
2025/5/13〜16 にかけて、カナダのモントリオールで開催された PGConf.dev 2025 に参加しましたので報告いたします。
はじめに
PGConf.dev の正式名称は PostgreSQL Development Conference で、PostgreSQL のユーザや開発者、コミュニティ関係者が集まる、PostgreSQL の開発とコミュニティの発展に焦点を当てたイベントです。 今回、株式会社SRA OSSはシルバースポンサーとして、このカンファレンスを支援しました。
今回の会場は、モントリオールのダウンタウン中心部に位置するPlaza Centre-Ville。全4日間の日程のうち、初日には 次年度のPostgreSQL 開発の優先度などを対面で議論する Developer Meeting(招待制)や、拡張モジュールについての議論をアンカンファレンス形式で行う Extension Ecosystem Summit、コミッターからパッチについてのアドバイスを受けられるAdvanced Patch Feedback Session(招待制)、コミュニティ運営に関するグループ・ディスカッションを行うPostgres Community Summitなどが行われました。
2日目の朝にはオープニングセッションと基調講演があり、その後2日間にわたり、3トラック並行でさまざまな講演が行われました。最終日はアンカンファレンスが開催され、その後クロージングセッションで締めくくられました。
本レポートでは、本カンファレンスのいくつかの講演をピックアップして紹介します。

基調講演
今回の基調講演はDavid DeWitt 博士による「From RAP to Snowflake – A Look at 50 Years of SQL DB Scalability 」でした。
1980年代中頃から1990年代初頭にかけて、ウィスコンシン大学の教授だった時代に博士が主導した並列データベースプロジェクト「Gamma」は、シェアード・ナッシング・アーキテクチャ(shared nothing architecture:複数の各ノードがCPU・メモリ・ストレージを完全に独立して持ち、互いに共有せずに性能をスケールさせる方式)の概念を初期に実装・検証したものとして、Spark、Snowflake、Redshiftといった今日の大規模分散データベースシステムの基礎となっています。
この講演は博士の50年にわたるキャリアを通して見たデータベースのスケーラビリティの発展の歴史を、RAP(Rotating Associative Processor) という初期のデータベースマシンから、安価なハードウェアの登場による独自データベースのホスティングの普及、そしてクラウドの時代へと続く流れで紹介されました。
その中では、分散データベースにおけるハッシュ結合の重要性や、ストレージとコンピュートを分離する現在主流の構成において、Snowflakeがいかに革新的であったかなどが語られていました。

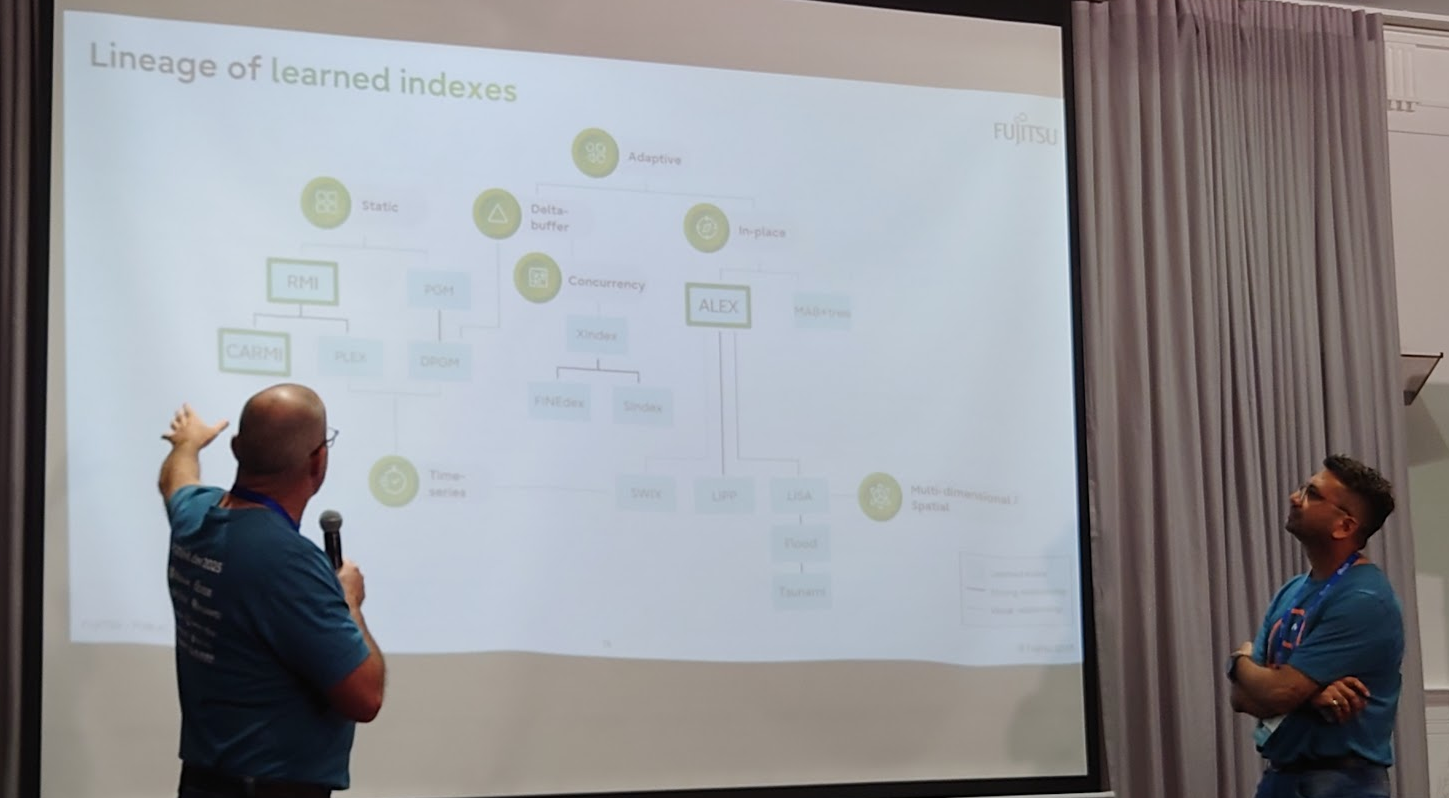
Learned Index の実装に向けた試み
Gray W Evans氏 (Fujitsu Australia) とNishchay Kothari 氏(Fujitsu Asia Pte Ltd) による講演「Exploring the benefits of learned indexes in PostgreSQL: Theory and Implementation」では、機械学習を活用したインデックスである Learned Index を PostgreSQL に実装に関する試みについて発表が行われました。
Learned Index については以前のイベントレポートでも紹介しましたが、簡単に説明すると、インデックス内部のキー探索に機械学習モデルを用いることで、高速な検索およびインデックスサイズの削減を目指す技術です。
今回の発表では、Learned IndexのPostgreSQLへの実装に向けた具体的な検討結果が紹介されました。Learned Indexの構造にもいくつか種類がありますが、今回の発表では、データ分布の変化に強く更新処理に対応できるALEX (Adaptive Learned Index) という構造を用いることが検討されていました。
しかしながら、インデックス全体をメモリ上に保持することを前提とするALEXと、インデックスページをディスクに永続化するPostgreSQLのアーキテクチャの間には非互換性があり、通常のワークロードにおいてはLearned Indexによる性能改善はあまり期待できないことがわかってきました。
ただし、クエリ実行中の途中経過に対する一時的なインデックスなど、ALEXインデックスが有用となり得るユースケースについての検討も進められているようです。
今後は、今までにわかってきたことを論文にまとめるとともに、ALEXインデックスが有用なケースに向けて拡張モジュールとして開発を進めるほか、静的なデータ分布を得意とする別のLearned Index構造についても、PostgreSQLにおけるユースケースを検討を行っていく予定とのことでした。
トランザクションマネージャを拡張可能に
近年、様々な分散データベースが登場しており、そこに伴い、グローバルトランザクションマネージャ(GTM)やクロックベースのアルゴリズムなど、多様な分散トランザクション手法が利用されています。 Yuya Watari 氏 (NTT) の講演「Revisiting XTM: A Practical Case Study Highlighting Its Needs」では、PostgreSQLにおいてそうした多様なトランザクション処理をサポート可能にする 拡張トランザクションマネージャ(eXtensible Transaction Manager, XTM)の有用性について議論が行われました。
XTMは2015年に開発コミュニティに提案されたアイデアですが、結局PostgreSQLには取り入れられていません。本発表では、外部データラッパ(FDW)とパーティショニングテーブルを組み合わせたシャーディング構成におけるトランザクション処理を例に、XTM の有用性が再評価されました。
postgres_fdw を使うと、別ノードのPostgreSQLのテーブルに格納されているデータを、自分のノードのテーブルのように参照・更新することができます。しかし、PostgreSQL標準のpostgres_fdw では分散トランザクションに対応しておらず、複数の外部サーバが参加する二相コミットを利用することができません。そこで、この発表ではpostgres_fdw を改造した postgres_fdw_plusを使用しています。
二相コミットにはコミットの「準備」と「確定」の2段階の過程があります。通常は、全ての処理が完了してコミットが確定した後に、クライアントへトランザクション完了の応答を返します。しかしこの発表では、性能を改善するために、「全ての外部サーバでコミットの準備ができた」段階でクライアントに応答を返すという最適化を採用しています。
ただし、この最適化はトランザクションの一貫性に影響を与える可能性があります。たとえば、FDW 経由のデータ更新とコミット準備が外部サーバで実行され、クライアントがトランザクション完了の応答を受け取った直後に、別のトランザクションを開始して外部サーバのデータを直接参照した場合、最初のトランザクションがまだ「コミット準備」状態にあるため、更新したはずのデータが見えないという現象が発生します。
このような状況を解決できるのがXTMです。トランザクション開始時の処理をカスタマイズし、「準備状態のコミットが確定するまで」外部サーバでのトランザクションの開始を待機させることで、更新済みのデータを正しく参照できるようになります。
発表では性能評価も行われ、XTM を利用したトランザクション処理をカスタマイズした場合でも、性能への影響はほとんどなかったことが示されました。一方で、トランザクション隔離性に影響があることが言及されており、ユーザがトランザクションマネージャの制限や前提を十分に理解していることの重要さも示唆されました。
最後に、様々な分散データベースが登場している中で、多様なトランザクション要望に対応するためにXTMの重要性は高まりつつありますが、「本当に必要な機能は何か」を知るには、実際に様々なトランザクション手法を実装してみる必要があるだろうという主張で発表は締めくくられました。

VACUUM の最新情報と今後
更新を繰り返されるテーブルから不要なタプルを回収し、古いトランザクションIDを持つタプルに「凍結」処理することでトランザクションIDの周回を防ぐ ― VACUUMは、PostgreSQLの状態を健全に保つために大切な役割を担っています。Masahiko Sawada氏 (AWS) の講演「The Present and Future of VACUUM in PostgreSQL」では、そんなVACUUMの最新の改善と、今後起こりうる改善が紹介されました。
講演の前半では、PostgreSQL 17 で行われたVACUUMのメモリ効率改善など、最近の改善を振り返りつつ、PostgreSQL 18 での新たな改善点として eager scanning が紹介されました。
通常のVACUUMでは、不要領域がないテーブルページについては処理をスキップして、そのため凍結処理も行われません。その結果、凍結が必要なタプルが徐々に蓄積し、最終的にトランザクションIDの周回を回避するため、大量のタプル凍結処理を行うaggressive モードのVACUUMで負荷が高まる可能性があります。
これに対処するための仕組みがeager scanning です。これは通常のVACUUMの最中に、たとえ不要領域が存在しないページでもスキップせずに、凍結処理のためのスキャンを実行するというものです。ただし、凍結できるタプルが少なく、ページ全体の凍結の失敗が一定以上続いた場合には、eager scan は中止されます。この失敗の割合は、新たに導入されたパラメータ vacuum_max_eager_freeze_failure_rate によって調整可能です。
後半には、PostgreSQL 19 以降に登場する可能性のある、現在開発中のVACUUMの改善がいくつか紹介されました。その一つが、Sawada氏が提案しているテーブルデータの並列VACUUMです。現在のVACUUMではインデックスは複数のワーカプロセスで並列処理可能ですが、テーブル本体は並列処理できません。それを改善しようという提案です。
その他にも、テーブルサイズを切り詰めるVACUUM FULL / CLUSTER の後継として、 CONCURRENT オプションをサポートするREPACK コマンドの提案など、今後のVACUUM改善に向けた興味深い取り組みが紹介されていました。

共有バッファサイズの動的変更
PostgreSQLの共有バッファのサイズは shared_buffers パラメータで決定されますが、現在この値を変更するためにはデータベースの再起動が必要です。このため、ワークロードに応じた動的なスケーリングや、メモリの最適利用が難しく、自動チューニングツールの活用も制限が生じるという課題があります。
Ashutosh Bapat 氏 (EnterpriseDB) の講演「Changing shared_buffers on the fly」は、この問題に取り組むもので、PostgreSQLを再起動せずにshared_buffers を動的に変更可能にする提案について議論されました。
共有バッファの管理に複数のメモリ構造が関係していますが、従来はそれらの領域を共有メモリ上に一括して獲得していたため、共有バッファのサイズが変更時に各構造のメモリアドレスが変わってしまうという問題がありました。提案されている方法では、各構造毎に独立した共有メモリセグメントを使用し、さらにメモリアドレス空間を余分に確保しておくことでこの問題を解決しています。
また発表の中ではメモリサイズ削減時の振る舞いや、サイズ変更時のバックエンドプロセスとの同期、サイズ変更の契機となるイベント(設定のリロード時、SQL関数やDDLコマンド)などについても議論されていました。

動的に切り替わる実行計画
Alena Rybakina 氏 (Postgres Professional)による講演「Switching between query plans in real time (Switch Join)」では、クエリ実行中に現在の実行計画が期待通りに動作しない場合に、別の実行計画へ自動で切り替える機能である Switch Join が紹介されました。
具体的には、2つのテーブルを結合するクエリにおいて、当初はネステッドループ結合で処理を行うものの、推定行数の誤差が一定以上大きい場合にハッシュ結合に切り替える、といった機能を提供します。
Switch Join はPostgreSQLの拡張モジュールとして、カスタムスキャンとフックを用いて実装されています。非常に興味深い機能ですが、ベンチマーク結果では、一部クエリでは性能向上が見られる一方で、オーバヘッドにより別のクエリでは性能が低下する場合もあり、使用するには注意が必要そうです。
なお、本機能はオープンソースではなく、 PostgresPro Standard の一部として提供される予定とのことでした。
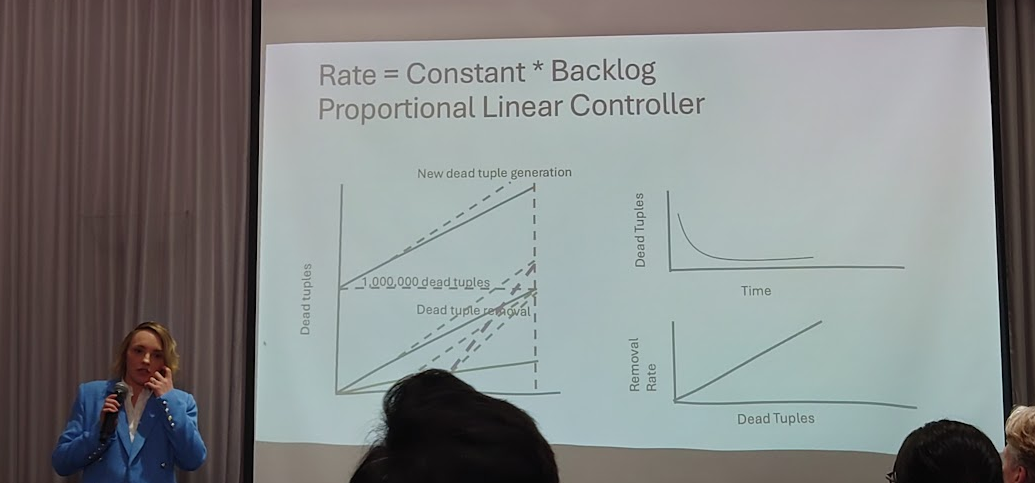
適応的なVACUUMの制御
Melanie Plageman 氏 (Microsoft) による講演「Fraught Feedback: Trying and Failing to Implement Adaptive Behavior in Postgres」では、VACUUMの振る舞いを適応的に制御するという実験的な試みについて紹介されました。
ひとつの試みは、VACUUMの負荷を調整するパラメータvacuum_cost_delayの値を、タプル回収の進行具合およびデッドタプルの発生速度を考慮して自動調整するというものです。デッドタプルの発生に対して回収が追いつかなくなった場合はこのパラメータ値を小さくしてVACUUM処理の割合を増やし、逆の場合にはパラメータ値を大きくしてVACUUMを小休止の割合を増やし、負荷を減らすというアイデアです。しかし、実際には処理が安定せず、あまり良い結果は得られなかったようです。
もうひとつの試みは、しばらく変更されないであろうテーブルページを統計的に予測し、そういったページを早めに凍結処理するというものです。これにより、小規模なVACUUMが多く発生した一方、全体のVACUUMにかける時間の総量は減少したとのことでした。
アンカンファレンス
最終日に開催されたアンカンファレンスは、講演者や話す内容があらかじめ決まっている通常のセッションと異なり、参加者がその当日にその場で話題を提案し、議論する形式のイベントです。議論したいテーマがある参加者は、大きなポストイットにそのテーマを書き、順番に口頭で簡単に紹介していきます。最終的には、会場の参加者による多数決で12のテーマが選ばれ、3つのトラックに振り分けられ議論されました。
今回は選ばれたテーマには、PostgreSQLの開発をスケールする、自動VACUUMのパラレル化、PostgreSQLのマルチスレッド化、スタンバイのコミット順序とCSNスナップショット、pg_stat_statementの未来、プランナの意思決定を明確にする、などがありました。

「PostgreSQL のマルチスレッド化」は、前回の pgconf.dev 2024 に引き続き注目を集めているトピックです。今回もThomas Munro 氏 (Microsoft) による関連講演「Investigating Multithreaded PostgreSQL」があり、このテーマへの関心の高さがうかがえました。
また、「スタンバイのコミット順序とCSNスナップショット」では、プライマリとスタンバイの間でトランザクションの「可視」タイミングが異なることに起因する一貫性の問題が議論されました。スタンバイにおける可視化のタイミングはWALの書き込み順で決まりますが、それはプライマリにおける可視化タイミングと同じとは限りません。現在 PostgreSQL開発コミュニティに提案されているCSN (Commit Sequence Number) スナップショットは、この問題を解決する方法としても期待されているようです。
さらに「プランナの意思決定を明確にする」では、PostgreSQLが実行計画を作成する過程で、どのようなプラン、スキャン、インデックスが除外されたか、あるいや優先されたかを知るために有用な情報についての議論がなされていました。
ポスターセッション
今回初の試みとして、ポスターセッションが開催されました。イベント開催約1ヶ月前に、自分たちが提案するパッチやプロジェクトを紹介するポスターの作成が呼びかけられました。作成されたポスターはA2サイズで印刷され、会場内の様々な場所の壁に展示されました。
筆者もこの企画に参加し、ポスターを作成し展示させていただきました。
これらのポスターはオンラインでも閲覧可能となっています。

おわりに
今回で2回目の開催となったPGConf.dev 。昨年参加したときも感じたことですが、このカンファレンスは改めて「PostgreSQLの未来を向いているイベント」であるという印象を強く受けました。

開発コミュニティで現在議論されている提案に関する講演はもちろんのこと、実験的な取り組みを共有する発表の数々が刺激的でした。中でも、多様なワークロードや状況変化に対応するための拡張性や適応性を高めるための提案は、私自身の関心とも重なり、特に興味深く感じました。また、コミュニティそのものの改善や進化を目的とする講演もあり、カンファレンス全体を通して、「これからのPostgreSQLを自分たちで作り上げていく」、「その場に参加していく」という、コミュニティの原動力のようなものを感じることができました。
来年の PGConf.dev 2026はカナダのバンクーバでの開催が予定されています。今回得られた知見と刺激を今後のコミュニティへの貢献に活かしながら、来年もまたぜひ参加できればと思います。