
はじめに
本記事では複数台のマシンを用いて Kafka クラスターを構築し、簡単な動作確認を行います。構築には Ansible を用いて、動作に必要な最低限の設定を行います。使用するバージョンは以下の通りです。
| 名前 | バージョン |
|---|---|
| Rocky Linux | 9.5 |
| Apache Kafka | 4.0.0 |
| Ansible | 2.15.13 |
Kafka について
Apache Kafka はストリーミング処理を実現するための OSS です。複数台のマシンで並列分散処理を行わせることができ、高いスケーラビリティ、障害耐性、低いレイテンシといった特徴があります。複数台のマシンでクラスターを構成するため、Ansible を使ってクラスター全体を構築すると楽です。
簡単な動作確認ができる Docker 環境も用意されているのですが、ここでは各マシンに Kafka のバイナリを配置することから始めてクラスターを構築します。Docker 環境で Kafka の動作を試す方法についてはこちらの記事をご覧ください。
Ansible について
Ansible はサーバ構築を自動化するための OSS です。サーバ構築をコード化できるので同時に構築するサーバ数を増やしたりインストールするパッケージを変更したりするのも容易です。コードを見ればサーバの仕様が分かるようにもなります。
サーバ構築のコードを書く際、実行のたびにサーバーの状態が変わってしまうコードになることがあります。そのため何回実行してもサーバの状態が同じになる(このような性質を冪等性と言います)ように気を付ける必要があります。本記事でも冪等性を適宜確認しながら進めます。
今回構築するクラスターの概要
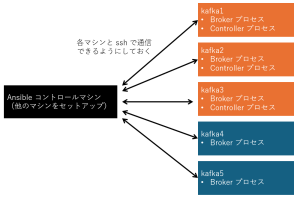
本記事では Broker プロセスが合計5つ、Controller プロセスが合計3つのクラスターを構築します。これらを5台のマシン(Broker とController のプロセスを動かす kafka1~3+Broker のみの kafka4, 5)で稼働させます。 加えてAnsible のコントロールマシンを立てて Kafka クラスター5台の操作を行います。
Ansible のコントロールマシンと Kafka クラスター5台は ssh で通信できるように設定しておきます。 また dnf によるパッケージインストール時など、root 権限を取得することがあるので構築対象サーバで Ansible を実行するユーザーには sudo 権限を与えておきます。
Ansible ディレクトリ構造
$ tree
.
├── README
├── group_vars
│ └── kafka_cluster.yaml
├── host_vars
│ ├── kafka1.yaml
│ ├── kafka2.yaml
│ ├── kafka3.yaml
│ ├── kafka4.yaml
│ └── kafka5.yaml
├── inventory.ini
├── roles
│ ├── common
│ │ └── templates
│ │ └── kafka_service_template.j2
│ ├── java
│ │ └── tasks
│ │ └── main.yaml
│ ├── kafka_broker
│ │ ├── tasks
│ │ │ └── main.yaml
│ │ └── vars
│ │ └── main.yaml
│ ├── kafka_cluster
│ │ ├── files
│ │ │ └── kafka_2.13-4.0.0.tgz
│ │ └── tasks
│ │ └── main.yaml
│ ├── kafka_controller
│ │ ├── tasks
│ │ │ └── main.yaml
│ │ └── vars
│ │ └── main.yaml
│ ├── terminate_kafka_broker
│ │ └── tasks
│ │ └── main.yaml
│ └── terminate_kafka_controller
│ └── tasks
│ └── main.yaml
├── setup_servers.yaml
└── terminate_servers.yaml
20 directories, 20 files今回、Kafka の環境準備から設定ファイルの編集、起動 までを行う Playbook(setup_servers.yaml)と Kafka の終了を行う Playbook(terminate_servers.yaml)を作成しました。
playbook 全体の流れ
setup_servers.yaml を以下に示します。
- name: Setup kafka_broker_controller
hosts: kafka_broker_controller
roles:
- java
- kafka_cluster
- kafka_controller
- kafka_broker
- name: Setup kafka_broker
hosts: kafka_broker
roles:
- java
- kafka_cluster
- kafka_brokerterminate_servers.yaml を以下に示します。
- name: Terminate kafka_broker
hosts: kafka_broker
roles:
- terminate_kafka_broker
- name: Terminate kafka_broker_controller
hosts: kafka_broker_controller
roles:
- terminate_kafka_broker
- terminate_kafka_controller各タスクは以下の通りです。
| name | 説明 |
|---|---|
| Setup kafka_broker_controller | kafka1、kafka2、kafka3 で Broker と Controller のプロセスを起動 |
| Setup kafka_broker | kafka4、kafka5 で Broker プロセスを起動 |
| Terminate kafka_broker | kafka4、kafka5 の Broker プロセスを終了 |
| Terminate kafka_broker_controller | kafka1、kafka2、kafka3 の Broker と Controller のプロセスを終了 |
各role は以下の通りです。
| role | 説明 |
|---|---|
| java | Java のインストール |
| kafka_cluster | Kafka クラスタ共通のタスク(Kafka バイナリの配布) |
| kafka_controller | Controller の設定+起動 |
| kafka_broker | Broker の設定+起動 |
| terminate_kafka_broker | Broker の停止 |
| terminate_kafka_controller | Controller の停止 |
Controller プロセスは Broker プロセスより先に起動するようにしてあります。Broker プロセスの動作のためにはController が必要だからです。プロセスの終了では逆に Broker プロセスを先に終了させています。
Java のインストール
roles/java/task/main.yaml に Java のインストールを行うタスクを記載しています。
- name: Ensure openjdk21 present
ansible.builtin.dnf:
name: java-21-openjdk
state: present
become: true
ansible.builtin.dnf では name にパッケージ名、state に実行後どんな状態であるべきかを指定することでパッケージのインストール、アンインストールを行うことができます。state に指定できる状態は以下の通りです。
| 設定値 | 説明 |
|---|---|
| present | パッケージがインストールされた状態にします。すでにインストールされている場合は何もしません。installed と同じです。 |
| latest | パッケージが最新版にアップデートされた状態にします。未インストールの場合はインストールします。 |
| absent | パッケージがアンインストールされた状態にします。removed と同じです。 |
2回目以降の実行でバージョンが変わらないようにここでは present を使っています。
Kafka バイナリの配置
roles/kafka_cluster/task/main.yaml に Kafka バイナリの配置を行うタスクを記載しています。
- name: Unarchive kafka file
ansible.builtin.unarchive:
src: ./roles/kafka_cluster/files/{{kafka_dir}}.tgz
dest: '{{install_dir}}'
creates: '{{install_dir}}/{{kafka_dir}}'
ansible.builtin.unarchive では src に Ansible 環境上のアーカイブファイル、dest に構築対象サーバの展開先ディレクトリを指定することでアーカイブファイルの展開ができます。このように設定するとアーカイブファイルを構築対象サーバに送信した後展開処理は構築対象サーバ上で行うという挙動になります。ここではあらかじめ ./roles/kafka_cluster/files/ に置いておいた kafka_2.13-4.0.0.tgz を各サーバで展開しています(変数 kafka_dir と install_dir は group_vars/kafka_cluster.yaml で定義しています)。
構築対象サーバでアーカイブファイルのダウンロード、展開をさせるという方法も考えられます。どのような方法を採用するかは各環境によるでしょう。
また creates に展開後ディレクトリのパスを指定すると、そのディレクトリがすでに存在する場合タスクをスキップさせることができます。
creates がない場合、2回目以降の実行で ansible.builtin.unarchive は展開後のファイルが変更されていないか確認し、変更があれば元の状態に戻すという動きをします。その動きで時間がかからないようにここでは creates を使っていますが、再展開させる必要がある場合は creates を削除するとよいでしょう。
設定
Broker の設定
roles/kafka_broker/task/main.yaml に Broker の設定を行うタスクを記載しています。
- name: Set node.id
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^node.id='
line: node.id={{node_id_broker}}
- name: Unset controller.quorum.bootstrap.servers
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^controller.quorum.bootstrap.servers='
line: '# controller.quorum.bootstrap.servers='
- name: Set controller.quorum.voters
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^#controller.quorum.voters='
line: 'controller.quorum.voters=201@{{ hostvars["kafka1"].ansible_host }}:9093,202@{{ hostvars["kafka2"].ansible_host }}:9093,203@{{ hostvars["kafka3"].ansible_host }}:9093'
- name: Set listeners
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^listeners='
line: listeners=PLAINTEXT://{{ansible_host}}:9092
- name: Unset advertised.listeners
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^advertised.listeners='
line: '# advertised.listeners='
ansible.builtin.lineinfile では行の置き換えや挿入、削除ができます。ここでは path に指定したファイル内の regexp にマッチした行を line で指定した文字列で置き換えています。
path に指定している path_to_properties ですが、roles/kafka_broker/vars/main.yaml にて kafka_2.13-4.0.0/configs/broker.properties になるように指定しています。つまり kafka_2.13-4.0.0.tgz に同梱されている Broker 用の設定ファイルから設定に必要な行を書き換えています。
regexp にマッチする行がなかった場合は、line に指定した文字列と同じ内容の行があれば何もしない、なければファイル末尾に line の行を挿入するという挙動になります。そのため複数回実行しても同じ内容が挿入され続けることはなく、冪等性が保たれています。
変更している設定値は以下の通りです。ここで Quorum について、静的 Quorum または動的 Quorum が使用できますが今回は静的 Quorum を採用しています。
| 設定値 | 説明 |
|---|---|
| node.id | 各 Broker または Controller固有の ID で、被りがあってはいけません。変数 node_id_broker はホストごとに指定しています。 |
| controller.quorum.bootstrap.servers | 動的 Quorum を採用する場合は、こちらの設定にすべての Controller を {host}:{port} の形でカンマ区切りで指定します。今回静的 Quorum なのでコメントアウトしています。 |
| controller.quorum.voters | 静的 Quorum を採用する場合、こちらの設定にすべての Controller を {node.id}@{host}:{port} の形でカンマ区切りで指定します。 |
| listeners | 接続を受け付けるリスナーを {リスナー名}://{host}:{port} で指定します。リスナー名ごとにセキュリティプロトコルが listener.security.protocol.map で指定でき、ここでは PLAINTEXT は認証や暗号化のないリスナーを表しています。 |
| advertised.listeners | Kafka クライアントからの接続に使うリスナーを指定します。これが設定されていなければ listeners の設定値が使われます。今回は同じで良いのでコメントアウトしています。 |
Controller の設定
roles/kafka_controller/task/main.yaml に Controller の設定を行うタスクを記載しています。
- name: Set node.id
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^node.id='
line: node.id={{node_id_controller}}
- name: Unset controller.quorum.bootstrap.servers
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^controller.quorum.bootstrap.servers='
line: '# controller.quorum.bootstrap.servers='
- name: Set controller.quorum.voters
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^#controller.quorum.voters='
line: 'controller.quorum.voters=201@{{ hostvars["kafka1"].ansible_host }}:9093,202@{{ hostvars["kafka2"].ansible_host }}:9093,203@{{ hostvars["kafka3"].ansible_host }}:9093'
- name: Set listeners
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^listeners='
line: listeners=CONTROLLER://{{ansible_host}}:9093
- name: Unset advertised.listeners
ansible.builtin.lineinfile:
path: '{{path_to_properties}}'
state: present
regexp: '^advertised.listeners='
line: '# advertised.listeners='
Controller 側の設定もほとんど同じですが、node_id は Controller 用、listeners はリスナー名が CONTROLLER、ポート番号が 9093 になっています。CONTROLLER も認証や暗号化のないリスナーを表しています。
起動
ログディレクトリのフォーマット
roles/kafka_broker/task/main.yaml と roles/kafka_controller/task/main.yaml にログディレクトリのフォーマットを行うタスクを記載しています。内容は同じです。
- name: Format Log Directory
ansible.builtin.shell:
cmd: bin/kafka-storage.sh format -t {{kafka_cluster_id}} -c {{path_to_properties}} --ignore-formatted
chdir: '{{install_dir}}/{{kafka_dir}}/'
ansible.builtin.shell は cmd に指定したコマンドを chdir で指定したディレクトリ上で実行します。コマンドをただ実行するだけのモジュールのため、冪等性の確保等は行いません。Kafka 起動前には Broker と Controller それぞれでログディレクトリのフォーマットが必要ですが、それは kafka_2.13-4.0.0.tgz の bin ディレクトリにある kafka-storage.sh を使って実行します。shell モジュールは冪等性の観点では避けるべきモジュールですが、kafka-storage.sh を使うために今回は使用しています。
kafka-storage.sh format とすればフォーマットを行います。オプションは以下の通りです。
| オプション | 説明 |
|---|---|
| -t {クラスターID} | クラスター全体で共通な ID を指定します。変数 kafka_cluster_id は group_vars/kafka_cluster.yaml でクラスター共通な変数として定義しています。 |
| -c {設定ファイル} | サーバの設定ファイルを指定します。 |
| –ignore-formatted | すでにフォーマットが済んでいた場合エラーにせず正常終了させます。このオプションがあることで冪等性を保つことができます。 |
サービスファイルの作成
roles/kafka_broker/task/main.yaml と roles/kafka_controller/task/main.yaml にサービスファイルを作成するタスクを記載しています。内容は同じです。
- name: Copy template of kafka broker service file
ansible.builtin.template:
src: ./roles/common/templates/kafka_service_template.j2
dest: /etc/systemd/system/kafka-broker.service
become: trueansible.builtin.template は構築対象サーバにテンプレートファイルをコピーします。その際テンプレートファイル内の変数を変数の値に置き換えた上でコピーします。ここでは src に指定した Ansible サーバ上のテンプレートファイルを dest で指定した構築対象サーバ上のファイルにコピーします。
テンプレートファイルは以下の通りです。
roles/common/templates/kafka_service_template.j2
[Unit]
Description=Kafka server ({{process_role}})
Documentation=https://kafka.apache.org/documentation/
[Service]
Type=simple
Environment="LOG_DIR=/var/log/kafka/{{process_role}}"
ExecStart={{install_dir}}/{{kafka_dir}}/bin/kafka-server-start.sh {{path_to_properties}}
ExecStop={{install_dir}}/{{kafka_dir}}/bin/kafka-server-stop.sh --process-role={{process_role}}
[Install]
WantedBy=multi-user.targetこのようなサービスファイルを用いて systemctl で Kafka の起動が行えるようにすることで起動状態の管理を楽にしています。
変数 process_role と path_to_properties は、Broker 用と Controller 用で変わるようになっていて、Broker か Controller かによってサービスファイルの内容が変わるようになっています。
Environment として LOG_DIR を設定していますが、これによってログ出力先(Kafka でやり取りされるメッセージという意味のログではなく、サーバのエラー等を出力するログのこと)を指定できます。
ExecStart では起動コマンドを指定しますが、kafka_2.13-4.0.0.tgz の bin ディレクトリにある kafka-server-start.sh を使用します。kafka-server-start.sh {設定ファイルのパス} と実行することで起動しますが、設定ファイルが Broker のものなら Brokerが、Controller のものなら Controller が起動します。
ExecStop では終了コマンドを指定しますが、kafka_2.13-4.0.0.tgz の bin ディレクトリにある kafka-server-stop.sh を使用します。kafka-server-stop.sh は引数なしだとそのマシン上のすべての Kafka プロセスを終了させてしまうため、--process-role を指定することで指定したプロセスのみを終了させています。
このように Kafka の起動、終了にもスクリプトを使うのですが、systemctl を使うようにすることで ansible.builtin.systemd_service モジュールを使用できるので shell モジュールを避けることができます。
起動
roles/kafka_broker/task/main.yaml に Broker プロセスを起動するタスクを記載しています。
- name: Start Kafka broker
ansible.builtin.systemd_service:
name: kafka-broker.service
state: started
daemon_reload: true
become: trueansible.builtin.systemd_service は name で指定したサービスを state で指定した状態にします。今回は起動した状態にしたいので started としています。
daemon_reload:true としているのは起動前に systemctl daemon-reload を実行し直前でコピーしたサービスファイルを読み込ませるためです。
roles/kafka_controller/tasks/main.yaml に Controller プロセスを起動するタスクを記載しています。
- name: Start Kafka controller
ansible.builtin.systemd_service:
name: kafka-controller.service
state: started
daemon_reload: true
become: true起動させるのが Controller であること以外は Broker の場合と同じです。
終了
roles/terminate_kafka_broker/tasks/main.yaml に Broker プロセスを終了するタスクを記載しています。
- name: Stop kafka broker
ansible.builtin.systemd_service:
name: kafka-broker.service
state: stopped
become: trueansible.builtin.systemd_service で state を stopped にすることで Broker プロセスを終了させています。
roles/terminate_kafka_controller/tasks/main.yaml に Controller プロセスを終了するタスクを記載しています。
- name: Stop kafka controller
ansible.builtin.systemd_service:
name: kafka-controller.service
state: stopped
become: true
対象が Controller になっている点以外は Broker の場合と同じです。
Playbook 実行
実行コマンドは以下の通りです。
$ ansible-playbook -i inventory.ini setup_servers.yaml --ask-become-pass -v
$ ansible-playbook -i inventory.ini terminate_servers.yaml --ask-become-pass -v
動作確認
Kafka クラスターの動作確認としてトピック作成、Produce、Consume を行います。ここでは kafka_2.13-4.0.0.tgz の bin ディレクトリにある kafka-topics.sh、kafka-console-producer.sh、kafka-console-consumer.sh を用います。
- トピックの作成は以下のように行います。
$ ./bin/kafka-topics.sh --bootstrap-server kafka_controller1.example.com:9092 --create --topic test --partitions 5 --replication-factor 5
Created topic test.kafka-topics.sh でトピックを作成できます。--bootstrap-server kafka_controller1.example.com:9092
で接続先の Broker を指定するので環境によって変えます。成功すれば Created topic test. と出力されます。
- メッセージの Produce、Consume は以下のように行います。
ターミナルを2つ開いておきます。
Producer 側のターミナルではkafka-console-producer.sh を用います。
$ ./bin/kafka-console-producer.sh --bootstrap-server kafka_controller1.example.com:9092 --topic test
>hoge #プロンプトが表示されたら入力Consumer 側のターミナルでは kafka-console-consumer.sh を用います。
$ ./bin/kafka-console-consumer.sh --bootstrap-server kafka_controller1.example.com:9092 --topic test --from-beginning hoge #Producer 側で入力すると表示される
Producer 側で入力した内容が Consumer 側で表示されれば成功です。メッセージの送受信ができることが確認できました。
おわりに
今回は Kafka クラスターの動作に必要な最低限の設定方法をご紹介しました。
同じように Kafka クラスターを構築する方の助けとなれば幸いです。