する動作が無いため、同期モードに比べて書き込み処理のレスポンスが速い |
| 同期モード | |
|---|---|
| 通知タイミング | synchronous_commit で指定された段階まで、スタンバイ側で WAL 処理が完了したことを待ってから通知する |
| データの整合性 | プライマリ側でコミット済のトランザクションの内容はプライマリ・スタンバイ両方に書き込まれている |
| 処理性能 | レプリケーション完了まで待機が発生するため、レスポンスが遅くなる可能性がある |
非同期モードの場合、スタンバイサーバへの複製を待たずにコミット完了するため、プライマリサーバの書き込み性能にほとんど影響を与えないことが特徴です。
しかしながら、プライマリサーバがクラッシュした場合、コミットされた一部のトランザクションがスタンバイサーバに複製されずデータ損失を引き起こす可能性があります。
データ冗長性の実現という観点では、これは大きなリスクとなることに留意してください。
対して同期モードでは、トランザクションのコミットで提供される永続性の保証範囲が拡大されます。
これにより、プライマリサーバのクラッシュ時にも、スタンバイサーバにおいては指定した同期レベルにおいて、データ損失リスクを大きく低減できることが強みとなります。
しかし、コミット完了までに適宜スタンバイでの処理を待つことになるため、プライマリのレスポンスは非同期に比べ遅くなります。
同期と非同期のそれぞれ動作の違いを以下の図に示します。
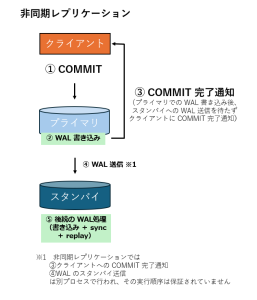
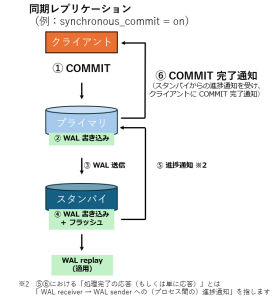
なお、PostgreSQL のストリーミングレプリケーションは、デフォルト設定では非同期となっています。
同期と非同期の設定パラメータ
ストリーミングレプリケーションが同期/非同期のどちらのモードで動作するかについては、
主に以下のパラメータによって制御されます。
コミット完了の通知までに、完了しなければならない WAL 処理の段階を指定する
同期対象として扱うスタンバイサーバを指定する
これらのパラメータはプライマリ側の postgresql.conf で設定します。
ストリーミングレプリケーションがデフォルトで非同期なのは、それぞれのパラメータのデフォルト値が「#synchronous_commit = on」「#synchronous_standby_names = ”(空文字)」であるためです。(詳細は synchronous_standby_names の項)
同期モードを指定する場合は、「どのスタンバイを同期対象として扱うか」を synchronous_standby_names で指定し、同期対象スタンバイに対して「どの段階まで WAL 処理の完了を待つか」を synchronous_commit で制御します。
ストリーミングレプリケーションが既に設定されている場合であれば、同期レプリケーションの設定には必要な追加設定は「synchronous_standby_namesを空でない値に設定すること」だけです。
synchronous_commit で同期レベルを off 以外に設定することも必要ですが、前述の通りこれはデフォルト値で on ですので、通常は変更する必要はありません。
詳細については、同期/非同期の基本設定に関するマニュアルをご確認ください。
synchronous_commit
synchronous_commit は、トランザクションのコミットを完了とみなすタイミングを制御するパラメータです。
具体的には、プライマリで行われた更新系トランザクションのコミットがクライアントに「成功」の報告を返す前に、スタンバイ側でどれだけの WAL 処理を完了する必要があるかを決めることで、永続性の保証度合が決まります。
代表的な設定値は以下の通りです。
| 設定値 | 説明 |
|---|---|
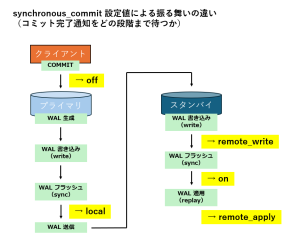
| remote_apply | スタンバイ側で WAL が適用(replay)されるまで待つ |
| on | スタンバイで WAL がディスクに書き込み(sync)されるまで待つ(デフォルト) |
| remote_write | スタンバイで WAL が書き込まれるまで待つ(sync は待たない) |
| local | プライマリでの WAL 書き込みのみ待つ |
| off | WAL の書き込みを待たずにコミット完了とする |
一般的に、プライマリ障害時におけるコミット済トランザクションの更新欠損を極力回避したい場合は on が選択され、レスポンス性能とのバランスを取りたい場合は remote_write が選択されることが多いです。
remote_apply は、スタンバイ側で WAL が適用(replay)されるまで、プライマリでのコミット通知を待つ設定です。
これにより、スタンバイ側での参照クエリは、プライマリの最新データと整合性を保つことができますが、コミット完了までのレイテンシは on や remote_write と比べて大きくなる点には注意してください。
なお、local や off を指定した場合、synchronous_standby_names を設定していても実質的には非同期動作となります。
それぞれのパラメータにおける動作の違いを以下の図を示します。

また、synchronous_commit はいつでも変更可能であるため、SET を用いることで同一サーバ内でもトランザクションごとに同期レベルを使い分けることができます。
例えば、デフォルトが同期コミットの場合でも、特定のトランザクションのみを非同期でコミットしたい場合には、トランザクション内で「SET LOCAL synchronous_commit TO OFF;」を実行することで、そのトランザクションに限り非同期でレプリケーションされます。
パラメータの詳細はマニュアルをご覧ください。
synchronous_standby_names
synchronous_standby_names は、同期レプリケーションの対象とするスタンバイサーバ名を指定するパラメータです。
デフォルトの設定値は空文字「’ ‘」となっており、同期対象を指定しない設定になっています。
このように同期対象を指定しなければ、synchronous_commit が off 以外の有効な値であっても、実質的な動作は非同期の挙動となります。
同期対象となるスタンバイサーバを指定する場合は、以下のように設定します。
synchronous_standby_names = 'standby1'
この場合、application_name が standby1 であるスタンバイが同期対象となります。
application_name には、スタンバイ側の postgresql.conf で設定される primary_conninfo において、「application_name = standby1」のように指定された値(サーバ名)が使われます。
この設定は、指定するサーバがスタンバイとして起動している場合(standby.signal が存在する場合)に有効です。
二つ以上の同期スタンバイサーバ名を指定することで、より高いレベルでの高可用性とデータ損失に対する保護が期待できます。
例えば、複数のスタンバイが存在する場合、次のように指定することが可能です。
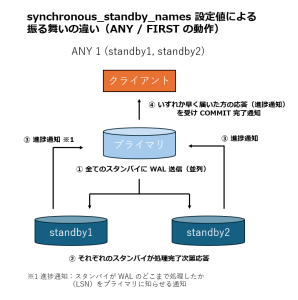
synchronous_standby_names = 'ANY 1 (standby1, standby2)'
ここで指定した ANY 1 は「standby1 と standby2 のいずれか 1 台が応答すれば同期条件を満たす」という意味になります。
これにより、いずれか一方のスタンバイに障害が発生した場合でも、書き込みが停止する事態を回避できます。
また、ANY 1 ではなく FIRST 1 を指定した場合は、スタンバイ名の記述順がそのまま優先順位となり、リストの先頭にあるスタンバイから順に同期対象として選択されます。
synchronous_standby_names = 'FIRST 1 (standby1, standby2)'
FIRST 1 の場合は、優先スタンバイが応答しない場合でも、wal_sender_timeout により接続は切断され、次に優先度の高いスタンバイが同期対象として選択されます。
そのため FIRST 1 は、「特定のスタンバイを優先しつつ、障害時には自動的に次候補へ切り替えたい」場合に有効な指定方法です。
ANY 1 と FIRST 1の挙動の違いは、以下の図のようになります。
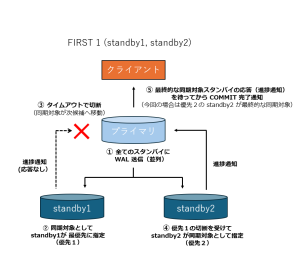
なお、synchronous_standby_names を単にスタンバイ名をカンマ区切りで列記した場合は、暗黙的に FIRST 1 と同じ振る舞いになります。
synchronous_standby_names = 'standby1, standby2'
また、ANY 2 や FIRST 2 のように台数を 1 以上で指定した場合は、指定した台数のスタンバイに対して、synchronous_commit で指定された段階まで WAL の処理が完了するのを待ってから、クライアントにコミット完了が通知されます。
パラメータの詳細はマニュアルをご覧ください。
同期レプリケーション設定時の注意点
ここまでの説明の通り、同期レプリケーションは同期対象スタンバイからの応答(進捗通知)を必ず待ってから commit を完了するという仕組みになっています。
ですので、指定した同期スタンバイが応答しない場合は commit が完了せず、プライマリでの書き込み処理ができなくなります。
こうした状況を回避するため、同期対象のスタンバイ台数、ネットワーク遅延、スタンバイ側の性能などを考慮し、安定した稼働が実現できる範囲で設計する必要があります。
高可用性を目的とする場合でも、環境での実現性を踏まえたうえで、必ずしも常に同期レプリケーションが最適とは限らない点には注意してください。
コンフリクト
コンフリクトの概要
コンフリクトは直訳では「衝突」を意味し、PostgreSQL においては主にストリーミングレプリケーション環境において、スタンバイサーバ上で発生する、プライマリ側の更新処理とスタンバイ側で実行される参照クエリとの競合を指します。
PostgreSQL の日本語マニュアルでは、このような競合が起こる状況を「コンフリクト」と表現し、またそうした事象が発生することを「コンフリクトする」と表現しています。
コンフリクトが発生すると、解消のためにスタンバイ上で実行中の問い合わせがキャンセルされたり、セッションが終了されたりする場合がありますので、常に発生する可能性と解消方法を想定して運用することが必要となります。
以下の解説と併せて、マニュアルの該当項目「問い合わせコンフリクトの処理」もご覧ください。
コンフリクトが発生する代表的なケース
代表的なコンフリクトの例として、以下のようなケースがあります。
- スタンバイで長時間実行されている参照クエリが存在する
- プライマリで VACUUM や DELETE が実行され、不要となった行を削除しようとする
- スタンバイ側では、まだ参照中のためその行を削除できない
このようなコンフリクトが起きると、スタンバイでは WAL 適用が一時的に妨げられ、
一定時間待機した後、WAL 適用を優先するため、参照クエリがキャンセルされます。
また、コンフリクトは特にホットスタンバイの設定が「hot_standby = on(デフォルト)」と有効になっている環境で問題となります。
コンフリクト発生時のエラーメッセージ
コンフリクトが発生すると、スタンバイ側では以下のようなエラーが出力されます。
ERROR: canceling statement due to conflict with recovery DETAIL: User query might have needed to see row versions that must be removed.
このエラーは異常動作ではなく、スタンバイでの参照とリカバリ処理の整合性を保つための正常な挙動です。
コンフリクトへの対処方法
コンフリクトへの対処方法としては、主に以下の選択肢があります。
-
「スタンバイで実行するクエリを短時間で終わるものにする」
スタンバイで実行される参照クエリの実行時間が短ければ、プライマリ側で生成された WAL を適用する際に競合が発生する可能性は低くなります。
特にスタンバイを参照用途で利用する場合は、長時間トランザクションや大規模な集計処理を避ける設計とすることで、コンフリクトによるクエリキャンセルの発生頻度を抑えることができます。
-
「パラメータでスタンバイ側の挙動を調整する」
代表的なパラメータとして、max_standby_streaming_delay や hot_standby_feedback が挙げられます。
これらパラメータを調整することで、コンフリクト発生時のスタンバイの振る舞いを制御できます。
例えば、スタンバイでの参照を優先したい場合は待機時間を長く設定したり、スタンバイ側の参照情報をプライマリに通知することで、クエリキャンセルの発生を抑制することが可能です。
なお重要な注意点ですが、これらのパラメータ調整によってコンフリクトは抑制できても、完全に防ぐことはできません。
状況によっては、スタンバイ側のクエリが ERROR によりキャンセルされるだけでなく、FATAL エラーとして接続自体が切断される場合もあります。
-
「コンフリクトによる影響をあらかじめ想定した運用を検討する」
前述のように、コンフリクトを完全に防ぐことはできないため、スタンバイを参照用途として利用する場合は、コンフリクトでクエリがキャンセルされる可能性を前提とし、エラー発生時にはクエリを再実行できる運用設計も有効です。
特にレポート生成やバッチ処理など、即時性が必須でない参照処理では、スタンバイ上のクエリのキャンセル回避を過度に追求せず、プライマリでの VACUUM が適切に進むことや、更新のスタンバイ反映を速やかに行うことを重視する運用も、現実的な選択肢です。
以下では、これら対処方法のうち、スタンバイ側の挙動を調整するためのパラメータを紹介します。
max_standby_streaming_delay
max_standby_streaming_delay:適用されようとしている WAL エントリと競合するスタンバイクエリをキャンセルするまで待機する時間を決定
スタンバイが WAL の適用(リカバリ、replay)をどれだけ遅らせて、競合している参照クエリの終了を待つかを指定するパラメータです。
言い換えるならば、「スタンバイ上の参照クエリがキャンセルされにくいこと」と、「プライマリでの更新をスタンバイに速やかに反映させること」のどちらを優先とするかを決める設定です。
本パラメータの値を大きくすると、スタンバイ側の参照クエリはキャンセルされにくくなります。
ただし、スタンバイでの WAL の適用(リカバリ処理)が遅れるため、プライマリからスタンバイへの反映に時間がかかる場合があります。
一方、値を小さく設定すると遅延(プライマリとのデータ状況の相違)は抑えられるものの、コンフリクト発生時にクエリが早期にキャンセルされやすくなります。
hot_standby_feedback
hot_standby_feedback:ホットスタンバイがスタンバイサーバ上で現在処理を行っている問い合わせについて、プライマリまたは上位サーバにフィードバックを送るか否かを指定
hot_standby_feedback を有効にすると、スタンバイが参照中の行バージョン情報をプライマリに通知することで、コンフリクトの発生を抑制します。
ただしこれに伴い、プライマリ側では VACUUM による不要な行バージョンの回収が遅れる場合があり、不要な行バージョンが残りやすくなることで、テーブルやインデックスの肥大化につながる可能性があります。
ですので、これらの設定は「スタンバイ上の参照クエリがキャンセルされにくいこと」と、「プライマリ側で VACUUM が適切に進み、テーブルの肥大化を抑えること」とのトレードオフとなります。
統計情報ビュー
レプリケーション状態の確認
ストリーミングレプリケーションの状態は、PostgreSQL が提供する統計情報ビューを用いて確認できます。
ここでは、運用時に特に重要となるビューを紹介します。
レプリケーションは高可用性や災害対策を目的とする場合がほとんどですので、運用開始以降もこれらのビューを継続的に監視することで、レプリケーションが異常なく動作していることを確認しながら運用することが、レプリケーションの目的を実現するためには必須です。
そういった意味では、単に「切れていないか」だけでなく、遅延が拡大していないか、同期設定が想定通りかといった観点で、定期的に監視することが重要です。
pg_stat_replication(プライマリ側)
pg_stat_replication は、プライマリから見たスタンバイの接続状態を確認するためのビューです。
本稿では本ビューのうち、特に有用な列を抜粋いたします。
ビューの全ての列や抜粋した列の詳細を確認する場合は、マニュアル該当項を参照してください。
pg_stat_replication ビューの参照は、任意のデータベースにpsqlなどで接続し、以下のような SELECT 文を実行します。
SELECT pid, application_name, state, sync_state, write_lag, flush_lag, replay_lag FROM pg_stat_replication;
本ビューでは、まずは以下の項目を確認するとよいでしょう。
| パラメータ | 説明 |
|---|---|
| pid | WAL 送信プロセスのプロセスID |
| application_name | スタンバイ接続時に指定された識別名 |
| state | WAL送信サーバの現在の状態 streaming であれば、WAL が正常に送信 |
| sync_state | 同期レプリケーションの状態 async(非同期) / sync(同期) / quorum(詳細は後述)など |
| write_lag flush_lag replay_lag |
それぞれプライマリとスタンバイ間の遅延状況(単位は秒) |
これらの項目を監視することで、ストリーミングレプリケーションの状況が正常か確認することができ、なんらかレプリケーションに異常が見られる場合は、
原因を特定するために有用な情報となることも期待できます。
例えば、state が streaming 以外の場合はレプリケーションが正常に行われていない可能性があり、WAL の送信や接続に何らかの問題が発生していることが考えられます。
この場合、スタンバイ側の pg_stat_wal_receiver ビューや PostgreSQL のログと突き合わせて確認することで、原因の切り分けを行うことができます。
他には、*_lag の値が継続的に増加している場合は、性能やネットワークに問題がある可能性があるというふうに見込みをつけるのに役立ちます。
(バックアップ・VACUUM時などの一時的な増加は問題ないと言えます)
-
補足:sync_state の quorum について
pg_stat_replication の sync_state 列に quorum と表示される場合、そのスタンバイが「クォーラム方式での同期対象の候補」に含まれている状態を表します。
PostgreSQL のストリーミングレプリケーションにおいては、このクォーラム方式は「synchronous_standby_names に ANY n と指定した際の挙動」と捉えてください。
前述の通り、ANY n を指定した場合、指定した台数(N 台)以上のスタンバイからの進捗通知を待ってから、プライマリはトランザクションの COMMIT を完了します。
このとき、「sync_state = quorum」と表示されたスタンバイは、 「(必要数の応答)n 台を満たすための候補となる集合の一部」 であることを示します。
つまり、quorum は明示的に指定された同期対象ではなく、ANY n 指定時に同期対象となり得るスタンバイ候補の一つであることを示す状態です。
pg_stat_wal_receiver(スタンバイ側)
pg_stat_wal_receiver は、スタンバイ側から見た WAL 受信状態を確認するためのビューです。
このビューは、主にスタンバイ側でレプリケーションが停止していないかを確認する際に有用です。
前項と同じく、本稿では本ビューのうち、特に有用な列を抜粋いたします。
ビューの全ての列や抜粋した列の詳細を確認する場合は、マニュアル該当項を参照してください。
pg_stat_wal_receiver ビューの参照は、任意のデータベースにpsqlなどで接続し、以下のような SELECT 文を実行します。
SELECT status, receive_start_lsn, received_lsn FROM pg_stat_wal_receiver;
本ビューでは、まずは以下の項目を確認するとよいでしょう。
| パラメータ | 説明 |
|---|---|
| status | プライマリからの WAL の受信状態 streaming となっていれば受信し続けている状態 |
| receive_start_lsn | スタンバイが WAL の受信を開始した位置 |
| received_lsn | 現在までに受信した WAL の最終位置 |
これらの項目を確認することで、スタンバイ側がプライマリから WAL を正しく受信できているかを把握することができます。
特に、status が streaming であり、received_lsn が継続的に進んでいる場合は、WAL の受信に関しては問題が発生していないと判断できます。
一方で、status が streaming であっても received_lsn が長時間変化しない場合は、プライマリ側での WAL 生成が少ない、あるいはネットワークや性能面での問題が発生している可能性が考えられます。
このような場合は、プライマリ側の pg_stat_replication ビューや PostgreSQL のログと突き合わせて確認することで、より詳細な原因の切り分けを行うことができます。
-
補足:WAL の LSN の概説
LSN(Log Sequence Number)とは、平たく言えば WAL の通し番号のようなもので、前述のパラメータにおいては「WAL のどこまで処理が進んでいるかを表す番号」を意味します。
プライマリとスタンバイの関係で考えると、プライマリでは「WAL を生成し、LSN が増えていく」のに対し、スタンバイでは「WAL を受信・適用し、プライマリの LSN を追いかける」という流れになります。
そのため、両者の LSN の差が小さいほど、スタンバイは新しい状態を保っていると言えます。
前述のビューを監視するにあたっては、細かな数値の意味を正確に理解しなくとも、まずは「値が進んでいるか」「止まっていないか」を見るだけでも、レプリケーションの状態把握には役立ちます。
フェイルオーバー
PostgreSQL本体でできること・できないこと
ストリーミングレプリケーションは高可用性構成の基盤となる技術ですが、PostgreSQL 本体には以下の機能は含まれていません。
- 障害検知
- 自動フェイルオーバー
- スプリットブレイン防止
そのため、フェイルオーバーの設計と運用は、外部ツールを利用したり、独自にスクリプトを組むなどの対応が必要となります。
本記事では、フェイルオーバーに関わる概要を説明します。
外部ツール利用やスクリプト構築についての詳細は、続編記事にて紹介予定のため、ここでは割愛いたします。
手動フェイルオーバーの基本
前回の記事でも紹介した通り、スタンバイは pg_ctl promote などの手段でプライマリへ昇格できます。
pg_ctl promote -D データディレクトリのパス
昇格後は、該当スタンバイは新しいプライマリとして更新を受け付けるようになります。
フェイルオーバー時の注意点
フェイルオーバー時に特に注意すべき点は以下の通りです。
- 旧プライマリが完全に停止していることを確認する
- 同時に複数のプライマリが存在しないようにする
- アプリケーションの接続先を確実に切り替える
これらが守られない場合、フェイルオーバー処理自体は正しく完了しても、スプリットブレイン(データ不整合)が発生する危険性があります。
※スプリットブレイン:複数のノードが同時にプライマリとして動作し、互いに異なる更新を受け付けてしまう状態
なお、同期レプリケーション構成であってもすべてのスタンバイが、常にプライマリの最新データと整合した状態になるとは限りません。
synchronous_standby_names の設定(ANY / FIRST)やスタンバイの接続状態によっては、同期条件を満たしていないスタンバイが存在する可能性があります。
そのため、フェイルオーバー時には「どのスタンバイが実際に同期対象であったか」、およびそのスタンバイが「昇格対象が最新の WAL を反映しているか」を必ず確認するようにしてください。
障害検知
障害検知として一般的な方法としては、定期的な ping による疎通確認や、PostgreSQL の待ち受けポートへの接続確認、もしくは pg_isready を用いたプロセスの死活監視などが考えられます。
例えば、そもそもサーバ自体に到達できない場合は OS やネットワーク障害が疑われます。
もしくはポートには接続できても pg_isready が失敗する場合は、PostgreSQL のプロセス停止や応答不能が疑われるといったように、障害を切り分けることができます。
このように、複数の観点から段階的に監視を行うことで、単純な通信断とデータベース障害とを区別しやすくなり、フェイルオーバーの判断を誤るリスクを低減できます。
自動フェイルオーバーを行う場合
自動フェイルオーバーを実現したい場合は、以下のような外部ツールとの組み合わせが一般的です。
- Pacemaker + Corosync
- pgpool-II
これらに関しての導入・操作手順は今回割愛し、次回以降の続編でご紹介する予定です。
自動フェイルオーバーを導入する場合、いずれもストリーミングレプリケーション単体の挙動を理解していることが前提となります。
まずは手動でのフェイルオーバー手順を確実に把握し、その後に自動化を検討するのが安全です。
最後に
本記事では、ストリーミングレプリケーションにおける同期設定、コンフリクト、監視、フェイルオーバーといった運用面で重要となるポイントを紹介しました。
ストリーミングレプリケーションは強力な機能ですが、その特性を正しく理解し、用途に応じた設計・運用を行うことが不可欠です。
次回以降では、pgpool-II や Pacemaker + Corosync を利用した自動フェイルオーバーの構築についての情報をお伝えする予定です。