この記事は SRA Advent Calendar 2025 23日目の記事です。
PostgreSQL が基幹系 DB などに採用されるケースが増えるとともに、そのデータを外部にニアリアルタイムで取り出して、負荷分散や分析などの用途で利活用したいケースが増えています。
このようなニーズに対して、Debezium は PostgreSQL の WAL をデコードし、テーブルの変更を自動検知・配信できる OSS です。本記事では、その仕組みや構成例、運用上の注意点を紹介します。
はじめに — なぜ CDC が必要なのか
近年、システム連携や分析基盤においてリアルタイム性が求められる場面が増えてきました。しかし、既存の RDB では日次バッチによるデータ同期が一般的であり、以下の課題がしばしば発生します。
- リアルタイム処理が困難:既存 DB に負荷がかかり、追加業務が性能面で NG
- データ鮮度不足:日次バッチ連携では顧客要求を満たせない
- 過負荷状態:OLTP/OLAP が同居し、既存システムの性能限界
- データサイロ化:複数 DB に分断され、分析用にデータを集約しづらい
そこで注目されているのが CDC (Change Data Capture) です。
CDC(Change Data Capture)とは
CDC(Change Data Capture)とは、データベースへの変更を観察し、その変更内容を他のシステムへレプリケーション可能な形式で取り出すためのプロセスです。例えば PostgreSQL で発生した更新内容(INSERT / UPDATE / DELETE など)を取得し、分析用途として Elasticsearch や別のデータベースへ投入するといった利用が可能です。
CDC 製品は、同期速度が比較的高速であることを特徴としており、数秒オーダー以下で他システムに反映できるものが一般的です。日次バッチによる連携とは異なり、データ鮮度を保ちながらシステム間連携を実現できます。
また、PostgreSQL 本体には、物理レプリケーションおよび論理レプリケーション機能が標準で備わっています。これらは送信元と送信先のいずれも PostgreSQL 同士であることが前提です。一方、CDC のアプローチでは、送信元が PostgreSQL であっても、送信先は多様な選択肢があります。
そのため、異種データベース間のリアルタイム同期や分析基盤へのデータ配信など、より柔軟なデータ活用が可能になります。
CDC 実現後のイメージ
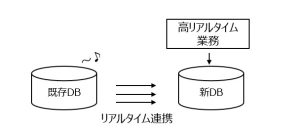
① リアルタイム連携による新業務の実現
既存システムの DB でデータ更新が発生すると、その変更が即座に新しい DB へ反映されます。そのため、新 DB 側では最新データを用いた高リアルタイムな業務を実行できます。
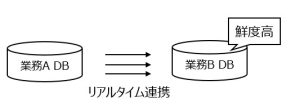
② バッチ処理の削減・負荷分散
日次の大量バッチ処理は、システム負荷の集中や業務運用の複雑化の原因になるケースがあります。CDC に置き換えることで、これらの課題を解消できます。
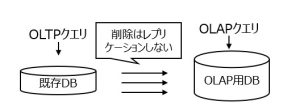
③ 既存 DB のオフロードと分析基盤の強化
CDCを用いて、参照系や分析系の処理を別 DB へ切り離す構成も可能です。
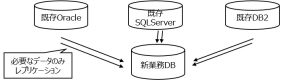
④ マルチデータストアの連携
CDC により、異なるDBから必要なデータだけ抽出し統合することができます。
CDC の実現方法
CDC には以下2つの方式があります。
① トランザクションログベース:データベースのトランザクションログ(WAL)に記録された変更内容をデコードし、論理的な変更情報として抽出して、ターゲット側のデータベースへ反映する方式です。
② Trigger ベース:データベースのテーブルにトリガーを設定し、変更を検知して別のログテーブルへ記録し、その内容を定期的にターゲット DB へ反映する方式です。
なお、本記事で紹介する Debezium はトランザクションログベース方式を採用しています。
Debezium について
Debezium は、データベースの変更データをリアルタイムに取得し、配信することができるオープンソースの CDC プラットフォームです。複数種類のデータベースに対応しており、バージョン 3.3 における Source Connector 対応一覧は以下の通りです。
- MySQL
- MariaDB
- MongoDB
- PostgreSQL
- Oracle
- SQL Server
- DB2
- Cassandra
- Vitess
- Spanner
- Informix
ライセンスは Apache License 2.0 で公開されており、主に Red Hat が中心となって開発を進めています。また、Debezium プロジェクトは Commonhaus Foundation に参加しており、広くコミュニティによって支えられています。
Debezium は単体で動作するのではなく、Apache Kafka と連携して CDC を実現する仕組みになっています。各データベースからの変更イベントは Debezium の Source Connector によって取得され、Kafka を経由して配信されます。その後、Sink Connector を介して Elasticsearch や JDBC、Data Warehouse など、さまざまなシステムへ転送可能です。
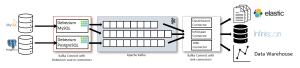
https://debezium.io/documentation/reference/stable/architecture.html
Kafka について
CDC で取得した変更データは、どのようにして外部のシステムへ届けられるのでしょうか?その中継地点となるのが Kafka(Apache Kafka)です。
Kafka は、以下の特徴を持つオープンソースの分散メッセージングシステムです。
- 送られてきたメッセージを蓄積し、別システムへ渡す仕組み
- 複数ノード構成による高いスケーラビリティ
- 送達保証(確実に相手に届ける仕組み)がある
Kafka の構成要素
Kafka の主要な構成要素は以下の通りです。
- Producer : メッセージの送信元(例:Debezium、アプリケーション等)
- Broker : Kafka クラスタのサーバ群。Topic を保持し、データを分散管理
- Topic : メッセージの入れ物。RDB 連携では「テーブル 1つ=Topic 1つ」が一般的
- Consumer : メッセージの取得側(分析基盤やアプリなど)
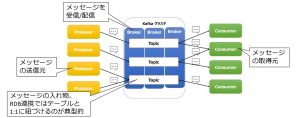
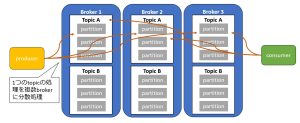
そして、Kafka ではメッセージを格納する単位である Topic をさらに複数のパーティションに分割して管理します。
こうすることで、
- 1つの Topic でも複数の Broker(Kafka サーバ)で分散処理できる
- 大量のメッセージが来てもスケールアウトで対応可能
- Consumer は複数パーティションを並列処理できるため、高速に処理できる
というメリットがあります。
Kafka Connect について
Kafka Connect は、Kafka と外部システムを容易に連携するためのデータ連携フレームワークです。
Kafka Connect では、接続対象に応じたコネクタプラグインを利用します。例えば、PostgreSQL から Kafka へ変更データを取り込む場合には PostgreSQL 用の Source Connector を利用します。逆に、Kafka に蓄積されたデータを Elasticsearch やデータウェアハウス、RDB などへ転送する場合には Sink Connector を使用します。
Debezium は、Kafka Connect で利用できるコネクタプラグインの集合です。PostgreSQL、MySQL、Oracle、MongoDB など、さまざまなデータベースの変更データ取得を実現する Source Connector を提供しています。
ポイントとして、Debezium は Kafka Connect 上で動作する Source Connector の 1つであり、Kafka 本体とは独立したコンポーネントです。
Debezium 利用時の PostgreSQL から Kafka へのデータの流れ
Debezium による PostgreSQLからのデータ取得
Debezium は、PostgreSQL のロジカルデコーディング 機能を利用して、データベース内で発生した変更内容(INSERT/UPDATE/DELETE など)を取得します。
ロジカルデコーディングは、WAL に記録された変更データを外部システムでも読める形式に変換して出力する仕組みです。PostgreSQL の WAL は元々クラッシュリカバリや物理レプリケーションのための内部形式で保存されていますが、ロジカルデコーディングを利用することで、論理的な変更イベントとして抽出できます。
WAL の変換形式は Output Plugin によって決まります。Debezium では、以下の 2 種類のプラグインが利用可能です。
| Plugin | 説明 |
|---|---|
| pgoutput | PostgreSQL 標準形式。論理レプリケーションに使用される |
| decoderbufs | Debezium 独自形式 |
本記事では、一般的な利用例として pgoutput を前提に説明していきます。
CDC アーキテクチャの全体像
ここでは、Debezium を利用して PostgreSQL の変更データを Kafka へ取り込み、さらに下流システムへ連携するまでの全体的なデータフローを説明します。
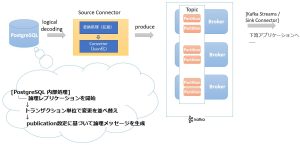
まず、PostgreSQL 内部で変更データがどのように処理されるかについて解説します。
PostgreSQL 内部の walsender プロセス が WAL を読み込み、変更内容をロジカルデコード対象として取り出します。
次に、読み取った WAL の内容をデコードしてトランザクション単位で管理します。PostgreSQL では、変更内容をただ順番に処理するわけではなく、内部の ReorderBuffer という仕組みを利用して、1つのトランザクション内の変更をまとめて保持します。
その後、デコードされた変更は pgoutput のコールバック関数群によって処理されます。
- begin_cb : トランザクション開始
- change_cb : 変更イベント(INSERT / UPDATE / DELETEなど)
- commit_cb : トランザクション終了
そして、COMMIT が発生すると pgoutput はトランザクション全体を 1つの論理イベントとしてまとめ、walsender を通して外部へ送信します。
Debezium Source Connector は、PostgreSQL から受け取った変更イベントを外部システムで扱いやすい形式に変換します。ここで変更イベントが JSON 形式のメッセージとして Kafka に送信されます。
Kafka は受け取ったメッセージを Topic に格納します。Topic は用途やスケーラビリティに応じて複数のパーティションに分割することができます。
最後に、Kafka 上のデータは、その後 Kafka Streams や Sink Connector によって下流システムへ転送されます。
INSERT / UPDATE / DELETE イベントの出力例
INSERT イベント(op=c)
INSERT INTO customers (id, first_name, last_name, email)VALUES (4, 'Debe', 'Test', 'd@example.com');
Key:
{"id": 4}
Value:
{
"before": null,
"after": {"id": 4, "first_name": "Debe", "last_name": "Test", "email": "d@example.com"},
"op": "c",
"source": {"db": "inventory", "schema": "public", "table": "customers", "lsn": 27013880, "txId": 1069},
"ts_ms": 1760601142773
}
UPDATE イベント(op=u)
UPDATE customers SET last_name = ‘Updated’ WHERE id = 4;
Key:
{"id": 4}
Value:
{
"before": {"id": 4, "first_name": "Debe", "last_name": "Test", "email": "d@example.com"},
"after": {"id": 4, "first_name": "Debe", "last_name": "Updated", "email": "d@example.com"},
"op": "u",
"source": {"db": "inventory", "schema": "public", "table": "customers", "lsn": 27013912, "txId": 1071},
"ts_ms": 1760601144801
}
DELETE イベント(op=d)
DELETE FROM customers WHERE id = 4;
Key:
{"id": 4}
Value:
{
"before": {"id": 4, "first_name": "Debe", "last_name": "Updated", "email": "d@example.com"},
"after": null,
"op": "d",
"source": {"db": "inventory", "schema": "public", "table": "customers", "lsn": 27013944, "txId": 1072},
"ts_ms": 1760601145902
}
初期同期スナップショット
Debezium の初期同期スナップショットとは、CDC を開始する際に、対象テーブルの既存データを整合性の取れた状態で一括取得する処理です。CDC 起動時の最初のステップとして実行され、変更履歴と現在のデータを正しく同期させるために利用されます。
仕組み
- CDC 対象のテーブルに対して全件取得の SELECT クエリを実行し、既存データを取得する
- このスナップショット SELECT と同時並行で行われる更新処理は WAL に記録されるため、
スナップショット取得が完了した後、WAL の内容を追いかけることでデータ整合性を維持する
スナップショット処理が正常に完了すると、以降は通常の CDC に移行します。
初期同期イベント(op=r)
{
"before": null,
"after": { "id": 1, "first_name": "Sally", "last_name": "Thomas", "email": "sally.thomas@example.com" },
"op": "r",
"source": {
"version": "3.2.3.Final",
"connector": "postgresql",
"name": "dbserver1",
"snapshot": "first",
"db": "inventory",
"schema": "public",
"table": "customers"
},
"ts_ms": 1759731208613
}
アーキテクチャなどから考える Debezium の注意点
ここでは、アーキテクチャを踏まえた Debezium の運用上のポイントを説明します。
PostgreSQL 論理デコードの制約と Debezium の関係
DDL は CDC 対象外
DDL(CREATE / ALTER TABLE など)は CDC の対象外です。つまり、テーブル構造の変更は Debezium では検知できません。スキーマ変更を監視したい場合は、別の仕組みを組み合わせる必要があります。
REPLICA IDENTITY について
PostgreSQL では、論理レプリケーションやロジカルデコードを行う際に REPLICA IDENTITY という設定が重要になります。これは、UPDATE や DELETE が発生した際にどの行が変更されたかを特定するための仕組みです。
この設定が DEFAULT のままで、かつ主キーが存在しないテーブルの場合、PostgreSQL は before値(旧値)を取得できず、行の特定もできません。そのため、該当テーブルを publication に含めている場合、UPDATE や DELETE を実行した時点でエラーとなります。
Debezium もこの PostgreSQL の制約に従って動作するため、主キーのないテーブルでは INSERT のみ取得可能で、UPDATE / DELETE は配信されないという制限があります。
対策としては、次の 2 つの方法があります。
1つ目は、主キーまたは一意キーを設定することです。これが最も自然であり、安全な方法です。
2つ目は、REPLICA IDENTITY FULL を指定する方法です。この設定により、UPDATE や DELETE の実行時に全列の before 値を出力できるようになります。ただし、WAL の出力量が増加するため、性能への影響に注意が必要です。
WAL デコードは対象のDBクラスタのWAL全てに実施される
Debezium の CDC 処理では、PostgreSQL の WAL を読み取り、変更内容をデコードします。このとき、publication で対象テーブルを絞り込んでいても、WAL の読取りとデコード処理は DB クラスタ全体に対して実行される点に注意が必要です。つまり、CDC 対象外のテーブルで大量に更新が発生しても、それらの WAL を含めてデコード処理が行われるため、CDC の対象データ量とは関係なく負荷が高くなる可能性があります。
また、CDC 接続数が増えるほど、各接続が独立して WAL を読み取るため、WAL デコードの負荷も増加します。そのため、CDC 接続は最小限に保つ、publication を適切に管理する、負荷監視を行うといった設計・運用が重要です。更新量が少なくてもワークロードによって負荷が高まるケースがあるため、本番データベースでの安定運用には継続的な監視とチューニングが不可欠です。
生成列の対応状況
PostgreSQL には生成列(generated column)と呼ばれる機能があり、他の列の値をもとに自動計算される列を定義できます。生成列には、計算結果をテーブルに保持する STORED 型 と、値を保存せず SELECT 時に都度計算して返す VIRTUAL 型 の 2 種類があります。なお、VIRTUAL 型は PostgreSQL 18 から導入された機能です。
しかし、CDC において生成列を扱う場合は注意が必要です。PostgreSQL 12〜17 では、STORED 型の生成列であっても論理デコードの対象外であり、Debezium では値を取得できません。そのため、生成列を含むテーブルを CDC 対象にする場合は PostgreSQL 18 以降の利用が前提となります。
PostgreSQL 18 では、publish_generated_columns オプションが追加され、STORED 型の生成列が論理デコード対象として出力されるようになりました。この変更により、Debezium でも自動計算された列の値を取得可能となります。
ただし注意すべき点として、VIRTUAL 型の生成列は値をディスクに保存しないため、論理デコードの対象外となり、Debezium では取得できません。つまり、Debezium で扱える生成列は STORED 型に限定されるため、スキーマ設計時に意識しておく必要があります。
Commit 単位でまとめて送信
Debezium を利用する場合、PostgreSQL 側ではトランザクションの COMMIT 時にイベントを送信します。そのため、たとえば 1 つのトランザクションで数十万件の更新や削除を行う場合、COMMIT 完了まで変更イベントが Kafka へ送られず、反映が遅延する可能性があります。
また、PostgreSQL 14 で導入された、実行中の大規模トランザクションをストリーム送信できる機能(トランザクション完了を待たずに途中の変更データを順次送信する仕組み)は、Debezium ではサポートされていません。
以下は、pg_stat_replication_slots の確認結果で、Debezium スロットでは stream_txns および stream_bytes が常に 0 になっており、ストリーム送信が行われていないことが確認できます。
SELECT slot_name, spill_txns, spill_bytes, stream_txns, stream_bytes, total_txns, total_bytes FROM pg_stat_replication_slots WHERE slot_name='debezium_slot'; slot_name | spill_txns | spill_bytes | stream_txns | stream_bytes | total_txns | total_bytes ----------------+------------+-------------+--------------+---------------+-------------+------------ debezium_slot | 1 | 135200000 | 0 | 0 | 91 | 274706394
Debezium × Kafka における「1トピック1パーティション」問題
Debezium では、1 テーブルにつき 1 トピックがデフォルト動作となります。
トピック名は通常、以下の形式で自動生成されます。
<serverName>.<schemaName>.<tableName>
また、このトピックに割り当てられる Kafka のパーティション数はデフォルトで 1 です。Kafka では 同じパーティション内でのみメッセージ順序が保証されるため、パーティション数を増やしてトピックを分割すると、同一行に対する更新順序が乱れる可能性があります。
この理由から、CDC の特性を考慮すると、Debezium を利用する際に Kafka トピックのパーティション数を増やしてスケールアウトする構成は基本的に推奨されません。
※ここでいう「パーティション」は Kafka の用語であり、PostgreSQL のパーティションテーブルとは無関係です。
文字コードが UTF-8 以外だと Debezium がエラー発生
Debezium は PostgreSQL に接続する際、JDBC 経由で UTF-8 のセッションを使用します。初回のスナップショット取得時の SELECT も同じ UTF-8 セッションで実行されます。そのため、データベース側の文字コードが UTF-8 以外に設定されている場合、スナップショット処理中に文字コード変換エラーが発生する可能性があります。
Caused by: org.postgresql.util.PSQLException: ERROR: invalid byte sequence for encoding "UTF8": 0x80
Debezium はこのエラーを検知すると、スナップショット処理を一旦中断して自動リトライに入りますが、文字コードの不一致が解消されない限り、処理は正常に再開されません。
そのため、使うときには、データベースもクライアントも UTF-8 で統一することが必要となります。これが最も安全で、Debezium が安定して動作する基本条件になります。
まとめ
本記事では、PostgreSQL のデータをリアルタイムに取得して外部へ配信するための技術、CDC(Change Data Capture) と Debezium について紹介しました。
- CDC によって、異種間データベース間のリアルタイムレプリケーションが可能になる
- Debezium はオープンソースの CDC 基盤であり、基本的に Apache Kafka と連携して動作する
- Debezium PostgreSQL Source Connector は PostgreSQL の論理デコードを利用して DB の変更を取得する
- CDC には仕様制約があるため、利用環境やワークロードに応じて事前検証が重要
Debezium を活用することで、既存 DB への影響を抑えつつ、リアルタイムなデータ活用基盤を実現できます。導入の際は、論理デコードの制約や文字コード、トランザクション特性などに注意しながら進めてください。