
pgBadger とは
最終更新:2026/4/27
pgBadger は PostgreSQL のログファイルを解析して、SQL の実行やサーバの動作に関するレポートを作成するツールです(図1)。多数の視点から解析された統計レポートは普段のデータベース動作の把握のみならず、パフォーマンス改善のヒントとして役立てることができます。また、pgBadger は大規模なログファイルを高速に解析できるよう設計されており、並列処理による効率的なログ分析にも対応しています。
pgBadger で出力されるレポートは以下の特徴があります。
- HTML 形式でグラフ出力が可能
- 多数の統計対象
- 日次、週次単位で作成可能
HTML 形式でグラフ出力が可能
出力されるレポートを HTML 形式にすることで解析結果の多くをグラフで表示することができます(テキスト形式や JSON 形式での出力も可能です)。解析されたログ情報がグラフ化されることで、素のログデータよりも人が見る上で非常に見通しの良いものとなります。 なので、別途に他ツールで処理する必要がなければ、HTML 形式のレポート出力をおすすめします。
多数の統計対象
レポートには以下に示すようにデータベースのパフォーマンス分析に役立つデータが多数出力されます。
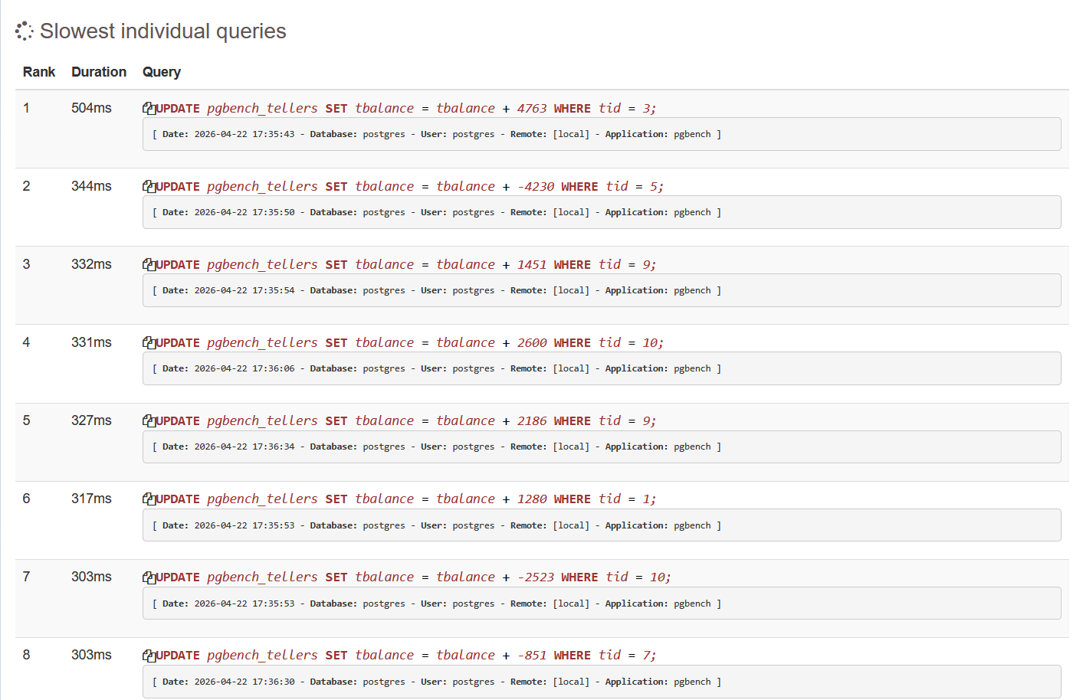
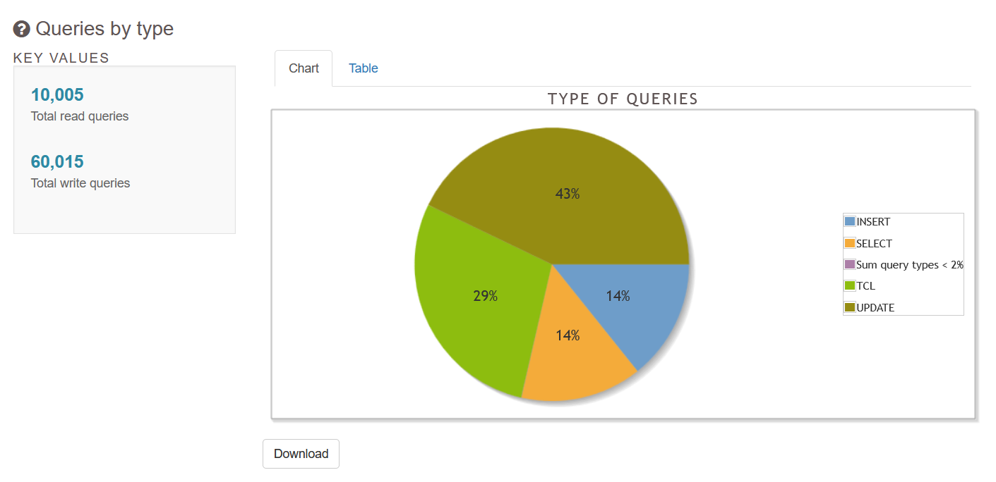
- クエリ(実行回数の合計、最多実行回数及びそのクエリ、実行時間の合計、最長実行時間及びそのクエリ、クエリ種類の割合)
- コネクション(合計接続数、 ピーク日時)
- セッション(合計セッション数、ピーク日時、合計セッション時間、セッション平均時間)
- チェックポイント(バッファ数、実行時間、発生間隔、発生要因)
- 一時ファイル(合計ファイル数、最大サイズ、平均サイズ、一時ファイルを多く生成したクエリ)
- バキューム(バキュームの実行回数、自動バキュームの実行回数、自動アナライズの実行回数、テーブル単位での処理時間・I/O時間)
- ロック(合計ロック数、ロック種類の割合、最多待ち回数とそのクエリ、最長待ち時間とそのクエリ)
- イベント(各レベル別の発生割合、イベントの発生傾向、最も頻繁に発生するエラー・イベント)
日次、週次単位で作成可能
pgBadger は各ログが記述された日時のデータを用いて1日単位、1週単位のレポートを作成することができます。さらに、インクリメンタルモードを利用することで、日次レポートを継続的に生成し、週単位での累積レポートを作成することも可能です。これにより、各日、各週におけるデータベース動作の比較検証が可能になります。
クエリ統計について
pgBadger のクエリ統計には具体的なクエリと汎化されたクエリに関する統計があります。クエリを汎化するとはつまり、
UPDATE pgbench_tellers SET tbalance + 3645 WHERE tid = 2; UPDATE pgbench_tellers SET tbalance + 1632 WHERE tid = 10;
といったクエリを以下のように一般化して、
UPDATE pgbench_tellers SET tbalance + 0 WHERE tid = 0;
同一種類のクエリとして認識するということです。
汎化されたクエリに関する統計を含めることにより、より実用的な統計を導き出しています。
インストールと設定
本記事の検証環境は Rocky Linux 9.5、PostgreSQL 18.3 です。
pgBadger インストール
今回は rpm パッケージからインストールする方法をご案内します。リポジトリは こちらのページからお使いの Linux ディストリビューションを選んで rpm ファイルのリンク先を確認して下さい。
dnf コマンドでリポジトリを登録し、そのリポジトリから pgBadger をインストールします。本記事執筆時の pgBadger のバージョンは 13.2 です。
# dnf install https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm # dnf install pgbadger
PostgreSQL 設定(postgresql.conf)
pgBadger は PostgreSQL のログからレポートを作成するため、PostgreSQL のログにはレポートに必要な情報が記述されるように設定する必要があります。
postgresql.conf を以下のように変更します。
# クエリの実行時間が指定した時間以上であったら、クエリのテキストと実行時間をログに残す log_min_duration_statement = 0 # ログメッセージの頭につける情報 log_line_prefix = '%t [%p]: user=%u,db=%d,app=%a,client=%h ' # 標準エラー出力を使う場合 # log_line_prefix = 'user=%u,db=%d,app=%a,client=%h ' # syslog を使う場合 # %t = タイムスタンプ(ミリ秒単位はなし) # %p = プロセスID # %u = ユーザ名 # %d = データベース名 # user, db, app, client の指定は任意 # チェックポイントの実行をログに残す log_checkpoints = on # クライアントの接続をログに残す log_connections = on # PG18 以降では all や接続フェーズごとの個別指定も可能 # クライアントの切断をログに残す log_disconnections = on # deadlock_timeout で指定した時間(デフォルト1秒)以上のロック待ちをログに残す log_lock_waits = on # 一時ファイルが作成されたことをログに残す(0はすべて) log_temp_files = 0 # autovacuum の実行情報をログに残す(0はすべて) log_autovacuum_min_duration = 0 # エラーメッセージの詳細度を制御する log_error_verbosity = default # ログの言語は英語限定 lc_messages = 'C'
なお、実行時間や実行回数のみを把握したい場合は、log_min_duration_statement = 0 の代わりに以下のように設定を変更することで負荷を抑えることができます。
log_min_duration_statement = -1 log_duration = on
レポートを作成してみよう
ここでは、1つのログファイルから1つのレポートを作成してみます。
以下の例ではデータベースサーバを起動してから書き込んでいるログファイルを
$PGDATA/log/postgresql-2026-04-22_173450.log とします。
サンプルデータを集めるため、pgbench でいくつかクエリを実行させてみましょう。
pgbench はベンチマークを目的としたモジュールですが、ここでは多数のクエリを実行させるために用います。
$ pgbench -i $ pgbench -c 10 -t 1000 # クライアント10, トランザクション1000 の想定で実行
ログファイルに実行したクエリの記述がたまったら、いよいよレポートを作成します。
と言っても、 pgBadger コマンドに PostgreSQL ログファイルを指定するだけで作成できてしまいます。
$ pgbadger $PGDATA/log/postgresql-2026-04-22_173450.log [========================>] Parsed 12531798 bytes of 12531798 (100.00%), queries: 70026, events: 1 LOG: Ok, generating html report...
ログの解析が完了すると out.html という名前のレポートファイルがカレントディレクトリに作成されます(オプションでファイル名や出力フォーマット、保存するディレクトリなどは指定可能です)。
HTML 形式でレポートを作成したので、Web ブラウザを使ってレポートの中身を見てみましょう。
* ここでレポートを作成せずに HTML レポートをご覧になりたい方はこちらに公開されているサンプルレポートをご覧ください。
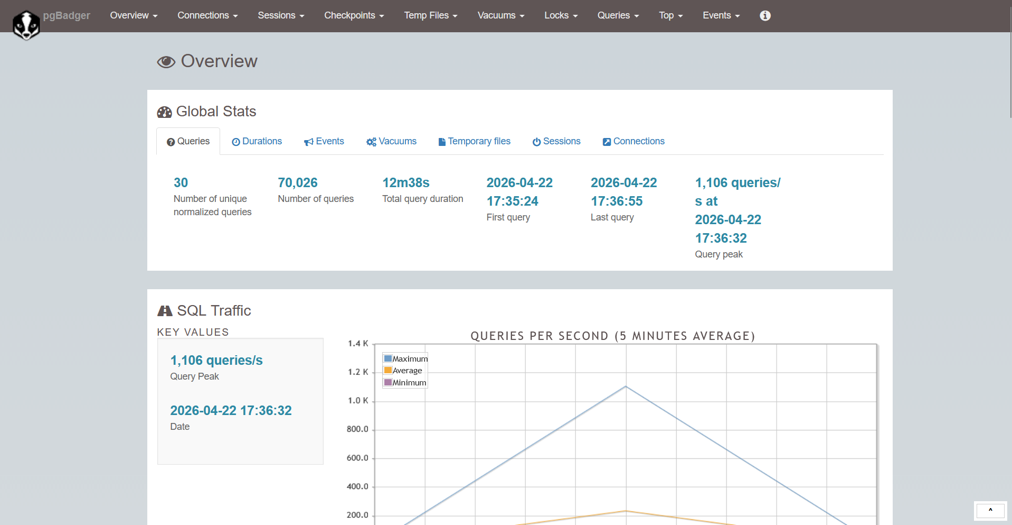
ファイルをブラウザで開くと以下のような Overview 画面が開きます。
画面上部のタブから各解析項目のページを開く事ができます。
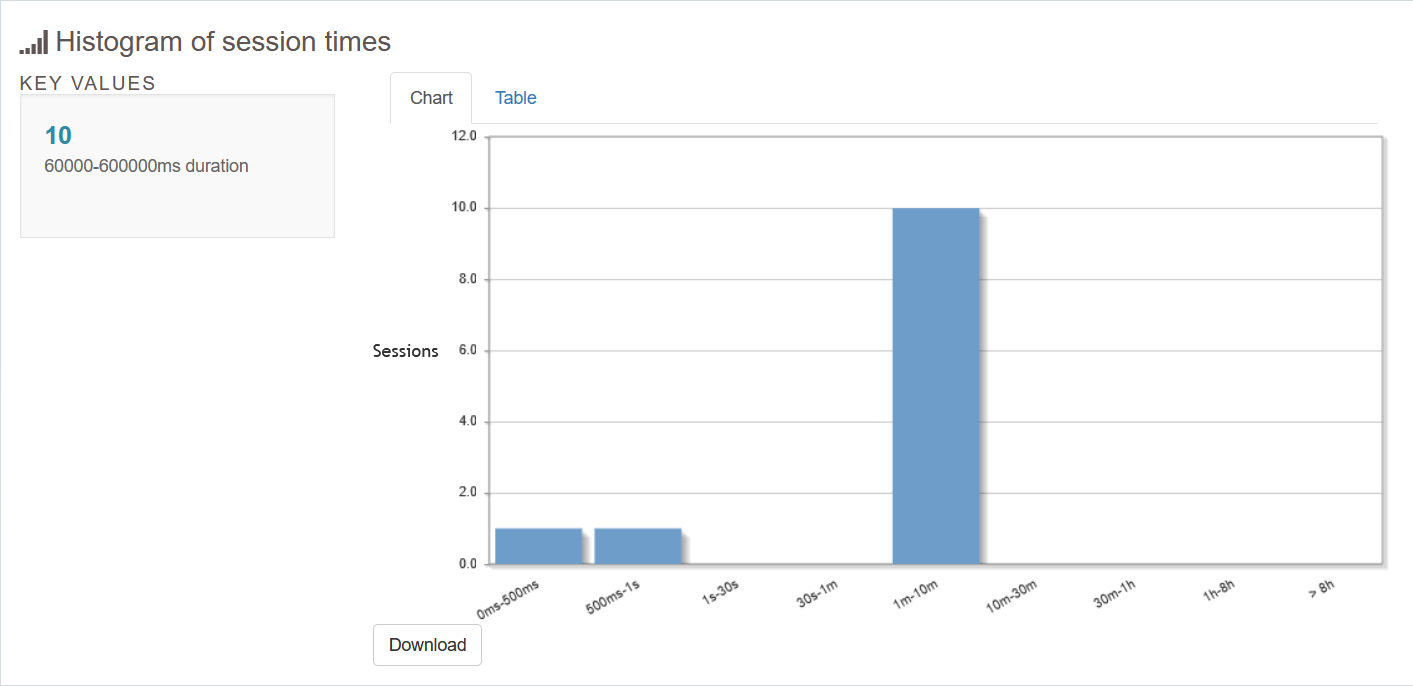
継続的ログの解析(インクリメンタルモード)を行うには
継続的に解析結果を得るにはインクリメンタルモードを用います。
インクリメンタルモードで pgBadger を実行することで、日次週次のレポート(インクリメンタルレポート)が作成されます。
$ pgbadger -I $PGDATA/log/postgresql-2026-04-23_000000.log -O /var/www/html/pg_reports # -I: インクリメンタルモード, -O: 出力ディレクトリ(インクリメンタルモード利用時には必須) [========================>] Parsed 14211813 bytes of 14211813 (100.00%), queries: 706, events: 2 LOG: Ok, generating HTML daily report into /var/www/html/pg_reports/2026/04/23/... LOG: Ok, generating HTML weekly report into /var/www/html/pg_reports/2026/week-17/... LOG: Ok, generating global index to access incremental reports... $ ls /var/www/html/pg_reports # 年付のディレクトリ、全レポートをリンクしたインデックスページ、最終パース行を保存したファイルが作成されます。 2026 LAST_PARSED index.html $ ls /var/www/html/pg_reports/2026 # 年付のディレクトリの中に日付、週付のディレクトリが作成されてレポートが作成されます。 04 week-17
インクリメンタルモードでレポートを作成した場合、各レポートページをリンクしたインデックスページが作成されます。
また、一度解析したログファイルは以前に解析した部分を省略して解析することができるようになります。これは最後にパースした行を LAST_PARSED という名前のファイルに保存することで実現しています。
$ cat /var/www/html/pg_reports/LAST_PARSED # 最後に解析した行が保存されています。 2026-04-23 14:59:33 14211813 2026-04-23 14:59:33 JST [44991]: user=postgres,db=postgres,app=psql,client=[local] LOG: duration: 0.261 ms statement: SELECT * FROM test;
手動でインクリメンタルレポートを作成していくこともできますが、実際は cron を用いて、インクリメンタルレポートの作成を自動化するとよいでしょう。
$ crontab -e 0 4 * * * /usr/bin/pgbadger -I -q /var/lib/pgsql/18/data/log/postgresql.log -O /var/www/html/pg_reports # 毎日04:00 にレポートを作成
並列処理による高速ログ解析
pgBadger は大規模なログファイルを高速に解析できるよう設計されており、並列処理による効率的なログ解析に対応しています。特に数GB規模のログファイルを扱う場合、デフォルトのままでは解析に時間がかかることがありますが、並列処理を利用することで処理時間を大幅に短縮することが可能です。
並列処理には、用途に合わせて -j と -J の 2 つのオプションが用意されています。
$ pgbadger -j 8 $PGDATA/log/postgresql-2026-04-27_152128.log [========================>] Parsed 123097 bytes of 123097 (100.00%), queries: 705, events: 1 LOG: Ok, generating html report...
この場合、ログファイルを8分割して8プロセスで同時に解析を行います。各プロセスが担当範囲を処理し、最後に結果を統合してレポートを生成します。この方式では、チャンクの境界付近でごくわずかにクエリが欠落または重複する可能性がありますが、通常は統計に影響しないレベルです。
小さなログファイルが多数存在する場合は、-J オプションの使用が有効です。
$ pgbadger -J 8 $PGDATA/log/postgresql*.log [========================>] Parsed 27411415 bytes of 27411415 (100.00%), queries: 153011, events: 14 LOG: Ok, generating html report...
このオプションでは、1つのログファイルを1つのプロセスで処理するため、クエリの欠落が発生せず、ファイル数が多い環境で効率的に処理できます。
ただし、一般的な環境では -j オプションでも十分な性能向上が得られるため、数百個以上の小さなログファイルがあり、かつ8コア以上のCPUが利用可能な場合を除き、-j の使用が推奨されます。
並列処理中は /tmp 配下に一時ファイル(tmp_pgbadgerXXXX.bin)が作成されます。これらのファイルは pgBadger の終了時に自動削除されます。実行中に削除するとレポート生成に失敗するため、処理が完了するまでは絶対に削除しないでください。
# ll /tmp | grep pgbadger -rw-------. 1 postgres postgres 13473 Apr 27 15:31 tmp_pgbadgerfjv9.bin -rw-------. 1 postgres postgres 9558 Apr 27 15:31 tmp_pgbadgermmVh.bin -rw-------. 1 postgres postgres 10075 Apr 27 15:31 tmp_pgbadgermxaF.bin
おわりに
いかがだったでしょうか。
pgBadger は豊富な統計結果を得られるので、データベースのパフォーマンスの改善を目指すにはうってつけの解析ツールです。
PostgreSQL のパフォーマンスが悪い理由は何なのか分からない、クエリの実行時間が怪しいのでは、などとお考えのときはぜひ使ってみてください。
リンク
pgBadger公式Webサイト(レポートのサンプルが公開されています)
https://pgbadger.darold.net/