1. はじめに
SQLのビッグデータ対応が取りざたされて久しいですが,その現状を調査した結果を報告します.よく知られているように,SQL は SQL-87 の登場以来,SQL-92, SQL:1999, SQL:2003, SQL:2006, SQL:2008, SQL:2011, SQL:2016 と改正されて現在に至っています.
SQL:2016(ISO / IEC 9075:2016)は ISO が 2016 年 12 月にリリースした SQL の最新バージョンで,そこでは,44 の新しいオプション機能が導入され,そのうちの 22 個は JSON 連携機能に属し、10 個は多態表関数(polymorphic table functions)に関連し,加えて listtag(集計関数)機能と行パターン認識(row pattern recognition)機能が規格化されています.これらの機能はそれぞれの理由でビッグデータ処理に関連していると言えますが,中でも「行パターン認識」はテーブルの行を整列しておいて,このデータストリームからパターンマッチングで所望の出力を得るための機能であり,機械学習に依らない人工知能の取組の一種とも考えられ,大変興味深い機能です.行パターン認識は,Oracle 社が提案して標準化されたと言われています.この機能はさらに 行パターン認識:FROM 句 と 行パターン認識:WINDOW 句 の 2 つの機能に分かれます.前者は Oracle Database で実装されており,Oracle Database にはこの機能を必要とするユースケースがあったということでしょう.
以下,本稿では「行パターン認識:FROM 句」を例題を交えて説明しますが,OSS のリレーショナル DBMS として認知度の高い PostgreSQL ではまだこの機能はサポートされていないようで,残念ながら本稿に示す例題のすべてをPostgreSQL 14 で試してみることはできないのが現状です.
2. 行パターン認識:FROM 句とは
「行パターン認識:FROM 句」は,識別したいパターンを記述するために MATCH_RECOGNIZE 句を問合せ(query)の FROM 句で指定する機能です.問合せの入力は表または表式で,出力は仮想テーブル(virtual table.物理的には存在しないが,必要な場合にのみマテリアライズされるテーブル)です.まず,この機能を使用した問合せ構文を示すことから始めます.
■ 行パターン認識:FROM 句 を用いた問合せ構文

MATCH_RECOGNIZE 句,PARTITION BY 句,ORDER BY 句,MEASURES 句,row pattern rows per match>オプション,AFTER MATCH 句,PATTERN 句,SUBSET 句,DEFINE 句の説明は,次章で例題を交えて与えます.
3. 行パターン認識:FROM句 の例題による説明
さて,ISO/IEC の技術報告書(ISO/IEC TR 19075-5)に与えられた例に基づき「行パターン認識:FROM 句」を説明します.具体的には,下に示すコードを使用してテーブルを作成し,サンプルデータを入力し,それに問合せを発行することにします.ここに,Ticker は,symbol, tradedate, price を列とするテーブルで,ticker は(株式)相場表示機,symbol は銘柄,tradedate は取引年月日,price は株価を表しています.この例の解説は文献[1]に詳しく,それを参考にしています.
まず,Ticker テーブルの生成とサンプルデータの入力は PostgreSQL 14 で行えます.それは次の通りです.
■ Ticker テーブルの生成とサンプルデータの入力
Ticker テーブルの生成とサンプルデータの入力を PostgreSQL 14 で行うと,次の通りです.
【例題 1】(Ticker テーブルの生成とサンプルデータの入力)
postgres=# CREATE TABLE Ticker
postgres-# (
postgres(# symbol VARCHAR(10) NOT NULL,
postgres(# tradedate DATE NOT NULL,
postgres(# price NUMERIC(12, 2) NOT NULL,
postgres(# CONSTRAINT PK_Ticker
postgres(# PRIMARY KEY (symbol, tradedate)
postgres(# );
CREATE TABLE
postgres=#
postgres=# INSERT INTO Ticker(symbol, tradedate, price) VALUES
postgres-# ('STOCK1', '20190212', 150.00), ('STOCK1', '20190213', 151.00), ('STOCK1', '20190214', 148.00),
postgres-# ('STOCK1', '20190215', 146.00), ('STOCK1', '20190218', 142.00), ('STOCK1', '20190219', 144.00),
postgres-# ('STOCK1', '20190220', 152.00), ('STOCK1', '20190221', 152.00), ('STOCK1', '20190222', 153.00),
postgres-# ('STOCK1', '20190225', 154.00), ('STOCK1', '20190226', 154.00), ('STOCK1', '20190227', 154.00),
postgres-# ('STOCK1', '20190228', 153.00), ('STOCK1', '20190301', 145.00), ('STOCK1', '20190304', 140.00),
postgres-# ('STOCK1', '20190305', 142.00), ('STOCK1', '20190306', 143.00), ('STOCK1', '20190307', 142.00),
postgres-# ('STOCK1', '20190308', 140.00), ('STOCK1', '20190311', 138.00), ('STOCK2', '20190212', 330.00),
postgres-# ('STOCK2', '20190213', 329.00), ('STOCK2', '20190214', 329.00), ('STOCK2', '20190215', 326.00),
postgres-# ('STOCK2', '20190218', 325.00), ('STOCK2', '20190219', 326.00), ('STOCK2', '20190220', 328.00),
postgres-# ('STOCK2', '20190221', 326.00), ('STOCK2', '20190222', 320.00), ('STOCK2', '20190225', 317.00),
postgres-# ('STOCK2', '20190226', 319.00), ('STOCK2', '20190227', 325.00), ('STOCK2', '20190228', 322.00),
postgres-# ('STOCK2', '20190301', 324.00), ('STOCK2', '20190304', 321.00), ('STOCK2', '20190305', 319.00),
postgres-# ('STOCK2', '20190306', 322.00), ('STOCK2', '20190307', 326.00), ('STOCK2', '20190308', 326.00),
postgres-# ('STOCK2', '20190311', 324.00);
INSERT 0 40
postgres=#
postgres=# SELECT symbol, tradedate, price FROM Ticker;
symbol | tradedate | price
---------+-------------+--------
STOCK1 | 2019-02-12 | 150.00
STOCK1 | 2019-02-13 | 151.00
STOCK1 | 2019-02-14 | 148.00
STOCK1 | 2019-02-15 | 146.00
STOCK1 | 2019-02-18 | 142.00
STOCK1 | 2019-02-19 | 144.00
STOCK1 | 2019-02-20 | 152.00
STOCK1 | 2019-02-21 | 152.00
STOCK1 | 2019-02-22 | 153.00
STOCK1 | 2019-02-25 | 154.00
STOCK1 | 2019-02-26 | 154.00
STOCK1 | 2019-02-27 | 154.00
STOCK1 | 2019-02-28 | 153.00
STOCK1 | 2019-03-01 | 145.00
STOCK1 | 2019-03-04 | 140.00
STOCK1 | 2019-03-05 | 142.00
STOCK1 | 2019-03-06 | 143.00
STOCK1 | 2019-03-07 | 142.00
STOCK1 | 2019-03-08 | 140.00
STOCK1 | 2019-03-11 | 138.00
STOCK2 | 2019-02-12 | 330.00
STOCK2 | 2019-02-13 | 329.00
STOCK2 | 2019-02-14 | 329.00
STOCK2 | 2019-02-15 | 326.00
STOCK2 | 2019-02-18 | 325.00
STOCK2 | 2019-02-19 | 326.00
STOCK2 | 2019-02-20 | 328.00
STOCK2 | 2019-02-21 | 326.00
STOCK2 | 2019-02-22 | 320.00
STOCK2 | 2019-02-25 | 317.00
STOCK2 | 2019-02-26 | 319.00
STOCK2 | 2019-02-27 | 325.00
STOCK2 | 2019-02-28 | 322.00
STOCK2 | 2019-03-01 | 324.00
STOCK2 | 2019-03-04 | 321.00
STOCK2 | 2019-03-05 | 319.00
STOCK2 | 2019-03-06 | 322.00
STOCK2 | 2019-03-07 | 326.00
STOCK2 | 2019-03-08 | 326.00
STOCK2 | 2019-03-11 | 324.00
(40 行)
■ 株価が V 字型を表すパターンの識別
「行パターン認識:FROM 句」を用いたパターンの識別(=一致)は MATCH_RECOGNIZE 句で記述します.row pattern rows per match> オプションとして ONE ROW PER MATCH を使用して,株価が V 字型を表すパターン(厳密に株価が下がる期間とそれに続く厳密に株価が上がる期間)を識別する問合せを書き下してみると次のようになります.
【例題 2】(株価が V 字型を表すパターンを識別する問合せ)

例題 2 の補足説明を行います.
- PARTITION BY 句は,各銘柄記号を個別に処理することを定義しています.
- ORDER BY 句は,取引日に基づく順番を定義しています.
- MEASURES 句は,パターンに関連する尺度を定義しています.
- MATCH_NUMBER( ) 関数は,パーティション内の一致に1から始まる連続した整数を割り当てます.集計計算のみならず FIRST,LAST,PREV,NEXT などの操作を使用できます.
- PATTERN 句は,行パターン変数とパターン限定子を用いて次章で示されるような規則に従って定義される正規表現(regular expression)を使用してパターンを記述しています.例題 2 のパターンの正規表現は (A B + C +) ですが,これは(株価が下落している 1 つ以上の行が続き、その後に株価が上昇している 1 つ以上の行が続く,任意の行)を示しています.
- SUBSET 句を使用することで,変数の名前付きサブセットリストを定義できます.
- DEFINE 句は,パターン内の行のさまざまなサブシーケンスを表す行パターン変数(row pattern variable)を定義しています.例題 2 では,行パターン変数 A は開始点として任意の行を表し,B は値下がりのサブシーケンス(B.price
PREV(B.price))を表し,C は値上がりのサブシーケンス(C AS C.price>PREV(C.price))を表しています.
例題 2 は,row pattern rows per match> オプションとして ONE ROW PER MATCH を使用していますが,これは,グループ化の結果と同様に,結果テーブルのパターンマッチごとに 1 つの行があることを意味しています.これとは別に,パターンマッチごとに詳細行を返す場合の ALL ROWS PER MATCH があります.
例題2は,AFTER MATCH skip to option> として AFTER MATCH SKIP PAST LAST ROW を使用していますが,これは,一致が見つかったら,現在の一致の最後の行の後に次の試行を開始することを意味しています.現在の一致の最初の行に続く行で次の一致を探す(SKIP TO NEXT ROW),または行パターン変数に相対的な位置にスキップするなど,他の選択肢があります.
以上,例題2に示した問合せの出力は次の通りとなります.
symbol matchnum startdate startprice bottomdat bottomprice enddate endprice maxprice
--------- ------- ---------- ---------- ---------- ----------- ---------- -------- --------
STOCK1 1 2019-02-13 151.00 2019-02-18 142.00 2019-02-20 152.00 152.00
STOCK1 2 2019-02-27 154.00 2019-03-04 140.00 2019-03-06 143.00 154.00
STOCK2 1 2019-02-14 329.00 2019-02-18 325.00 2019-02-20 328.00 329.00
STOCK2 2 2019-02-21 326.00 2019-02-25 317.00 2019-02-27 325.00 326.00
STOCK2 3 2019-03-01 324.00 2019-03-05 319.00 2019-03-07 326.00 326.00
つまり,株価が V 字型を表すパターンが 5 つ見つかっています.一つ目は,銘柄 STOCK1 で,2019-02-13 に株価が 151.00 であったが,2019-02-18 に株価が 142.00 と下落し,それを底値にして 2019-02-20 に株価が 152.00 に上昇しました.この一つ目のパターンの株価の最高値は 152.00 です.他の 4 つについても同様な説明がなされます.
なお,前述の通り,PostgreSQL 14 では「行パターン認識:FROM 句」を用いた行パターンマッチング機能がサポートされていないので,上述の結果は Oracle Database での実行結果であろうと推察される文献[1]の説明に依っています.
4. 正規表現とパターン限定子
行パターン認識の肝はパターンを記述する「正規表現」にあるので,正規表現とそのためのパターン限定子について少し詳しく説明します.
まず,正規表現(regular expression, regexp.正則表現ともいう)の定義構文を図 1 に示します.ここに, | は,例えば A | B のように代替(alternative)を示し,( と ) は,例えば(A | B)というようにグループ化を示します.
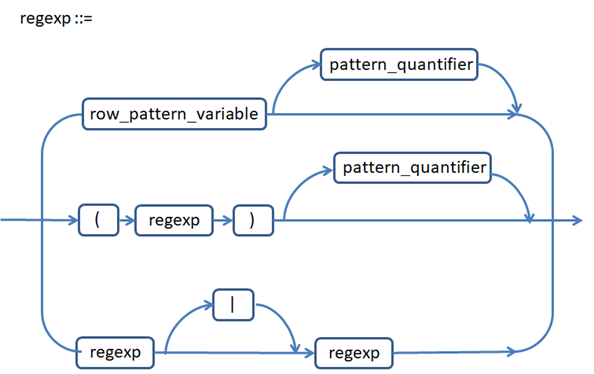
図 1 正規表現の定義
続いて,指定できる正規表現のためのパターン限定子を表 1 に示します.
表 1 正規表現のためのパターン限定子
| ゼロ(0)以上の一致 | |
| 1 つ以上の一致 | |
| 一致しない,または 1 つ一致,オプション | |
| 正確に n 個一致 | |
| n 個以上の一致 | |
| n と m の間(両端を含む)の一致 | |
| ゼロ(0)と m(両端を含む)の一致 | |
| 例:{ - A - }.一致する行が出力から除外されることを示す (ALL ROWS PER MATCH が指定されている場合にのみ役立つ) |
|
| 例:^ A {1, 3}.行パターンパーティションの開始 | |
| 例:A {1, 3} $.行パターンパーティションの終わり |
なお,例えば A のように,限定子が付いていない行パターン変数には,正確に 1 つの一致を必要とする限定子があると見なされます.
ここで,行パターンの簡単な例をいくつか挙げておきます[2].
- (A+ B+): A が 1 回以上,その後に B が 1 回以上,が続く.
- (A+ (C+ B+)*): A が 1 回以上,その後に C が 1 回以上で B が 1 回以上が 0 回以上発生する.
- (A+ | B+): A が 1 回以上,または B が 1 回以上,いずれかが先に起こる.
- (A+ (C+ | B+)): A が 1 回以上,その後に C が 1 回以上,または B が 1 回以上,のいずれか先に起こる.
- ((A B) | (B A)):A の後に B,または B の後に A,のいずれかが先に起こること
なお,例題 2 では,V 字型(下,上)を識別する問合せを書き表しましたが,W 字型(下,上,下,上)を表すパターンを識別する行パターンは次のように書けるでしょう.
【例題 3】(株価がW字型を表すパターンを識別する行パターン)

さまざまな状況において,行パターンを適切に定義することによって,例えば,大量の株取引,疑わしい資金移動や異常な金融取引,アクセスログ等を対象にした異常検出など,行パターン認識:FROM 句 が活躍しそうなユースケースは多々ありそうです.
5.おわりに
改めて,SQL:2016 で規格化された行パターン認識機能の意義について述べておきます.行パターン認識:FROM 句 は Oracle Database でサポートされているようですが,行パターン認識:WINDOW 句 の実装はまだのようです.冒頭でも記しましたが,PostgreSQL は OSS のリレーショナル DBMS としてさまざまな分野で受け入れられているにも関わらず,行パターン認識機能は一切サポートされていないようです.一刻も早くに実装されるべきではと思います.なぜならば,データサイエンスの意義が強く認識されている昨今,いわゆる機械学習とは一線を画する,つまり機械学習やデータマイニングに頼ることなく人工知能を実現していく手法として「データ参照」の有用性に言及している書籍[3]を目にすることがありますが,筆者もその見解に大いに賛同するところです.つまり,本来のリレーショナルデータベース(=SQL)の枠組みの中に「行パターン認識」という機能を組込むことにより,それまでは機械学習やデータマイニングの領分とされてきたようなデータ処理が可能となるわけですから,リレーショナルデータベースのアプリケーション開発の現場やデータサイエンティストにとっては,新たな武器が一つ加わったと捉えてよいのではないでしょうか.このようなアプローチの今後の展開に期待したいと思います.
なお,SQL のビッグデータ対応の一般論に話を戻せば,SQL 標準は 5 年ごとに見直されるようですが,SQL:2016 に続く改正は少しばかり遅れていて,SQL:2022 となるようです.そこでは SQL のグラフ問合せ機能を規格化することに力点が置かれて作業が行われているそうです[4].グラフデータモデルはキー・バリューデータモデル,列ファミリデータモデル,JSON と並んで NoSQL を標榜するデータストアがサポートするデータモデルです[5].冒頭で記したように JSON 機能は SQL:2016 で規格化されているので,次の焦点をグラフデータモデルに合せたということなのでしょう.
【文献】
[1]
|
Itzik Ben-Gan. Row Pattern Recognition in SQL, April 10, 2019. https://sqlperformance.com/2019/04/t-sql-queries/row-pattern-recognition-in-sql |
[2]
|
Chapter 21 Pattern Recognition With MATCH_RECOGNIZE, Fusion Middleware CQL Language Reference for Oracle Event Processing. Oracle Help Center, https://docs.oracle.com/cd/E29542_01/apirefs.1111/e12048/pattern_recog.htm#CQLLR1531 |
[3]
| 柴原一友,築地毅,古宮嘉那子,宮武孝尚,小谷善行.機械学習教本,森北出版,2019. |
[4]
|
土田正士.次期 SQL:2022 はどのような仕様になるのか?~ビッグデータ対応の次世代 SQL DBMS が NoSQL を取り込み進化を継続~.日本データベース学会 最強データベース講義,2021 年 11 月 17 日 https://dblectures.connpass.com/event/229270/ |
[5]
| 増永良文.リレーショナルデータベース入門[第3版].サイエンス社,2017. |