
現在開発中のPostgreSQL 12では、様々な新機能の追加や改良が予定されています。本稿では、その中でも実用上の価値が高いと思われる改良の一つである、CTEの高速化についてご紹介します。
CTEとは
CTEとは、”Common Table Expressions” (共通テーブル式)の略で、SQL文内でテーブル式を定義し、それを同じSQL文内から参照できるものです。CTEには、普通の検索を行うだけでなく、再帰的なクエリ実行を行ったり(WITH RECURSIVE)、CTE内で更新処理を行うこともできますが、PostgreSQL 12で改良されたのは、再帰も更新も伴わない通常の検索処理で使われるCTEです。
CTEを使うと、複雑なクエリや、同じようなサブクエリを何度も呼ぶようなSQL文を見通しよく書くことができます。同じようなことはVIEWや関数を定義することによっても可能ですが、CTEでは、そのクエリ内でしか使わないテーブル式を手軽に定義できるところが便利で、業務システムでも広く使われています。
PostgreSQLのマニュアルにはCTEの例が掲載されているので、それを例にとって説明しましょう。
WITH regional_sales AS (
SELECT region, SUM(amount) AS total_sales
FROM orders
GROUP BY region
), top_regions AS (
SELECT region
FROM regional_sales
WHERE total_sales > (SELECT SUM(total_sales)/10 FROM regional_sales)
)
SELECT region,
product,
SUM(quantity) AS product_units,
SUM(amount) AS product_sales
FROM orders
WHERE region IN (SELECT region FROM top_regions)
GROUP BY region, product;
CTEを使う場合はキーワード”WITH”で開始、テーブル式の名前の後のAS (…)の中にテーブル式の定義を書きます。この例では、”regional_sales”と”top_region”の2つのCTEが定義されています。また、あるCTEから別のCTEを呼び出すことも可能で、この例でもCTE “top_region”が”regional_sales”を呼び出しています。CTEの定義の後には、通常のSELECT文を書きます。その中でCTEを通常のテーブルのように呼び出せます。
CTEの問題点
以上のように便利なCTEですが、PostgreSQLの実装には性能上の問題がありました。CTEがあると、PostgreSQLはその結果をマテリアライズ(“materialize”)、すなわち本当のテーブルのようにメモリやディスク上に実体を作るため、実行時間がかかる場合があったのです。例を示します。
-- 1千万件のテーブル作成
CREATE TABLE t1 AS SELECT * FROM generate_series(1, 10000000) AS i;
-- CTEを使用したSELECTを実行
EXPLAIN ANALYZE WITH t1scan AS (SELECT * FROM t1) SELECT * FROM t1scan WHERE i = 1;
QUERY PLAN
--------------------------------------------------------------------------------
----------------------------------------
CTE Scan on t1scan (cost=144247.77..369247.25 rows=50000 width=4) (actual time=0.093..1918.787 rows=1 loops=1)
Filter: (i = 1)
Rows Removed by Filter: 9999999
CTE t1scan
-> Seq Scan on t1 (cost=0.00..144247.77 rows=9999977 width=4) (actual time=0.080..708.139 rows=10000000 loops=1)
Planning Time: 1.530 ms
Execution Time: 1946.775 ms
(7 rows)
この例では、”CTE t1scan”以下でテーブルt1を順スキャンですべて読み取ってマテリアライズし(そしておそらくディスクに書き込み)、その結果に対して”CTE Scan on t1scan…”以下SELECT文を実行します。これでは1千万件のt1テーブルを全部ディスクにコピーしなければならず、時間がかかってしまいます。
PostgreSQL 12ではCTEが高速化
マテリアライズの利用は再帰や更新を伴うCTEでは妥当な実装ですが、そうでないCTEではマテリアライズは不要ではないかということで、PostgreSQL 12では動作が変更されました。
先程のクエリはPostgreSQL 12では以下のようなプランになります。
EXPLAIN ANALYZE WITH t1scan AS (SELECT * FROM t1) SELECT * FROM t1scan WHERE i = 1;
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..97331.31 rows=1 width=4) (actual time=0.226..343.876 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on t1 (cost=0.00..96331.21 rows=1 width=4) (actual time=225.918..339.821 rows=0 loops=3)
Filter: (i = 1)
Rows Removed by Filter: 3333333
Planning Time: 0.068 ms
Execution Time: 343.891 ms
(8 rows)
ご覧のように、CTEに関するプランは消えて、直接t1を順スキャンするプランに変わっています(しかもパラレルクエリになっています!)。つまり、CTEのマテリアライズ化が行われていません。考えてみるとこのSELECT文は、直接”SELECT * FROM t1 WHERE i = 1″と同じなのでこれはうなずける結果です。実際、”EXPLAIN SELECT * FROM t1 WHERE i = 1を実行すると、同じプランが得られます。
QUERY PLAN
-------------------------------------------------------------------------------------------------------------------
Gather (cost=1000.00..97331.31 rows=1 width=4) (actual time=0.916..599.521 rows=1 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Parallel Seq Scan on t1 (cost=0.00..96331.21 rows=1 width=4) (actual time=388.638..584.812 rows=0 loops=3)
Filter: (i = 1)
Rows Removed by Filter: 3333333
Planning Time: 2.965 ms
Execution Time: 599.622 ms
(8 rows)
このように実行結果が変わらない範囲でPostgreSQL 12はクエリを賢く書き換え、より高速に実行しています。
マテリアライズ化する条件
どんな場合でもCTEを非マテリアライズ化するわけではありません。以下の条件をすべて満たしている必要があります。
- 同じCTEが2回以上使われていない
- CTE中に非immutable関数が使われていない
(1)は、同じCTEを2回以上使うのであれば、マテリアライズしてそれを使い回したほうが良いだろう、というのが理由です(必ずしもそうとは言い切れないので、その場合は後述の方法でマテリアライズを避けることができます)。(2)は、非immutable関数は実行するたびに結果が変わるので、マテリアライズ化しなければユーザの意図とは異なる結果になってしまうかもしれないからです。
マテリアライズ化の手動制御
PostgreSQL 12は、上記の条件を満たしていれば、自動的にCTEをマテリアライズ化せずに実行しますが、手動で制御することも可能です。
WITH t1scan AS (SELECT * FROM t1) SELECT * FROM t1scan WHERE i IN (SELECT * FROM t1scan WHERE i = 1);
このクエリではt1scanが2回使われているため、デフォルトではマテリアライ
ズされてしまいます。しかし、キーワード”NOT MATERIALIZED”を追加すること
によってマテリアライズを避けることができます。
WITH t1scan AS NOT MATERIALIZED (SELECT * FROM t1) SELECT * FROM t1scan WHERE i IN (SELECT * FROM t1scan WHERE i = 1);
なお、非immutable関数が含まれている場合は、”NOT MATERIALIZED”を指定しても、強制的にマテリアライズされてしまいます。
逆に強制的にマテリアライズすることもできます。
WITH t1scan AS MATERIALIZED (SELECT * FROM t1) SELECT * FROM t1scan WHERE i IN (SELECT * FROM t1scan WHERE i = 1);
これは、PostgreSQL 11以前と同じ挙動をして欲しい場合に利用することを想定しています。
TPC-DS高速化
ここまでに取り上げた例は、わかりやすさを優先して、かなり人工的なものになっていました。そこでもう少し現実世界に近い例として、TPC-DSにおける高速化の例を紹介します。
TPC-DSは、TPC (Transaction Processing Performance Council)という団体が発行している標準ベンチマークスィートの一つです。TPC-DSは、意思決定支援システムのためのデータベースをモデル化しており、主に大規模データベースにおける複雑な問い合わせの処理性能を確認するために用いられます。モデルにしているのは、店舗、Web、カタログなどを通じて販売する物販業者です。販売実績、在庫、顧客の購買履歴が管理されています。
TPC-DSはデータ生成ツールや、クエリを実行するためのSQL文を生成する機能も備えており、ダウンロードしてPostgreSQLでも実行が可能です。実際にPostgreSQLで実行するためには、一部クエリに修正が必要ですが、今回は詳細には触れません。
検証環境
検証環境は手元のノートPCで、Ubuntu 18が動いており、メモリ16GB、SSDにデータベースを配置しており、データベースサイズは2GBです。PostgreSQL 12は2019年3月8日時点のGitリポジトリを取得したものからインストール、PostgreSQL 11は、11.2のtar ballからインストールしました。
検証対象のクエリ
クエリは全部で103本あり、1から始まる通し番号が振られており、CTEが多くのクエリで使われています。ここでは、PostgreSQL 11とPostgreSQL 12で実行時間を比較して、PostgreSQL 12で高速化が確認されたクエリNo.2をご紹介します。
実際のクエリは以下のようなものです。
with wscs as
(select sold_date_sk
,sales_price
from (select ws_sold_date_sk sold_date_sk
,ws_ext_sales_price sales_price
from web_sales
union all
select cs_sold_date_sk sold_date_sk
,cs_ext_sales_price sales_price
from catalog_sales) as s1),
wswscs as
(select d_week_seq,
sum(case when (d_day_name='Sunday') then sales_price else null end) sun_sales,
sum(case when (d_day_name='Monday') then sales_price else null end) mon_sales,
sum(case when (d_day_name='Tuesday') then sales_price else null end) tue_sales,
sum(case when (d_day_name='Wednesday') then sales_price else null end) wed_sales,
sum(case when (d_day_name='Thursday') then sales_price else null end) thu_sales,
sum(case when (d_day_name='Friday') then sales_price else null end) fri_sales,
sum(case when (d_day_name='Saturday') then sales_price else null end) sat_sales
from wscs
,date_dim
where d_date_sk = sold_date_sk
group by d_week_seq)
select d_week_seq1
,round(sun_sales1/sun_sales2,2)
,round(mon_sales1/mon_sales2,2)
,round(tue_sales1/tue_sales2,2)
,round(wed_sales1/wed_sales2,2)
,round(thu_sales1/thu_sales2,2)
,round(fri_sales1/fri_sales2,2)
,round(sat_sales1/sat_sales2,2)
from
(select wswscs.d_week_seq d_week_seq1
,sun_sales sun_sales1
,mon_sales mon_sales1
,tue_sales tue_sales1
,wed_sales wed_sales1
,thu_sales thu_sales1
,fri_sales fri_sales1
,sat_sales sat_sales1
from wswscs,date_dim
where date_dim.d_week_seq = wswscs.d_week_seq and
d_year = 1998) y,
(select wswscs.d_week_seq d_week_seq2
,sun_sales sun_sales2
,mon_sales mon_sales2
,tue_sales tue_sales2
,wed_sales wed_sales2
,thu_sales thu_sales2
,fri_sales fri_sales2
,sat_sales sat_sales2
from wswscs
,date_dim
where date_dim.d_week_seq = wswscs.d_week_seq and
d_year = 1998+1) z
where d_week_seq1=d_week_seq2-53
order by d_week_seq1;
かなり複雑なクエリですが、意味としては、「Webおよびカタログを通じて販売された売上の、各曜日ごとの前年からの売上増加率を問い合わせる」ものだそうです。
実行結果
実行結果をグラフで示します。ご覧のように、PostgreSQL 11では2秒以上かかっているの対し、PostgreSQL 12では0.7秒くらいと、PostgreSQL 12では3倍程度高速化されていることがわかります。
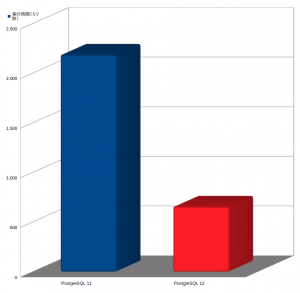
なぜこうなったのかは、実行計画を比較するとその理由がわかります。
PostgreSQL 11では、CTE “wscs”と”wswscs”の両方がマテリアライズされています。
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=227105.32..227105.35 rows=13 width=228) (actual time=2019.071..2019.163 rows=2513 loops=1)
Sort Key: wswscs.d_week_seq
Sort Method: quicksort Memory: 323kB
CTE wscs
-> Append (cost=0.00..88586.64 rows=2160976 width=10) (actual time=0.015..521.937 rows=2160932 loops=1)
-> Seq Scan on web_sales (cost=0.00..25960.84 rows=719384 width=10) (actual time=0.014..137.557 rows=719384 loops=1)
-> Seq Scan on catalog_sales (cost=0.00..51820.92 rows=1441592 width=10) (actual time=0.011..269.559 rows=1441548 loops=1)
CTE wswscs
-> HashAggregate (cost=132977.62..133264.03 rows=10415 width=228) (actual time=1996.856..1997.387 rows=263 loops=1)
Group Key: date_dim_2.d_week_seq
-> Hash Join (cost=3048.60..51941.02 rows=2160976 width=28) (actual time=36.414..1323.387 rows=2153563 loops=1)
Hash Cond: (wscs.sold_date_sk = date_dim_2.d_date_sk)
-> CTE Scan on wscs (cost=0.00..43219.52 rows=2160976 width=18) (actual time=0.017..942.090 rows=2160932 loops=1)
-> Hash (cost=2135.49..2135.49 rows=73049 width=18) (actual time=35.870..35.871 rows=73049 loops=1)
Buckets: 131072 Batches: 1 Memory Usage: 4734kB
-> Seq Scan on date_dim date_dim_2 (cost=0.00..2135.49 rows=73049 width=18) (actual time=0.011..17.749 rows=73049 loops=1)
-> Hash Join (cost=5006.47..5254.41 rows=13 width=228) (actual time=2012.260..2018.602 rows=2513 loops=1)
Hash Cond: (wswscs.d_week_seq = date_dim.d_week_seq)
-> CTE Scan on wswscs (cost=0.00..208.30 rows=10415 width=228) (actual time=1996.858..1996.876 rows=263 loops=1)
-> Hash (cost=5006.31..5006.31 rows=13 width=232) (actual time=15.380..15.380 rows=2513 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 288kB
-> Merge Join (cost=5000.73..5006.31 rows=13 width=232) (actual time=14.272..14.683 rows=2513 loops=1)
Merge Cond: (((wswscs_1.d_week_seq - 53)) = date_dim.d_week_seq)
-> Sort (cost=2667.18..2668.09 rows=363 width=228) (actual time=7.374..7.393 rows=365 loops=1)
Sort Key: ((wswscs_1.d_week_seq - 53))
Sort Method: quicksort Memory: 76kB
-> Hash Join (cost=2322.65..2651.75 rows=363 width=228) (actual time=6.386..7.154 rows=365 loops=1)
Hash Cond: (wswscs_1.d_week_seq = date_dim_1.d_week_seq)
-> CTE Scan on wswscs wswscs_1 (cost=0.00..208.30 rows=10415 width=228) (actual time=0.000..0.707 rows=263 loops=1)
-> Hash (cost=2318.11..2318.11 rows=363 width=4) (actual time=6.367..6.367 rows=365 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 21kB
-> Seq Scan on date_dim date_dim_1 (cost=0.00..2318.11 rows=363 width=4) (actual time=3.000..6.330 rows=365 loops=1)
Filter: (d_year = 1999)
Rows Removed by Filter: 72684
-> Sort (cost=2333.55..2334.45 rows=363 width=4) (actual time=6.890..6.975 rows=2514 loops=1)
Sort Key: date_dim.d_week_seq
Sort Method: quicksort Memory: 42kB
-> Seq Scan on date_dim (cost=0.00..2318.11 rows=363 width=4) (actual time=3.832..6.841 rows=365 loops=1)
Filter: (d_year = 1998)
Rows Removed by Filter: 72684
PostgreSQL 12では、CTE “wswscs”だけがマテリアライズされ、CTE “wscs”はプラン中に現れず、マテリアライズされていないことがわかります。
QUERY PLAN
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Sort (cost=118929.39..118929.43 rows=13 width=228) (actual time=792.588..792.710 rows=2513 loops=1)
Sort Key: wswscs.d_week_seq
Sort Method: quicksort Memory: 323kB
CTE wswscs
-> Finalize GroupAggregate (cost=110164.09..113672.71 rows=10447 width=228) (actual time=766.232..768.415 rows=263 loops=1)
Group Key: date_dim_2.d_week_seq
-> Gather Merge (cost=110164.09..112601.89 rows=20894 width=228) (actual time=766.209..767.158 rows=789 loops=1)
Workers Planned: 2
Workers Launched: 2
-> Sort (cost=109164.06..109190.18 rows=10447 width=228) (actual time=763.059..763.078 rows=263 loops=3)
Sort Key: date_dim_2.d_week_seq
Sort Method: quicksort Memory: 160kB
Worker 0: Sort Method: quicksort Memory: 160kB
Worker 1: Sort Method: quicksort Memory: 160kB
-> Partial HashAggregate (cost=108179.39..108466.69 rows=10447 width=228) (actual time=762.202..762.889 rows=263 loops=3)
Group Key: date_dim_2.d_week_seq
-> Parallel Hash Join (cost=2371.82..74413.79 rows=900416 width=20) (actual time=17.166..424.834 rows=717854 loops=3)
Hash Cond: (catalog_sales.cs_sold_date_sk = date_dim_2.d_date_sk)
-> Parallel Append (cost=0.00..69678.24 rows=900416 width=10) (actual time=0.029..248.992 rows=720311 loops=3)
-> Parallel Seq Scan on catalog_sales (cost=0.00..43411.73 rows=600673 width=10) (actual time=0.018..130.163 rows=480516 loops=3)
-> Parallel Seq Scan on web_sales (cost=0.00..21764.43 rows=299743 width=10) (actual time=0.026..95.629 rows=359692 loops=2)
-> Parallel Hash (cost=1834.70..1834.70 rows=42970 width=18) (actual time=16.610..16.610 rows=24350 loops=3)
Buckets: 131072 Batches: 1 Memory Usage: 5056kB
-> Parallel Seq Scan on date_dim date_dim_2 (cost=0.00..1834.70 rows=42970 width=18) (actual time=0.020..7.617 rows=24350 loops=3)
-> Hash Join (cost=5007.74..5256.44 rows=13 width=228) (actual time=785.300..792.123 rows=2513 loops=1)
Hash Cond: (wswscs.d_week_seq = date_dim.d_week_seq)
-> CTE Scan on wswscs (cost=0.00..208.94 rows=10447 width=228) (actual time=766.236..766.263 rows=263 loops=1)
-> Hash (cost=5007.58..5007.58 rows=13 width=232) (actual time=19.033..19.033 rows=2513 loops=1)
Buckets: 4096 (originally 1024) Batches: 1 (originally 1) Memory Usage: 288kB
-> Merge Join (cost=5001.97..5007.58 rows=13 width=232) (actual time=17.739..18.210 rows=2513 loops=1)
Merge Cond: (((wswscs_1.d_week_seq - 53)) = date_dim.d_week_seq)
-> Sort (cost=2668.33..2669.24 rows=365 width=228) (actual time=9.906..9.924 rows=365 loops=1)
Sort Key: ((wswscs_1.d_week_seq - 53))
Sort Method: quicksort Memory: 76kB
-> Hash Join (cost=2322.68..2652.79 rows=365 width=228) (actual time=7.864..9.764 rows=365 loops=1)
Hash Cond: (wswscs_1.d_week_seq = date_dim_1.d_week_seq)
-> CTE Scan on wswscs wswscs_1 (cost=0.00..208.94 rows=10447 width=228) (actual time=0.001..2.287 rows=263 loops=1)
-> Hash (cost=2318.11..2318.11 rows=365 width=4) (actual time=7.389..7.389 rows=365 loops=1)
Buckets: 1024 Batches: 1 Memory Usage: 21kB
-> Seq Scan on date_dim date_dim_1 (cost=0.00..2318.11 rows=365 width=4) (actual time=3.876..7.348 rows=365 loops=1)
Filter: (d_year = 1999)
Rows Removed by Filter: 72684
-> Sort (cost=2333.65..2334.56 rows=365 width=4) (actual time=7.824..7.930 rows=2514 loops=1)
Sort Key: date_dim.d_week_seq
Sort Method: quicksort Memory: 42kB
-> Seq Scan on date_dim (cost=0.00..2318.11 rows=365 width=4) (actual time=3.950..7.765 rows=365 loops=1)
Filter: (d_year = 1998)
Rows Removed by Filter: 72684
最後に
PostgreSQLは、パラレルクエリやネィティブパーティショニングなど、大規模データにおける検索処理を性能向上させる機能が追加されてきています。今回PostgreSQL 12でCTEの高速化が行われ、ますますこの分野での性能が向上していることは、PostgreSQLの利用範囲をますます広げることにつながり、今後が楽しみです。