
本記事では PostgreSQLのバックアップについて、基本的な概念と、取りうるいくつかの手段について、基本的な解説をします。
データベース全般におけるバックアップ
データベースのバックアップには、PostgreSQLに限らず、一般的に論理/物理、また、オンライン/オフラインがあります。まず、この分類の説明をします。また、RPO/RTOという考え方についても説明します。
論理バックアップ/物理バックアップ
論理バックアップは、データベースの内容をSQL文のテキスト形式や同内容のバイナリ形式でバックアップすることです。リストアはそのSQL文を実行することで行います。物理バックアップとは、データベースのOS上のデータ格納ファイルをそのままの形でバックアップすることです。利用しているOSやデータベースソフトウェアのみ理解できる形式です。
オンラインバックアップ/オフラインバックアップ
オンラインバックアップは、データベースサービスが起動している状態で行うバックアップです。ホットバックアップとも言います。オフラインバックアップとは、データベースサービスが停止している状態で行うバックアップです。コールドバックアップとも言います。
後述するPostgreSQLのバックアップ用のコマンドは全てオンラインバックアップを実行します。オフラインバックアップは、サービスが停止している状態で、OSのコマンド(cp, tar 等)や、ストレージ装置や仮想化基盤によるスナップショット機能で、データベースの格納ディレクトリを丸ごとコピーして、それを物理バックアップとすることで実現できます。
RPO/RTO
RPO(Recovery Point Objective)はおおまかに「障害発生時にどの時点までデータベースをリカバリするか」という意味です。バックアップ方式によって実現可能なRPOが異なりますので、RPOはバックアップ方式を選択するときの判断基準の一つです。データが日々更新される状況において、データベースに障害が発生した場合、理想は障害の直前のデータまで復旧することになります。
RPO と同じ文脈でよく語られる言葉としてRTO(Recovery Time Objective)があります。これは「リカバリ作業にどのくらい時間がかかるか」という意味です。こちらもバックアップ方式の重要な選択基準となります。
PostgreSQL におけるバックアップ
ここからはPostgreSQL についての説明になります。なお、文中で PostgreSQLドキュメントのリンクを提示するときにはバージョン17文書のURLを使用していますので、皆さんが実際に使っている PostgreSQLバージョンに読み替えてください。
バックアップ対象
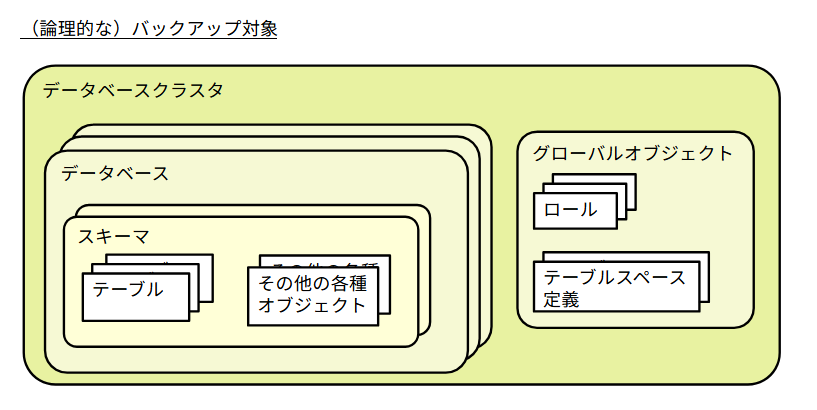
バックアップ対象となるデータベースサーバの構成を図示すると下記の様になります。物理的な見方と論理的な見方があります。前者はファイルとディレクトリであり、後者は利用者から見えるデータベース内の要素です。
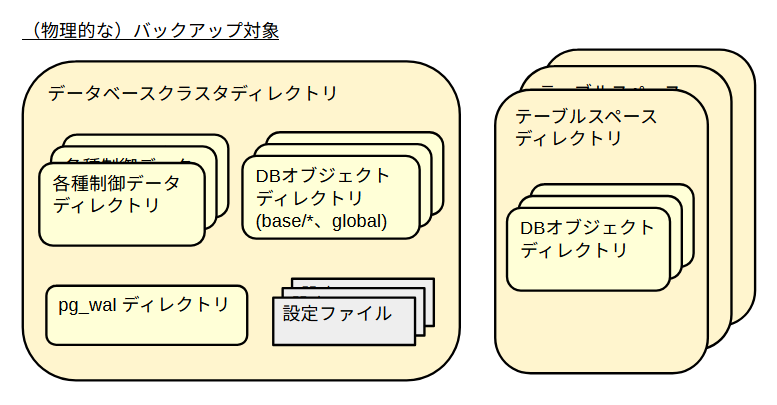
PostgreSQLは1つのデータベースクラスタとWALファイル群に対応して、1つのサービスを起動します。データベースクラスタはinitdbコマンドで作成するものです。
「データベースクラスタ」の中には「データベース」がいくつか存在します。「データベース」の中には「スキーマ」がいくつか存在します。スキーマにはデータベースを作成した時に自動的に作成されるパブリックスキーマの他に、ユーザがそれぞれの用途で使用するスキーマがあります。
pg_dump は論理バックアップを行い、その対象は「データベース」や「スキーマ」です。テーブル単位の指定も可能です。実行時にデータベースやスキーマを指定することで、それぞれの単位でバックアップファイルを作成します。pg_dumpallも論理バックアップを行い、その対象は「データベースクラスタ」です。実行するとデータベースクラスタ全体のバックアップファイルを作成します。pg_basebackupのバックアップは物理バックアップを行い、対象は「データベースクラスタ」です。
グローバルオブジェクト
データベースクラスタにはグローバルオブジェクトが存在します。グローバルオブジェクトとは、個々のデータベースに属さないロール情報やアクセス制限に関する情報などです。これらは各データベースから共通して使用されます。
WALファイル
WALファイルとは更新情報が書き込まれるファイルです。データベースクラスタの更新よりも先にWALファイルが更新されます。データベースへの更新(INSERT等)が発生した場合、データの更新の順序は下記の通りです。
- データ更新は共有バッファ(メモリ)上のデータで実行されます。
- 更新内容はWALファイルに書き出されます。
- 共有バッファ上のデータ更新は下記のタイミングでデータベースクラスタ内のファイルに反映されます。
- 時間経過や更新量に応じて発生するチェックポイント処理で
- 共有バッファが不足したとき
- バックグラウンドライターの動作で
このようにすることで、データ更新中にデータベースサーバの電源が落ちたり、PostgreSQLサーバプロセスが強制終了されたりしても、次にサービス起動するときには、WALファイルを読み込んで記録されている変更を適用することで、整合性のあるデータ状態に復旧する仕組みになっています。
対応する更新内容をデータベースクラスタに反映し終えたWALファイルは、チェックポイント処理の時に順次削除されます。
バックアップ方法
それではPostgreSQLの具体的なバックアップ方法を見ていきます。
ダンプ
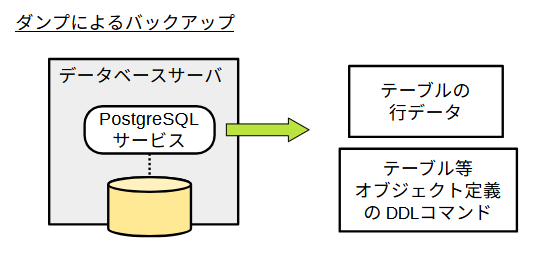
PostgreSQL付属コマンドのpg_dumpとpg_dumpallを使用して、オンライン論理バックアップを取得することができます。このバックアップはダンプと呼ばれます。pg_dumpは1つのデータベース、または、その中の指定スキーマや指定テーブルを対象とします。pg_dumpall はグローバルオブジェクトを含むデータベースクラスタ全体を対象とします。pg_dumpall を -g (--globals-only) オプションで実行して、グローバルオブジェクトのみをバックアップすることも可能です。
pg_dumpとpg_dumpallはPostgreSQLのクライアントアプリケーションとして動作します。したがって、データベースサーバ内からでも、リモートサーバからでもバックアップの取得が可能です。
バックアップファイルの形式は、pg_dumpではテキスト形式かいくつかのバイナリ形式を選択できます。pg_dumpallはテキスト形式のみです。バイナリ形式はpg_restoreでテキスト形式に変換できます(pg_restoreで直接リストアすることもできます)。これらのコマンドはデータ定義だけのバックアップ、データだけのバックアップなども可能です。対象のデータベース、スキーマ、テーブルを限定することもできます。
ダンプは論理バックアップであるため、PostgreSQLのメジャーアップデート時のデータ移行にも利用できます。ただし、PostgreSQL固有のSQL文(COPY等やSET文)が含まれるため、他のデータベースソフトウェアむけにそのまま適用することはできません。pg_dumpに--insertsオプションを指定して、COPY文をINSERT文に変えて出力することはできます。
ベースバックアップ
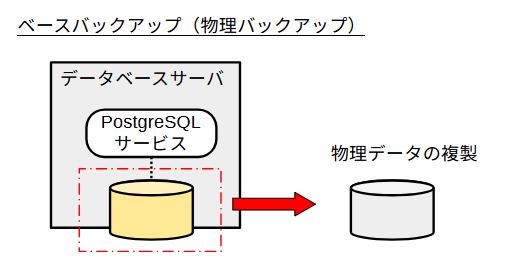
PostgreSQL付属コマンドのpg_basebackupではオンラインの物理バックアップを取得できます。これにより取得するバックアップはベースバックアップと呼ばれます。取得されるのはデータベースクラスタディレクトリのコピー、または、それをいくつかのtar形式のファイルに纏めたものです。デフォルト動作ではバックアップ取得中に生じたWALファイルも取得されます。
ベースバックアップは、動作プラットフォームやPostgreSQLのメジャーバージョンに依存しています。異なる環境むけにリストアすることができません。が異なる場合は利用できません。PostgreSQLマイナーバージョンが異なる環境にはリストア可能ですが追加の対処が必要なケースもあるので、個別のバージョンの情報の確認も必要になります。
ディレクトリをバックアップする任意の手段でベースバックアップを取得することもできます。バックアップの取得前に管理者ユーザ(一般的にはpostgresユーザ)でデータベースに接続し、pg_backup_start()関数を実行して、オフラインバックアップと同様に、OSのコマンドでデータベースのディレクトリ構成を丸ごとコピーして、最後に同じセッションでpg_backup_stop()関数を実行し、応答行のbackup_label列、tablespace_map列の内容をそれぞれ列名と同じファイル名でバックアップ先のデータベースクラスタディレクトリ下に保存します。これらの手順を行なうことで整合性のあるリストアが可能となります。これはpg_basebackupコマンドが内部で実行していることとほぼ同じです。なお、PostgreSQL 14 までは、pg_backup_start()、pg_backup_stop() 関数はそれぞれ、pg_start_backup()、pg_stop_backup() という名前でした。
ベースバックアップ取得は、SQLとしてのデータ参照を行わないため、ダンプ取得と比べると稼働中のPostgreSQLに対する負荷が低いという特徴があります。一般的には取得のための所要時間もより短くなります。
リストア方法
ダンプのリストア
ダンプのリストアは、稼働中のPostgreSQLサービスに対して、ダンプに書かれているSQLを実行することで行います。ダンプを取得開始した時点のデータ状態に戻すことができます。
テキスト形式のダンプをリストアするにはpsqlコマンドでダンプに書かれているSQLを実行します。-f (--file=) オプションで指定する、リダイレクションで標準入力として与える、接続後に \iメタコマンドで読み込む、など、いずれの方法でも構いません。
バイナリ形式のダンプのリストアにはpg_restoreコマンドを使用します。pg_restoreコマンドでテキスト形式に戻して、SQL文をpsqlコマンドで実行することも可能です。
pg_dumpallで取得したテキスト形式のダンプをリストアする場合には、initdb コマンドで初期状態のデータベースクラスタを作成して、そこでPostgreSQLサービスを起動して、そこにpsqlコマンドでダンプファイルを実行します。
ベースバックアップのリストア
ベースバックアップのリストアは、バックアップを元通りのデータベースクラスタディレクトリとして配置して、そこでPostgreSQLサービスを起動することで行います。取得中のWALファイルを含むベースバックアップであれば、起動過程でWALファイルの適用が行われて、バックアップ取得が完了した時点の整合性のあるデータ状態にリストアされます。
WALファイルを含まないベースバックアップのリストアには、別途WALファイルを適用させる手順が必要です。これについて次節で述べます。
ベースバックアップからのリストアは、一般にダンプからのリストアよりも高速です。ダンプからのリストアは全データを復元するSQLの実行であるのに対して、ベースバックアップからのリストアはバックアップ取得中の差分のWALを適用するだけであるからです。
PITR (Point-In-Time Recovery)
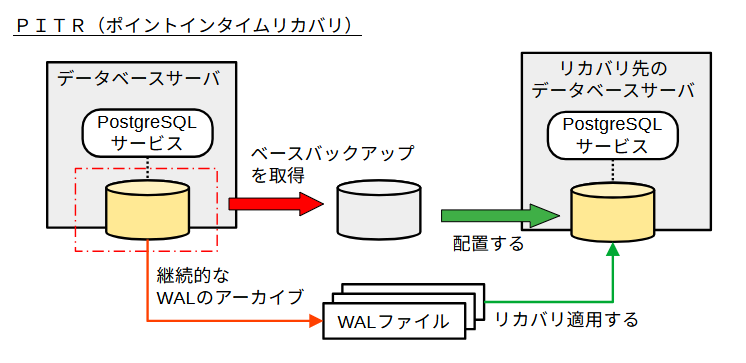
ベースバックアップからのリストアでは、バックアップ取得時だけでなく、その後の任意の時点にリストアすることができます。これを PITR(Point-In-Time Recovery)と呼びます。
PostgreSQL の設定でWALファイルを指定したディレクトリに退避して保管(アーカイブ)させることができます。具体的には、postgresql.conf の archive_modeを on に、archive_commandに WALファイルをアーカイブ格納先にコピーするコマンドを設定します。
古いWAL ファイルは自動的に削除されますが、アーカイブとしてWALファイルを退避してすることで、それらのWAL書き込みがあった時点まで復元することが可能になります。この処理はバックアップ取得の操作とは別個に、バックグラウンドで適時実行されます。ベースバックアップに加えてWALファイルのアーカイブを使うことで、PITRが実現できます。障害が発生した直前までのアーカイブWALをベースバックアップからのリストアに使用することで、RPO を障害直前時点とすることができます。また、誤操作を復旧するために、誤操作した時刻直前を指定してリストアする使い方もできます。
WALアーカイブを使ったベースバックアップからのリストアを行うには、データベースクラスタディレクトリにrecovery.signalファイル(空ファイルで良い)を置いて、postgresql.conf の restore_commandにアーカイブからWALをコピーするコマンドを設定したうえで、PostgreSQLサービスを起動します。
PITRを行うときに復元時点がベースアップ取得時点から離れていると、その分リストアに時間がかかり、保存しておくWALアーカイブも大量に必要となります。そのため、定期的にベースバックアップを取得して、古いベースバックアップを削除して、その削除したベースバックアップのリストアのために必要だったWALもアーカイブから削除していくのが一般的です。あるベースバックアップがどのアーカイブWALファイルまでを必要としているかは、ベースバックアップ時に生成される .backup サフィックスのファイルに書かれています。このファイルは WALと同じディレクトリに作られて、WALと共にアーカイブもされます。pg_archivecleanupコマンドに残したい最も古いベースバックアップに対応した .backupファイルを指定すれば、不要なアーカイブWALファイルを削除してくれますので、これが簡単な方法です。
PITRの具体的な構成手順とリストア手順はPostgreSQLドキュメントに記載があります。
増分バックアップ
PostgreSQL 17以降、pg_basebackupでベースバックアップの増分バックアップを行う-i(--incremental)オプションが利用可能になりました。ベースバックアップを比較的短い周期で何世代も取得する場合、ほとんど同じ内容のバックアップを多数持つことになります。増分バックアップでは、前回のベースバックアップを指定して、それに対するデータベースクラスタの変更分だけをバックアップします。これにより、格納サイズを節約できます。増分バックアップを行うためには、postgresql.conf で summarize_wal = on の設定と、wal_summary_keep_timeにバックアップ周期以上の期間を設定することが必要です。
リストアには完全なフルバックアップとその後に実行した複数の増分バックアップを全てマージする必要があります。マージにはpg_combinebackupコマンドを利用し、フルバックアップのパス、増分バックアップのパス(複数指定可)、出力先を指定して実行します。マージすると完全なベースバックアップが作られて、以降のリカバリ手順は通常のベースバックアップと同じです。
なお、WALファイルも変更差分が書かれたものですが、1つのベースバックアップと大量のWALファイルからリストアするよりも、完全なベースバックアップといくつかの増分バックアップ、少量のWALファイルでリストアする方が、一般的に所要時間が短くて済みます。
設定ファイルのバックアップ
設定ファイルもバックアップが必要です。ダンプバックアップの場合、設定ファイルは対象外ですので、pg_dumpや pg_dumpallコマンドの実行に加えて、postgresql.conf 等の .confファイルを明示的にバックアップ先にコピーしておくことが必要です。pg_basebackupはデータベースクラスタディレクトリをまるまるバックアップするので、設定ファイルもバックアップデータに含まれる結果となります。
まとめ
最後にこれまで説明してきたバックアップ方式について一覧にまとめます。
| バックアップ方式 | 形態 | バックアップコマンド | リストアコマンド | 稼働PostgreSQLへの負荷 | RPO | RTO | 設定ファイル |
|---|---|---|---|---|---|---|---|
| ダンプ(テキスト形式) | オンライン/論理 | pg_dumpall | psql、initdb | やや負荷あり | 取得時点 | やや長時間 | 含まれない |
| ダンプ(バイナリ形式) | オンライン/論理 | pg_dumpall、pg_dump 組み合わせ | psql、pg_restore | やや負荷あり | 取得時点 | やや長時間 | 含まれない |
| ベースバックアップ | オンライン/物理 | pg_basebackup | サービス起動のみ | 低負荷 | 取得時点 | 短時間 | 含まれる |
| ベースバックアップ/PITR | オンライン/物理 | pg_basebackup と WALアーカイブ設定 | サービス起動のみ | 低負荷 | 障害直前または任意時点 | WAL数次第 | 含まれる |
| 差分ベースバックアップ | オンライン/物理 | pg_basebackup | pg_combinebackupとサービス起動 | 低負荷 | 取得時点 | 差分数次第 | 含まれる |
| 差分ベースバックアップ/PITR | オンライン/物理 | pg_basebackup と WALアーカイブ設定 | pg_combinebackupとサービス起動 | 低負荷 | 障害直前または任意時点 | WAL数、差分数次第 | 含まれる |
| オフラインバックアップ | オフライン/物理 | OSコマンド | OSコマンド | 要サービス停止 | 取得時点 | 短時間 | 含まれる |
本稿がPostgreSQLバックアップ方式の検討、選定に役立てば幸いです。