この記事は SRA Advent Calendar 2025 18 日目の記事です。
PostgreSQL には様々なバックアップの方法が提供されています。
それぞれのバックアップの方法は利点が違い、運用方法も手順も異なります。
今回はバックアップ方法の簡単なおさらいと、PostgreSQL 17 で標準機能として追加された増分バックアップについて紹介します。
PostgreSQLのバックアップの種類
PostgreSQL のバックアップは大きく論理バックアップ と 物理バックアップの 2 種類に分類できます。
論理バックアップ
SQL レベルでデータを取得する方式です。
CREATE TABLE や INSERT 文などで現在のデータベースの状態を再現できるファイルを生成します。
異なるOSアーキテクチャ間や PostgreSQL メジャーバージョン間でもリストア可能という柔軟性が大きな利点です。
物理バックアップ
データベースクラスタ全体のディレクトリを丸ごと保存する方式です。
Linux の cp コマンドや PostgreSQL 標準ツールである pg_basebackup を利用できます。
pg_basebackup では PITR(Point-In-Time Recovery)や PostgreSQL 17 で追加された 増分バックアップ を利用できる点が最大の特徴です。
今回は、この「増分バックアップ」について詳しく紹介します。
増分バックアップとメリット

増分バックアップは、ある時点で取得したフルバックアップをベースとし、その後に変更された部分だけを保存する方式です。
たとえば、10 TB のデータベースを毎日 30 日分フルバックアップで保存すると、
10 TB × 30 日 = 300 TB もの容量が必要になります。
しかし増分バックアップであれば、
初日のフル 10 TB + 毎日の変更分のみを保存すればよく、大幅なストレージ削減が可能です。
上記の図は毎日の変更分を10GBと想定した場合の比較図となります。
また、バックアップ取得時間も短縮できます。
フルバックアップではすべてのデータをコピーするため時間がかかりますが、増分バックアップは変更分だけを取得するためバックアップ時間の短縮につながります。
また結果としてサーバー負荷の軽減にも寄与します。
増分バックアップの手順
従来、PostgreSQL で増分バックアップを行いたい場合は、サードパーティツールである pg_rman の利用が一般的でした。
ただし、pg_rman は Windows 非対応という課題がありました。
PostgreSQL 17 ではこれらの問題が解消され、標準機能として増分バックアップがサポートされました。
主な追加項目は以下のとおりです。
- pg_basebackup に増分バックアップを取得する --incremental オプションが追加
- フルバックアップと増分バックアップを統合する pg_combinebackup コマンドの追加
- 増分バックアップの制御にかかわる summarize_wal, wal_keep_summary パラメータの追加
これらによって増分バックアップの取得が可能になっています。
それぞれのコマンドやパラメータの扱い方について詳しく見ていきましょう。
動作確認環境と postgresql.conf のパラメータは以下です。
動作環境
| 領域 | パス | 備考 |
| データベースクラスタ | data | |
| WAL領域 | data/pg_wal | |
| バックアップ格納先 | backup | フルバックアップ、 増分バックアップを保存 |
postgresql.conf パラメータ
| パラメータ名 | 設定値 | 備考 |
| summarize_wal | on(off がデフォルト) | on でないと 増分バックアップ不可 |
| wal_level | replica(デフォルト) 以上 | summarize_wal が on の時は replica 以上が必須 |
増分バックアップのコマンド
増分バックアップの手順は大きく分けて以下です。
- pg_basebackup によるフルバックアップの取得
- pg_basebackup --incremental による増分バックアップの取得
- pg_combinebackup によるフルバックアップと増分バックアップの統合
コマンド実行例をもとに見ていきましょう。
フルバックアップ取得前の時点では full_backup というテーブルがあるのみです。
これから各増分バックアップ取得時点でテーブルを追加していき、各世代のバックアップの状態にリストアできるかを見ていきます。
$ psql psql (17.6) "help"でヘルプを表示します。 postgres=# \d リレーション一覧 スキーマ | 名前 | タイプ | 所有者 ----------+-------------+----------+---------- public | full_backup | テーブル | postgres (1 行)
最初に pg_basebackup コマンドでフルバックアップを取得します。
# -P オプションでサイズや進捗を確認可能 $ pg_basebackup -D backup/full -P 23818/23818 kB (100%), 1/1 テーブル空間
その後 inc1 テーブルを作成し、一回目の増分バックアップを取得します。
ここで pg_basebackup に新規で追加された --incremental オプションを用います。
引数には前回取得したバックアップ、つまりフルバックアップの backup_manifest ファイルを指定します。
backup_manifest ファイルはバックアップのトップディレクトリにあるのでそちらのパスを指定してください。
postgres=# create table inc1 (i int); CREATE TABLE $ pg_basebackup --incremental=backup/full/backup_manifest -D backup/inc1
二回目の増分バックアップも同様に inc2 テーブルを作成後取得します。
この時注意が必要なのが前回のバックアップを指定することです。
今回だとフルバックアップではなく一回目の増分バックアップの backup_manifest を指定します。
postgres=# create table inc2 (i int); CREATE TABLE $ pg_basebackup --incremental=backup/inc1/backup_manifest -D backup/inc2
最後に pg_combinebackup で各世代を統合していきます。
pg_combinebackup の -o オプションでは統合バックアップの出力先を指定し、その後の引数はフルバックアップから統合したい世代までの増分バックアップをすべて指定します。
統合後はpg_verifybackupでバックアップの整合性も忘れずチェックするようにしてください。
# フルバックアップからinc1(inc1 テーブルがある時点)まで $ pg_combinebackup -o backup/combine_full_inc1 backup/full/ backup/inc1 # フルバックアップからinc2(inc1, inc2 テーブルがある時点)まで $ pg_combinebackup -o backup/combine_full_inc2 backup/full/ backup/inc1 backup/inc2/ # 各統合バックアップを pg_verifybackup で検証 $ pg_verifybackup backup/combine_full_inc1 バックアップが正常に検証されました $ pg_verifybackup backup/combine_full_inc2 バックアップが正常に検証されました
各世代増分バックアップの中身を確認
では、各世代のバックアップが正しく取得できているか確認してみましょう。
統合バックアップを、それぞれ異なる port 番号 に設定して起動すると、各世代におけるinc1、inc2テーブルの状態が、作成時点の内容として保持されていることが分かります。
この検証により、全ての世代でバックアップが正しく取得されていることを確認できました。
$ pg_ctl -o "-p 5433" start -D backup/combine_full_inc1/ $ psql –p 5433 postgres=# \d リレーション一覧 スキーマ | 名前 | タイプ | 所有者 ----------+-------------+----------+---------- public | full_backup | テーブル | postgres public | inc1 | テーブル | postgres $ pg_ctl -o "-p 5434" start -D backup/combine_full_inc2/ $ psql –p 5434 postgres=# \d リレーション一覧 スキーマ | 名前 | タイプ | 所有者 ----------+-------------+----------+---------- public | full_backup | テーブル | postgres public | inc1 | テーブル | postgres public | inc2 | テーブル | postgres
増分バックアップのストレージコストと取得時間
最初に挙げたメリットとして、ストレージコストとバックアップ取得時間を抑えられる点がありました。
ここでは、実際にどの程度削減できているのか確認してみます。
まずストレージ使用量を比較すると、初回に取得したフルバックアップは 888 MB と比較的大きなサイズでした。
一方、続いて取得した増分バックアップは どれも約 4 MB 程度 と非常に小さく抑えられています。
これを「すべての世代をフルバックアップで保存する場合」と比べてみると、毎回 888 MB 近く消費することになります。
それに対して増分バックアップは変更分のみを保存すればよいため、世代を重ねてもバックアップ容量を大幅に抑えられる ことが分かります。
$ du -h --max-depth=1 backup/ 888M backup/full 6M backup/inc1 4M backup/inc2
また time コマンドでバックアップ取得の時間も比べてみましょう。
pg_basebackup --incremental と --incremental オプションなしのフルバックアップの取得時間を比べてみると、--incremental での増分バックアップは取得時間がかなり短いことが分かります。
$ time pg_basebackup -D backup/inc_3 --incremental=backup/inc2/backup_manifest -c fast -P 4045/888986 kB (100%), 1/1 テーブル空間 real 0m4.391s $ time pg_basebackup -D backup/full_3 -c fast -P 888986/888986 kB (100%), 1/1 テーブル空間 real 0m32.777s
pg_combinebackup のオプション
pg_combinebackup には統合のファイルコピーを高速化するオプションが用意されています。
ファイルコピーを高速化するオプション
| オプション | 説明 | 環境 | メリット |
| --copy | ファイルをコピー [デフォルト] |
||
| --copy-file-range | copy_file_rangeを利用したファイル部分コピー | FreeBSDか カーネル4.5+の Linux |
カーネル空間で 完結するため高速 |
| --clone | Reflink機能での ファイルクローンコピー |
カーネル 4.5+の Linux の Btrfs、Reflinkが有効なXFS macOS の APFS |
Inodeとブロックマップコピーのみのため高速 |
| -k, --link(v18で追加) | ハードリンクを作成する コピー |
リンク作成のみのため 高速 |
デフォルトのオプション以外はすべて高速化できるものの、すべて入出力のディレクトリが同じファイルシステムである必要がある点には注意してください。
--copy-file-range, --clone については実行できる環境に上記表のような制限もあります。
同期のオプション
| オプション | バックアップ統合の対象 | メリット |
| --fsync | バックアップディレクトリ内全ファイル [デフォルト] |
最小限のバックアップで済む |
| --plain | WALファイルとテーブル空間全体の シンボリックリンクまで |
左記をバックアップに含められる |
| --syncfs | バックアップディレクトリを含む ファイルシステム全体 |
ファイル一つ一つを開かないため統合が早い |
同期する範囲を指定できるオプションもあり、
同期対象を増やすほどディスクへの書き込みがより確実に行われるようになります。
デフォルトではバックアップ対象のディレクトリのみですが、--plain で WAL ファイルとテーブル空間全体のシンボリックリンクまで、--syncfs ではバックアップディレクトリを含むファイルシステム全体を同期の対象とできます。
--syncfs はファイルを一つ一つ開かず同期をチェックするため同期が素早く完了できるというメリットもあります。
増分バックアップ使用上の注意点
注意点は大きく分けて以下の3つです。それぞれ見ていきます。
- パラメータの管理
- フルバックアップ~増分バックアップの保存
- ストレージ容量
パラメータの管理
増分バックアップで管理すべきパラメータは以下です。
- summarize_wal
- wal_level
- wal_summary_keep_time
summarize_wal は pg_basebackup --incremental をする際に参照する wal の情報をまとめたサマリファイルを作成するか否かを制御するパラメータです。
このファイルがない状態で増分バックアップを取得しようとするとエラーとなり取得に失敗してしまいます。
デフォルトでは off となっていますので忘れずに on としてください。
# summarize_wal が off で取得したフルバックアップを対象とするとエラー $ pg_basebackup --incremental=backup/full/backup_manifest -D backup/inc1 pg_basebackup: エラー: ベースバックアップを開始できませんでした: ERROR: WAL集約が有効でなければ差分バックアップは取得できません
wal_level についても replica 以上が必要です。
これが replica 以上でないと summarize_wal のパラメータが無効となる仕様となっています。
wal_summary_keep_time はサマリファイルを保存する期間を指定するパラメータです。
例えば以下のように 1d に設定し、2 日後に増分バックアップを取得しようとすると必要なサマリファイルが削除されているため、取得に失敗してしまいます。
そのため、増分バックアップを取得する運用間隔よりも長い期間を設定する必要があります。
# postgresql.conf の wal_summary_keep_time を 1d に設定 wal_summary_keep_time = '1d' $ ls –l data/pg_wal/summaries/ -rw-------. 1 postgres postgres 32 11月 1 16:52 0000000100000001CF00002800000001D0000028.summary # 2 日後に増分バックアップを取得しようとすると失敗 $ date 2025年 11月 3日 月曜日 15:37:55 JST $ pg_basebackup -D backup/inc_1 --incremental=backup/full/backup_manifest -P -c fast pg_basebackup: エラー: ベースバックアップを開始できませんでした: ERROR: WAL集計がタイムライン1上の1/CD000060から1/CF000028まで必要ですが、そのタイムライン上のそのLSN範囲での集計は不完全です DETAIL: この範囲で集計されていない最初のLSNは1/CD000060です
フルバックアップ~増分バックアップの保存
pg_combinebackup をする際に引数フルバックアップ~統合したい世代までのフルバックアップがすべてないと以下エラーとなります。
# 最初の引数にフルバックアップを指定せずに実行 $ pg_combinebackup -o backup/combine_test backup/inc1 backup/inc2 pg_combinebackup: エラー: "backup/inc1"のバックアップは差分バックアップですが、最初のバックアップはフルバックアップである必要があります # backup/inc_1 を引数に渡さず実行 # LSN 位置に飛びが見られエラーとなる $ pg_combinebackup -o backup/combine_1 backup/full/ backup/inc_2 pg_combinebackup: エラー: "backup/full/"のバックアップはLSN 1/1A000060で始まっていますが、1/1C000028を期待していました
そのため、実際の運用ではフルバックアップと、最新世代までのすべての増分バックアップを保持しておく必要があります。
削除のタイミングとしては、定期的に pg_combinebackup を実行し、統合によって 不要になった過去のフルバックアップおよび増分バックアップを削除するフローになります。
また、統合して生成されたバックアップは、次回の pg_combinebackup におけるフルバックアップとして利用可能 であるため、統合元となった古いフルバックアップは削除して問題ありません。
ストレージ容量
ストレージコストの低さがメリットの増分バックアップですが、pg_combinebackup をした直後は古いバックアップと統合バックアップが共存する状態になりますので、それらすべてを保存できるストレージサイズを確保する必要があります。
増分バックアップと
PITR と両立したリストア手順
増分バックアップ PITR と両立しての増分バックアップを利用することができます。
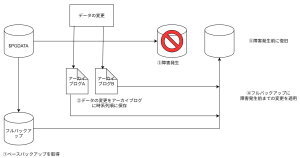
PITR(Point In Time Recovery) は WAL アーカイブをもとにして任意の時点までのリストアを可能にするリストア方法です。
WAL アーカイブはデータの変更履歴が記載されたもので、事前に取得しておいたフルバックアップに WAL アーカイブの変更履歴を任意の時点まで適用することで任意の時点に復旧できることが強みのリストア方法です。
この PITR と増分バックアップと両立することで以下メリットが得られます。
- 増分バックアップによるバックアップ取得でストレージコストや取得時間を短く抑えられる
- PITR によるリストアでより任意の時点に復旧することができる
今回はこれらを両立する設計で具体的な設定手順を紹介します。
まずパラメータの設定を行います。
#wal をアーカイブする設定 #%p は保管するWALファイルの相対パス, %f がWALのファイル名に置き換わる archive_mode = on archive_command = 'cp "%p" "/pg_arc/%f"' #restore を行う設定 restore_command = 'cp "/pg_arc/%f" "%p"'
その後増分バックアップ取得を行います。
フルバックアップ、増分バックアップ取得、バックアップの統合、検証の手順で取得します。
# フルバックアップ~バックアップの取得・統合、検証まで実施 $ pg_basebackup -D backup/full $ pg_basebackup --incremental=backup/full/backup_manifest -D backup/inc1 $ pg_combinebackup -o backup/combine_full_inc1 backup/full/ backup/inc1 $ pg_verifybackup backup/combine_full_inc1
その後 mv コマンドで疑似的にデータベースのデータが消えてしまった状態を作ります。
そして統合したバックアップを元のデータディレクトリに mv で移動し、recovery.signal を作成して起動すると PITR のリカバリモードで起動します。
リカバリ終了後に状態を見に行くとデータが指定した時点に復旧していることが分かります。
# データを移動して障害を疑似的に起こす $ mv data data_crash # 統合したバックアップを元ディレクトリにコピー $ cp –r databackup/combine_full_inc1 data # リカバリモードで起動するよう指示するrecovery.signal を作成して起動 $ touch data/recovery.signal # 必要に応じて postgresql.conf を設定し復旧タイミングを指定 recovery_target_time = '2025-10-20 14:05:00' $ pg_ctl start # ログに以下が出力されていれば復旧完了 LOG: starting archive recovery LOG: archive recovery complete
まとめ
今回は PostgreSQL 17 で追加された増分バックアップの運用方法と注意点について紹介しました。
PostgreSQL18ではさらに機能が追加されたりと今後より便利になっていく注目の手法です。
紹介した手順を参考に増分バックアップの利用を検討いただけると幸いです。