
この記事は SRA Advent Calendar 2024 の 12 月 25 日の記事を一部修正したものです。
Kafka Streams について、初心者向けに公式ドキュメントの Core Concepts から基礎的な概念などを解説していきます。
Kafka Streams とは
Kafka Streams は Apache Kafka クラスタ上でストリーム処理アプリケーションを実装するためのクライアント・ライブラリです。Java および Scala のライブラリとして提供されており、簡単にストリーム処理アプリケーションを構築することができます。
Kafka Streams によるストリーム処理の基本の流れとしては、Kafka の Topic にあるデータを入力とし、変換処理を行った後、別の Topic に結果を書き戻す形になります。
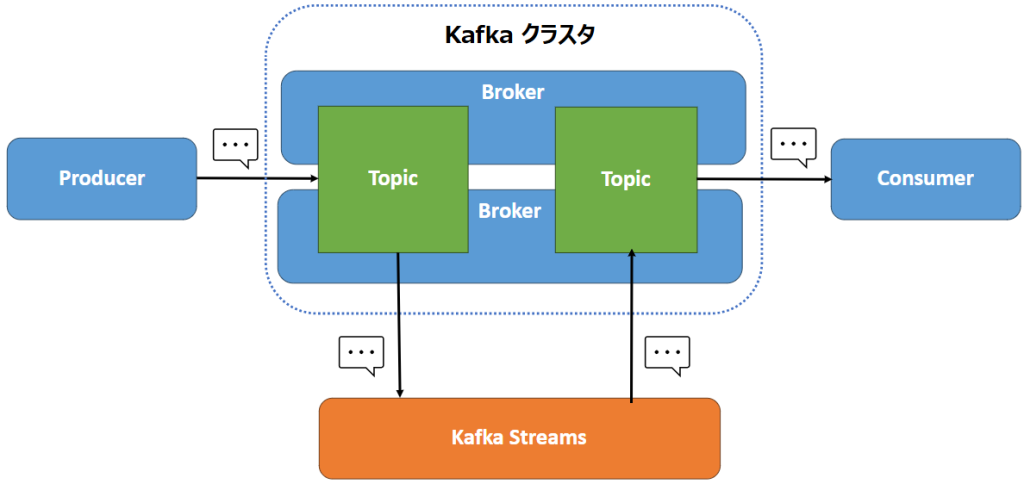
Kafka Streams の特徴
Kafka Streams には以下の特徴があります。
- 扱いやすさ
- 構築したアプリケーションは通常の Java アプリケーションとしてパッケージング、デプロイが可能
- ベアメタル、仮想環境、コンテナ、クラウドといった様々な環境にデプロイ可能
- 規模を問わず様々なユースケースに適用可能
- 高機能
- Kafka クラスタの持つ拡張性、弾力性、分散性、耐障害性をアプリケーション側でも利用可能
- Exactly once (データの抜け漏れや重複なく必ず 1 回だけ) の処理セマンティクスをサポート
- 複数レコード間の結合や集約、ウィンドウ処理が可能
ストリーム処理トポロジ
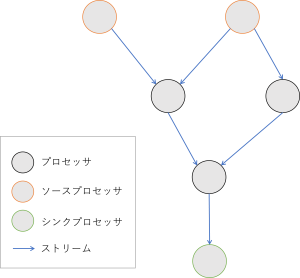
ストリーム処理トポロジとは、ストリーム処理アプリケーションで実行されるデータ処理の流れを定義するものです。トポロジはデータ変換の処理単位をプロセッサ (ノード)、データの流れをストリーム (エッジ) としたグラフで表現されます。
トポロジの末端に位置するプロセッサには特別な名前が付けられています。
- ソースプロセッサ:トポロジの入力であり、Topic からレコードを読み込む
- シンクプロセッサ:トポロジの出力であり、Topic へ処理結果を書き込む
Kafka Streams でストリーム処理アプリケーションを構築する場合は、ライブラリで提供される Processor API か Kafka Streams DSL を用いて、トポロジを定義します。
- Kafka Streams DSL
- Processor API を基盤に構築された宣言型、関数型の DSL
- ステートレス変換 (map、filter) や結合 (join) や集約 (aggregate、count、reduce)、ウィンドウ処理といったステートフル変換を利用可能
- 複雑な変換処理を簡単に記述できるので初心者におすすめ
- Processor API
- 命令型の低レベル API
- ユーザ独自のプロセッサの定義やステートストアとの直接のやりとりが可能
- 柔軟性が高いがより多くのコーディングが必要
ストリームにおける時刻の定義
ストリーム処理においては時刻をモデル化することは重要な概念の 1 つです。ウィンドウなどの操作は時刻に基づいて定義、処理されるからです。
Kafka Streams では以下の時刻の定義が使用されます。
- イベント時刻:イベントまたはデータレコードが発生した時刻
- 処理時刻:イベントまたはデータレコードがストリーム処理アプリケーションによって処理された時刻
- インジェスト時刻:イベントまたはデータレコードが Kafka Broker によって Topic Partition に格納された時刻
ストリームとテーブルの二重性
ストリーム処理における重要な概念としてストリームとテーブルの二重性というものがあります。この二重性とは、本質的にストリームはテーブルとして、テーブルはストリームとして見なせるということです。
- テーブルとしてのストリーム:
ストリームはテーブルの変更ログと見なすことができます。ストリーム内の各データレコードには、テーブルのステートの変更内容が記載されているため、これを最初から最後まで追うことでテーブルを再構築することができます。 - ストリームとしてのテーブル:
テーブルは、ストリーム内の各キーに対応するある時点での最新の値のスナップショットと見なすことができます。したがって、異なる時点のテーブル内容を比較することでその変更ログをそのままストリームに変換できます。
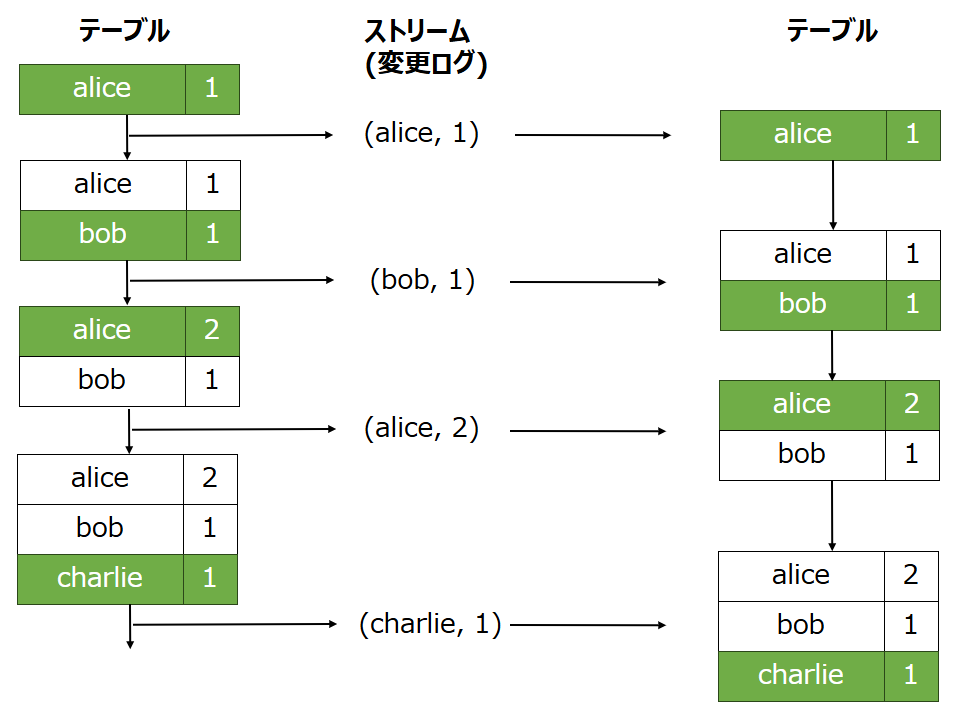
Kafka Streams ではこの二重性を KStreams および KTable としてモデル化しています。
ステートフル操作
Kafka Streams ではステートレス操作に加えて、ステートフル操作にも対応しています。ステートフル操作には状態の保存が必要なため、Kafka Streams ではステートストアが提供されます。ステートフル操作の例としては集約、結合、ウィンドウ化があります。
集約
集約操作では 1 つのストリームもしくはテーブルを入力として受け取り、複数のレコードを 1 つに結合してテーブルとして出力します。count や sum といった操作が集約にあたります。
Kafka Streams DSL では入力ストリームは KStream か KTable、出力ストリームは KTable になります。
参考:Kafka Streams/Developer Guide/Streams DSL/aggregationg
結合
結合操作では、データレコードのキーに基づいて 2 つの入力ストリームまたはテーブルをマージして、新しいストリームまたはテーブルを生成します。
Kafka Streams では KStream 同士、KTable 同士、KStream と KTable の結合などが可能ですが、それぞれで可能な結合の種類は異なります。
参考:Kafka Streams/Developer Guide/Streams DSL/Joining
ウィンドウ化
ウィンドウ化では、集約や結合などのステートフル操作において同じキーを持つレコードをグループ化し、ウィンドウと呼ばれる単位に分けて処理を行います。
参考:Kafka Streams/Developer Guide/Streams DSL/Windowing
ステートストア
ステートストアはステートフル操作を行う際のデータの保存やクエリに利用されます。ステートストアは Kafka Streams の各タスクに組み込まれています。
またローカルのステートストアの変更ログは Kafka の専用の Topic に保存されるため、障害時の自動復旧にも対応しています。
参考:Kafka Streams/Architecture/Fault Tolerance
アプリケーションの例
最後に、公式ドキュメントにあるアプリケーションの例を使って Kafka Streams DSL でのアプリケーションの書き方や処理について説明します。
LineSplit
LineSplit は入力文字列をスペースをデリミタとして、単語ごとに区切って出力するアプリケーションです。
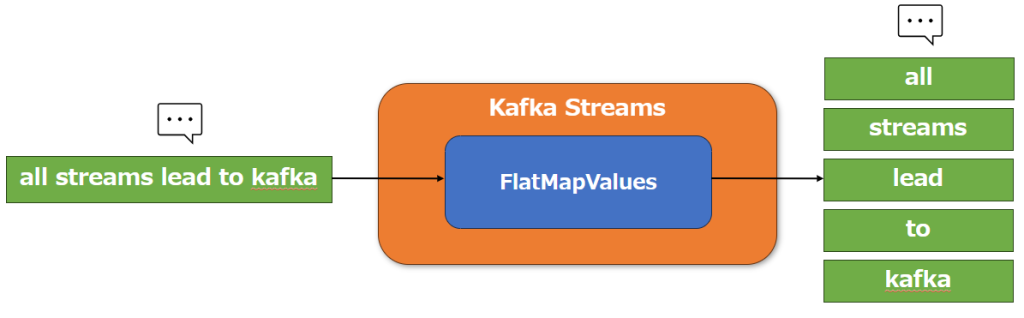
public class LineSplit {
public static void main(String[] args) throws Exception {
// アプリケーションの設定
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-linesplit");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// トポロジを定義するためのビルダ
final StreamsBuilder builder = new StreamsBuilder();
// 処理内容を DSL で記述
KStream source = builder.stream("streams-plaintext-input"); // 入力用 Topic を指定
source.flatMapValues(value -> Arrays.asList(value.split("\\W+"))) // 入力をスペースで区切って分割
.to("streams-linesplit-output"); // 出力用 Topic に書き込む
// ビルダからトポロジに変換し、実行
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
}
}
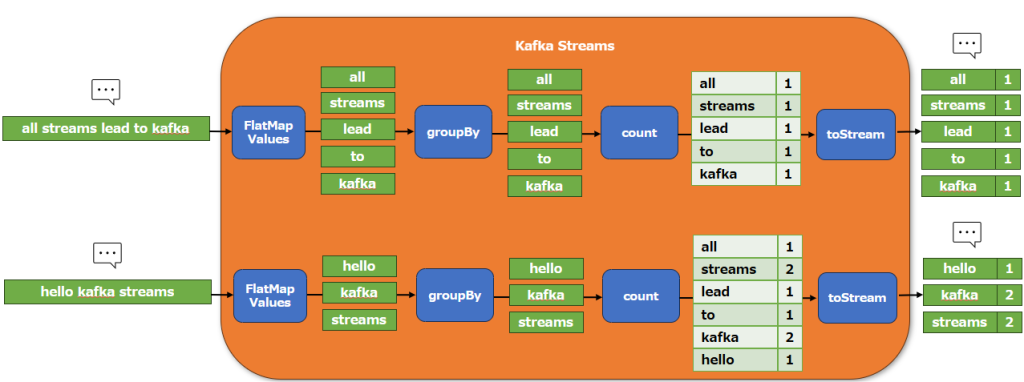
WordCount
WordCount は入力文字列の単語ごとに区切ってその出現数を出力するアプリケーションです。この処理は過去の入力文字列のカウント結果を保存しておく必要があるので、ステートストアを利用したステートフルな処理になります。
public class WordCount {
public static void main(String[] args) throws Exception {
// アプリケーションの設定
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "streams-wordcount");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
// トポロジを定義するためのビルダ
final StreamsBuilder builder = new StreamsBuilder();
// 処理内容を DSL で記述
KStream source = builder.stream("streams-plaintext-input"); // 入力用 Topic を指定
source.flatMapValues(value -> Arrays.asList(value.split("\\W+"))) // 入力をスペースで区切って分割
.groupBy((key, value) -> value) // 単語ごとにグループ化
.count(Materialized.>as("counts-store")) // 単語をカウントしてステートストアにテーブルとして保存
.toStream() // テーブルからストリームに変換
.to("streams-wordcount-output", Produced.with(Serdes.String(), Serdes.Long())); // 出力用 Topic に書き込む
// ビルダからトポロジに変換し、実行
final Topology topology = builder.build();
final KafkaStreams streams = new KafkaStreams(topology, props);
streams.start();
}
}
おわりに
この記事では Kafka Streams の基本的な概念について説明しました。
Kafka Streams は難しく見えるかもしれませんが、実際に使ってみると簡単にストリーム処理アプリケーションを実装することができます。みなさんも是非機会があれば Kafka Streams を使ってみてください。