
pg_repack は PostgreSQL のテーブルをオンラインで再編成できるツールです。本記事では pg_repackについて紹介します。
良く知られている通り、PostgreSQL は追記型アーキテクチャを採用しています。UPDATE や DELETE をしても旧データを格納した行はしばらく物理ファイル上に残り、これを VACUUM コマンドや自動 VACUUM で整理して、その領域を再利用可能にする仕組みとなっています。何らかの理由でこれらの手動・自動の VACUUM 処理が実行されなかった場合には、データ格納に使われない不要領域が増加し、性能劣化の原因となります。そのような場合には、CLUSTER コマンドや VACUUM FULL コマンドを使って、テーブルの再編成をするのですが、これらのコマンドは強いロックを取得するため、サービス中の適用が難しいという課題がありました。
pg_repack は CLUSTER または VACUUM FULL と同様に不要領域の削除や行の並び替えることができますが、処理中に強いロックをごく短時間しか取得しないため、サービス中にも実施が可能となります。
機能と仕組み
pg_repack は、参照や更新処理を長時間のブロックをせずに CLUSTER コマンドや VACUUM FULL コマンド相当の処理を実行することができます。また、合わせてインデックスの再作成も行います。
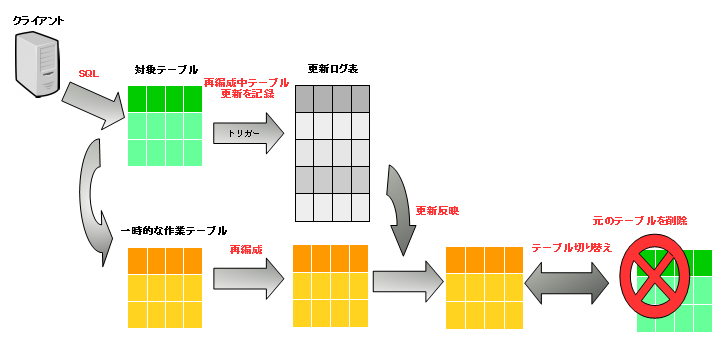
pg_repack は 図1 のように、操作対象テーブルの一時的な作業テーブルを作成します。操作対象テーブルへトリガを設定し、更新ログ表へ再編成中の更新処理を記録しておき、再編成完了後、その差分情報を作業テーブルに反映し、対象テーブルと切り替えます。再編成が作業テーブルで行われるため、オンラインでの再編成が可能となっています。
動作環境
pg_repack は以下の環境に対応しています。
- PostgreSQL バージョン:9.1 から 16 (pg_repack 1.5.0 時点)
- OSバージョン:基本的には x86_64 アーキテクチャの Linux 環境なら動作するはずです。本記事の検証環境には、CentOS 7.4 (x86_64) を使いました。Windows 向けには Microsoft Visual C++ を利用してビルドできます。ソースコードの msvc フォルダ内にプロジェクトファイルが用意されています。
Windowsバイナリの公式配布はありませんが、SRA OSS の PostgreSQLサポートサービスでは pg_repack の Windowsバイナリ提供を行っています。
インストール
pg_repack のソースコードは プロジェクトページ からダウンロードします。ダウンロード後、PostgreSQL のコマンドにパスが通ったユーザにて、ビルド、インストールします。
$ cd pg_repack $ make $ sudo make install
なお、RHEL系のLinuxを使用していて PostgreSQL本体をPGDGリポジトリのパッケージからインストールしている場合には、pg_repack もパッケージからインストールするのが簡単です。
インストールを行った後、pg_repack エクステンションを対象のデータベースに登録します。 下記例ではデータベース testdb を作成して、そこに拡張モジュールを登録しています。
$ createdb testdb
$ psql testdb -U postgres
testdb=# CREATE EXTENSION pg_repack;
CREATE EXTENSION
testdb=# \dx
List of installed extensions
Name | Version | Schema | Description
-----------+---------+------------+--------------------------------------------------------------
pg_repack | 1.4.3 | public | Reorganize tables in PostgreSQL databases with minimal locks
(1 rows)
基本的な使い方
pg_repack の基本的な使い方を見ていきます。コマンドは PostgreSQL のスーパーユーザと同名でサーバプロセス実行ユーザでもある OS 上の postgres ユーザで行うものとします。
testdb というデータベースの t1 テーブルをテーブル再編成するにはコマンドラインから以下のように実行します。-n は –no-order の省略形でデータ並び替えをしないという意味で、このコマンドは「VACUUM FULL t1」に相当します。
$ pg_repack -n -t t1 -d testdb INFO: ---- reorganize one table with 7 steps. ---- INFO: target table name : t1 INFO: ---- STEP1. setup ---- INFO: This needs EXCLUSIVE LOCK against the target table. INFO: ---- STEP2. copy tuples into temp table---- INFO: ---- STEP3. create indexes ---- INFO: ---- STEP4. apply logs ---- INFO: ---- STEP5. swap tables ---- INFO: This needs EXCLUSIVE LOCK against the target table. INFO: ---- STEP6. drop old table---- INFO: ---- STEP7. analyze ----
-n を付けないとデータ並び替えも行います。以下コマンドは「CLUSTER t1 USING col_id」に相当します。 -o は –order-by の省略形で、並び替えの基準となるカラムを指定しています。-o を省略すると以前に CLUSTER コマンドを実行したときに指定されたカラム(cluster key と呼ばれます)で並び替えが行われます。
$ pg_repack -o col_id -t t1 -d testdb (以下、コマンド出力を省略します)
また、データベース名だけを指定すると、そのデータベース内で pg_repack 実行可能なテーブル全てについて pg_repack を実行します。この場合も -n オプションの有無を選べます。-n 無し、すなわちデータ並び替えをする場合には、cluster key のカラムが定まってるテーブルだけが処理対象となります。
$ pg_repack -n testdb
コマンドオプションの詳細は pg_repack の付属ドキュメント に記載されています。
動作確認
実際に動作と効果を確認してみます。本記事の検証環境は CentOS 7.4、PostgreSQL 9.6.10、pg_repack は 1.4 系列 2018 年 10 月時点のコードです。
テーブル t1 を作成し、10,000 件のレコードを初期登録します。この時点でサイズは 632kB です。
testdb=# CREATE TABLE t1 (id int primary key, val text);
CREATE TABLE
testdb=#
testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));
pg_size_pretty
----------------
16 kB
(1 row)
testdb=# INSERT INTO t1 VALUES(generate_series(1,10000),'AAA');
INSERT 0 10000
testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));
pg_size_pretty
----------------
632 kB
(1 row)
次に不要領域を作るため、テーブルの全行を UPDATE することを数回繰り返します。
testdb=# UPDATE t1 SET VAL = 'BBB';
UPDATE 10000
(何度か繰り返す)
testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));
pg_size_pretty
----------------
4568 kB
(1 row)
更新を繰り返し、レコード数が変わらず、テーブルサイズが 632kB から 4568kB まで膨らみました。VACUUM をしても、テーブルの物理サイズは小さくなりません。
testdb=# VACUUM t1;
VACUUM
testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));
pg_size_pretty
----------------
4568 kB
(1 row)
pg_repack によるテーブル再編成を行います。
$ pg_repack -n -t t1 -d testdb
再編成後、テーブルの物理サイズが小さくなっていることが確認できます。
$ psql testdb -U postgres
testdb=# SELECT pg_size_pretty(pg_total_relation_size('t1'));
pg_size_pretty
----------------
632 kB
(1 row)
他にも、以下のように実行することも可能です
-
- -t オプションを複数同時に使用することで、複数のテーブルを指定することができます。
$ pg_repack -n -t t1 -t t2 -d testdb
-
- データベースtestdb全体を4並列実行にてテーブル再編成をかけます。
$ pg_repack -n -j 4 testdb
-
- データベースtestdbテーブル t1 のインデックスのみを再編成します。
$ pg_repack -d testdb -t t1 --only-indexes
-
- テーブル再編成と共にテーブルとインデックスをテーブルスペース tbs1 に移動します。
$ pg_repack -d testdb --tablespace tbs1 --moveidx
注意事項
pg_repack を利用する際には以下の点に注意が必要です。
- ディスク容量一時的な作業テーブルを作るので、対象テーブルとインデックスの 2 倍以上のディスク空き領域が必要です。PostgreSQL 9.0 以降の VACUUM FULL では、対象テーブル・インデックスと同サイズ程度の空き容量を要しましたが、それよりも更にもう一つ分が必要となることに注意してください。
- pg_repack の実行中には、VACUUM と ANALYZE 以外の DDL を実行してはいけません。特に TRUNCATEやCREATE INDEX、ALTER TABLE を実行するとデータの整合性が崩れたり、消えてしまうことがあります。
- 実行対象テーブル対象のテーブルには、たとえ並べ替えをしない場合でも、主キー、または NOT NULL 属性とユニークインデックスを持つカラムが少なくとも一つ必須です。また、一時テーブル、または GiST インデックスがクラスタインデックスとなっているテーブルは操作の対象外です。
- pg_repack は、データベース上のスーパーユーザ(通例 postgres ユーザ)のみが実行可能です。
- 短いタイムアウトでリトライを繰り返すようにして、排他ロックを短時間だけ取得することで、ロック待ちを回避しています。 -T (–wait-timeout)で指定するタイムアウト時間(デフォルト60秒)を超えてロック取得ができない場合には他プロセスを終了させる動作が生じます。ロック取得できなかった場合に pg_repack の方を中断させるには -D (–no-kill-backend) を指定してください。
- pg_repack の処理過程には、ある時点で実行中のトランザクションが全て終了するのを待つ、というステップがあります。そのため、ロングトランザクション実行が並行していると、それが別のテーブルを対象にした処理であったとしても、pg_repack が長く待ってしまう可能性があります。
pg_reorg について
さて、今回紹介した pg_repack ですが、これは pg_reorg というソフトウェアの開発プロジェクトから分岐したものです。現在、pg_reorg の開発は停止しており、実質 pg_repack が後継のソフトウェアとなります。
pg_reorg で提供されていた機能は pg_repackで網羅していることに加え、pg_repack でのみ提供している新機能もあるため、現状 pg_reorg を選択する利点はほとんどありません。しかし PostgreSQL9.0系にこれらを導入する場合は、pg_repack は動作環境としてこれを含んでいないため、pg_reorg を選択することになります。
pg_reorg は、バイナリパッケージは古いバージョンのみであるため、ソースコードからインストールするのが良いでしょう。pg_reorg のソースコードは プロジェクトページ からダウンロードします。ビルド手順は pg_repack と同様です。
おわりに
本稿では PostgreSQL のテーブルをオンラインで編集できるツール pg_repack、pg_reorg の紹介をしました。
何らかの事情で VACUUM が適切に行われない事態となっていたのを長期に見逃して、既にテーブル物理ファイルの肥大化が発生してしまったけれども、サービス停止できないので、VACUUM FULL コマンドは実行できないという場合の対処手段として pg_repack、pg_reorg は極めて有用といえます。