
2016 年 5 月 17 日 ~ 21 日に、カナダの首都オタワにて「PGCon 2016」が開催されました。
SRA OSS, Inc. 日本支社はシルバースポンサーとしてカンファレンスの支援をさせていただくとともに、弊社石井がプログラム委員の一人としてプログラム選考に協力しました。
このレポートでは、メインの講演とアンカンファレンスの中からいくつかのトピックを紹介いたします。
はじめに
毎年恒例の PGCon 2016 が、今年もカナダのオタワ大学にて開催されました。
PGCon は年に一度開催される世界最大の PostgreSQL カンファレンスで、毎年数多くの PostgreSQL の開発者とユーザが世界中から集まります。
特に今年は PostgreSQL 20 周年にあたり、かつ PGCon の開催は今回で第 10 回目になるという記念すべき回となりました。
今年も SRA OSS はシルバースポンサーとして、このカンファレンスの支援をさせていただきました。
また、弊社の石井はプログラム委員の一人として、プログラム選考に協力しております。
今回の PGCon は 5月17日(火)から21日(土)の5日間の日程で行われました。
1日目と2日目にはチュートリアルセッション、3日目と4日目がメインの講演が行われました。
また、今回は2日目と5日目にアンカンファレンスが開催されました。
2日目にはクラスタリングやレプリケーションなど、PostgreSQL 開発者同士の議論が繰り広げられる “Developer Unconference” が、5日目には PostgreSQL の開発からユーザサイドの話題まで、幅広く議論される “User Unconference” が行われました。
なお、PostgreSQL 開発コミュニティの運営など、技術的内容以外の議論は、例年通り非公開(正確には招待制)の Developer Meeting にて行われました。
本レポートではメインの講演とアンカンファレンスの中からいくつかのトピックを紹介いたします。
まずはメインの講演から紹介いたします。
基調講演: PostgreSQL の拡張性

今回の基調講演は「PostgreSQL Extensibility」という題目で Citus Data(PostgreSQL ベースの分散データベースの開発会社)の Ozgun Erdogan により行われました。
タイトルの通り PostgreSQL の拡張性についての講演です。
PostgreSQL には、ユーザ独自の機能を追加できる仕組みが豊富に備わっており、その高い拡張性は PostgreSQL の大きな特徴の1つと言えるでしょう。
近年は、ビッグデータの流行などもあり、巨大で多様なデータを扱うため、Hadoop や NoSQL など、新しいデータベースが数多く登場しました。
これらのデータベースは、既存のプロジェクトから派生したり、あるいは全く新しいプロジェクトとして一から作られたりしています。
しかしもう1つの新しい可能性として「PostgreSQL を拡張して新しい機能を実現する」という選択肢が我々にはあるわけです。
具体的な例としては、OLAP 系処理を高速化するため PostgreSQL の処理を拡張した Vitesse-X や、PostgreSQL カラム指向ストアを実現する cstore_fdw、 PostgreSQL を分散データベースに拡張した Citus などが挙げられていました。
一方で、拡張性を革命的なものにするためには、開発者とユーザがもっとコミュニケーションし、これらの拡張をより「ユーザのために」使いやすくしていく必要がある、という課題も述べられました。
基調講演の最後は、拡張は PostgreSQL に特有なものであるとして、「PostgreSQL はまだ世界最高のデータベースではないが、そうなることができる」という PostgreSQL の可能性の広さを象徴するメッセージで締めくくられました。
パラレルクエリ
次期メジャーバージョンの PostgreSQL 9.6 は先月に beta1 がリリースされたところですが、今回の目玉の新機能といえば、やはりパラレルクエリではないでしょうか。
PGCon 2016 では、この機能の主要開発者である EnterpriseDB(PostgreSQL ベースのエンタープライズ向けデータベースの開発会社:以下 EDB) の Robert Haas からパラレルクエリの発表(Parallel Query Has Arrived!)がありました。
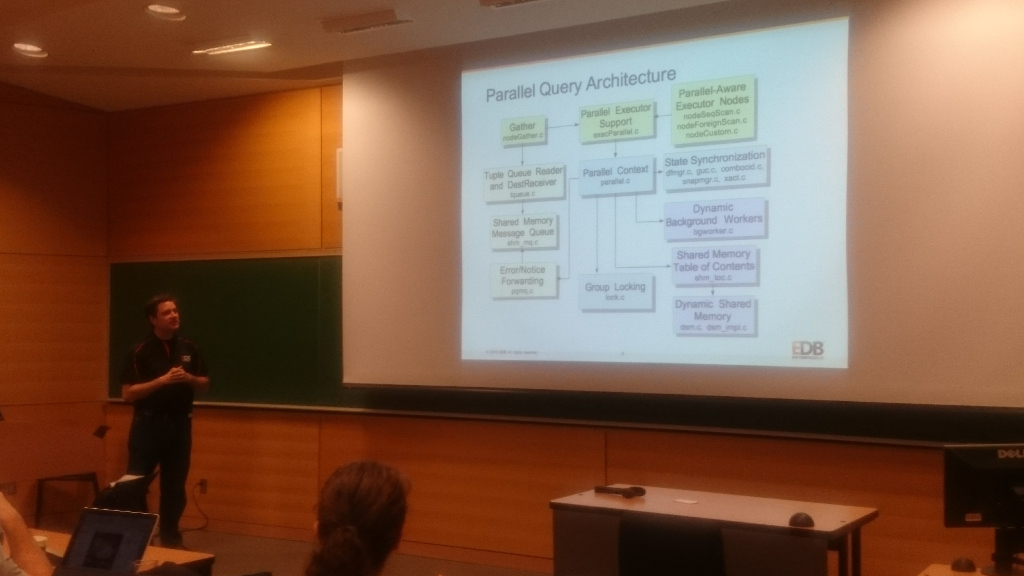
パラレルクエリはその名の通り、クエリの処理を複数プロセスで並行に実行する機能です。
従来の PostgreSQL では1つのクエリは単体のプロセスで処理していましたが、CPU が複数ある環境では、大幅な検索性能の向上が見込まれます。
実はパラレルクエリの実現に向けた機能は、数年かけて少しずつ PostgreSQL に取り込まれてきました。
例えば、背後で仕事をするプロセスを動的に起動させる「動的バックグラウンドワーカ」や、プロセス間で共有するメモリ領域を動的に割り当てる「動的共有メモリ」は 9.4 の時点に取り込まれたものです。
並列化の基本的なインフラである「パラレルコンテキスト」は 9.5 で取り込まれていました。
そして 9.6 で並列可能性の判断、実際の並列処理の実行、そしてその結果を回収する機能などが取り込まれ、やっとパラレルクエリが実現可能となりました。
現状で並列処理が可能なのは、シーケンシャルスキャン(順次検索)と、一部の JOIN 結合、そして一部の集約計算です。
将来的には、インデックススキャンなど他の検索や、CREATE INDEX、VACUUM といったユーティリティコマンドの並列化も考えられています。
並列化の効果は、TCP-H ベンチマークで検証されました。
並列の多重度を 4 に設定してテストした結果、22 個のクエリのうち 17 個のクエリで並列処理が実行されました。
そのうち 3 個のクエリでは約 4 倍、11 個のクエリでは約 2 倍の性能が確認されました。
多重度の割には性能改善が小さかったクエリもありましたが、結果の解析からは、更に理想的な並列処理のためには Merge JOIN、ハッシュテーブル作成、ビットマップインデックス処理、サブクエリの並列化が必要となってくることもわかってきました。
PostgreSQL の大きな前進となったパラレルクエリですが、今回取り込まれた機能はほんの開始点に過ぎません。
まだまだ改善の余地があり、そして、これからますます進化していくことでしょう。
性能改善
同じく EDB の Amit Kapila からは、PostgreSQL 9.6 の性能の改善について発表(Faster PostgreSQL: Improved Writes)がありました。

PostgreSQL 9.6 では主にロック関係の処理の改良により、参照/更新の両方においてスケーラビリティ性能が改善しています。
例えば、可能限りロックを取得しないようにしたり、複数のプロセスが取得していたロックを1つのグループにまとめることで、ロックの回数を減らしたりといった工夫がされています。
9.5 と 9.6 の参照性能(TPS)を同時接続クライアント数を変化させながら比較すると、 同時接続数の増加に従って TPS が向上する傾向は両者において確認されました。
しかし、同時接続数が大きい領域では 9.5 の TPS は大きく低下するの対し、9.6 では(わずかに低下はするものの)高い値を保持していました。
9.5 と 9.6 の間には、最大で 2.4〜2.5 倍の性能差が見られ、9.6 では大幅に読み込みスケーラビリティが改善されていることが確認されました。
今度は、参照と更新が混在したクエリで性能を検証したところ、同時接続数がマシンのコア数(64)を超える辺りまでは、9.5 と 9.6 の性能差はあまりありませんでしたが、コア数を超えた領域では 9.5 の TPS は大きく低下した一方、9.6 の TPS は上昇し続けました。
同時接続数が 128 の場合では、9.6 は 9.5 に対して 2 倍近い性能向上が見られました。
更新を含む状況においても 9.6 ではスケーラビリティが大きく改善されていることがわかります。
また、この講演では PostgreSQL 9.6 で取り込まれた、他の性能改善についても紹介されました。
その1つが、「snapshot too old」機能の導入です。
この機能では、指定された時間よりも古いトランザクションから参照されているデータの VACUUM を許すことで、長時間トランザクションが原因で発生するテーブルの肥大化を防ぐことができます。
この snapshot too old の機能については、EDB の Kevin Grittner の講演(ERROR: snapshot too old)で詳しく取り上げられていました。
その他にも、PostgreSQL 9.6 には、VACUUM、外部ソート、インデックスオンリースキャン、2相コミット、集約計算に関するものなど、多くの性能改善が取り込まれています。
全文検索
Postgres Professional(ロシアの新興 PostgreSQL 会社:以下 PostgresPro) の Oleg Bartunov と Teodor Sigaev からは全文検索についての発表(FTS is dead? Long live FTS!)がありました。
全文検索はクエリに指定された単語を含む文書を効率的に検索する機能ですが、PostgreSQL 9.6 では全文検索の新しい機能として「フレーズ検索」が追加されました。
これにより、クエリ内の単語を「指定した順序」で含むテキストの検索が可能になります。

また、この講演では検索された文書のランク順序付けを効率化する RUM インデックスが紹介されました。
これは 9.6 の新機能ではありませんが、拡張モジュールが GitHub 上で公開されています。
なお、RUM インデックスは PostgreSQL 9.6 新機能である”CREATE ACCESS METHOD” を用いて実現されてます。
この PostgreSQL に新しいアクセスメソッドを作成する機能については、同じく PostgresPro の Alexander Korotkov の講演(PostgreSQL extendability: Origins and new horizons)の中で取り上げられました。
ちなみに、RUM いう名前はお酒の名前に由来します。
PostgreSQL にはもともと GIN(Generalized Inverted Index) インデックスがありましたが、これはお酒のジンと同じ綴りなのを受けて、Oleg らは過去に VODKA(ウォッカ)という名前の新しいインデックスを提案しました。
この流れで今回は RUM(ラム)と名付けられたようです。
さらなる進化にむけて
9.6 の新機能以外にも、PostgreSQL を更に改善する試みや提案も数多くなされました。
EDB の Dilip Kumar からは、「単純なクエリ」を高速に実行できるようにする試みが発表されました(Run Simple Query Faster)。
今のエクゼキュータは複雑で幅広いタイプのクエリを実行できるように設計されていますが、その一方で集約、結合、サグクエリ等のない単純のクエリではそれがオーバヘッドになっている場合があります。
この講演では、単純なクエリの場合には不必要な処理をスキップすることで得られる性能改善について発表されました。
東京大学の Yuto Hayamizu と Ryoji Kawamichi の講演(Beyond EXPLAIN: Query Optimization From Theory To Code)では、大学の研究者の立場からクエリのプランナ(オプティマイザ)の解説が行われました。
この発表では一般的なクエリ最適化フレームワークの理論について概説した後、PostgreSQL で実装されているプランナにおけるコスト見積もり計算について詳しく解説されました。
しかし、これから予測されるコスト値と実際に計測された実行結果の間には差異が見られ、コスト見積もりが実に難しい課題であることが示されました。
講演の最後は、この問題を解決しうる最先端の研究の紹介で締めくくられました。
NTT OSS センタの Tatsuro Yamada の講演(A Challenge of Huge Billing System Migration)で紹介されたのは巨大システムのデータベースを他 RDBMS から PostgreSQL に移行するプロジェクトの事例です。
移行の要件として、現状の把握と将来の予測のため「性能が安定していること」があったのですが、検索条件の違いで実行時間が大幅に長くなってしまう(数分だったのが数時間に!)問題が移行中に見つかってしまいました。
そこで採用されたのが「pg_hint_plan」というプランナにヒント与えて挙動を制御できるツールです。
実は、PostgreSQL の開発コミュニティは他の RDBMS にあるようなヒント句の実装はしない方針であり、このツールの使用も好まれていません。
この講演では、そこをあえて pg_hint_plan を「禁断の果実」になぞらえてその利点を紹介しています。
ただし、講演の最後にはヒント使用以外のプランナの改善も提案されました。
例えば、過去のプランの実行結果をフィードバックさせることで徐々にプランを改善していくアイデアなどが挙げられていました。
アンカンファレンス

次にアンカンファレンスの様子をご報告します。
アンカンファレンスでは、まず最初に参加者が議論したい話題をその場で提案するところから始まります。
話したいことがある人は付箋にテーマを書き込み、それについて簡単に説明を行います。
その後、会場にいる参加者の多数決により議論するテーマが選ばれ、3 つのトラックに振り分けられることでタイムスケジュールが決定されます。
2日目に開催された、Developer Unconference では、テーブルのパーティショニング(分割)、ロジカルレプリケーション、ページ圧縮、トランザクションマネージャとマルチマスタ、パッチレビューの始め方、FDW(外部データラッパ)の非同期実行、などのトピックが選ばれていました。
PostgreSQL はテーブルパーティショニングをサポートしてはいますが、これは組み込みの機能はなく、「テーブルの継承」「CHECK制約」「トリガ」といった既存の機能の組み合わせで実現しています。
しかしこの方法には、テーブル数が多いとプラニングに時間がかかる、ハッシュ分割がサポートされていないなど分割の方法に制限がある、など多くの問題があります。
アンカンファレンスのパーティショニングのセッションでは、このような問題の整理と議論が行われていました。
PostgreSQL の開発コニュニティでは組み込みのパーティショニング機能の実現に向けて明示的な文法の議論が行われていますし、PostgresPro 社ではパーティショニングのパフォーマンス改善やハッシュ分割のサポートを行う pg_pathman というツールを開発しています。
パーティショニングは PostgreSQL の中でも注力して改善が進められている機能の1つと言えるでしょう。

ロジカルレプリケーションのセッションでは 2ndQuadrant(英国に本社のある PostgeSQL 会社)の Simon Riggs を中心に、PostgreSQL で論理レプリケーションを実現するための拡張モジュール pglogical について議論されていました。
ここでは課題として、DDL のサポートや、ドキュメンテーション、設定の管理などがキーワードに上がっていました。
トランザクションマネージャとマルチマスタのセッションでは、複数のノードを跨いだトランザクションを制御する「分散トランザクションマネージャ」の実現方法について、複数のアプローチを比較しながら議論が行われていました。
さらに、クラスタ上の全てのノードで更新が実行可能な、マルチマスタレプリケーション機能の試験的な実装についても紹介されました。
これは、上で紹介した pglogical の機能をベースに実装されているとのことでした。
User Unconference は最終日に開催されたこともあってか、参加数はやや少なめに感じました。
ここでは、コミュニティの行動規範の制定について、マルチマスタのデモ、バグトラッカー、ドキュメント中の図版、コンテナ上での PostgreSQL の利用、などがテーマに選ばれ議論されました。
マルチマスタのデモのセッションでは、Developer Unconference で議論されていたマルチマスタレプリケーション機能のプレゼンとデモが行われました。
プレゼンでは、マルチマスターレプリケーションは双方向レプリケーション(BDR)と分散トランザクションマネージャ(DTM)を組み合わせで実現されるとし、その動作についての解説が行われました。
また、性能については、更新に対して参照の割合が多い場合には単体の PostgreSQL よりも良いパフォーマンスが出ることが説明されました。
デモで使用された Dockerfile などのファイルは GitHub で公開されていますので、興味がある方は試してみてもよいかもしれません。
おわりに

今回の PGCon 2016 の特別であった点のまず1つ目は、冒頭での述べたことですが、今年が PostgerSQL 生誕 20 周年であり、第 10 回目の PGCon であったということでしょうか。
Oleg のライトニングトーク「20 Years of PostgreSQL」で使用された 動画では、これまでの PostgreSQL 開発に関わった人達の写真が流されました。
多くの方々の貢献があって現在の PostgreSQL があることを、改めて感じさせられました。
その他にも、20 周年記念バッチが個数限定(裏にナンバリングされています)作成されたり、恒例の チャリティーオークションでは PostgreSQL の 20歳を記念した Happy birthday ポスター(開発者のサイン入り)が 300 カナダドルで、Oleg の動画に登場した写真が散りばめられたポスター(開発者のサイン入り)は今回の最高額の 350 カナダドルで競り落とされていました。

そして、今回の PGCon の基調講演のテーマでもあった拡張性には、改めて PostgreSQL の未来を開拓する力を感じました。
ライトニングトークにおいても、分散トランザクションマネージャを実現する pg_tsdtm、性能の良いパーティショニングを実現する pg_pathman、Raft プロトコルベースのキー・バリューテーブルのレプリケーションを実現する raftable といった拡張モジュールが発表されました。
そのうち pg_tsdtm と raftable は、マルチマスタレプリケーションの実現のために開発されたものです。
これら拡張モジュールの機能が、いづれ PostgreSQL の本体へと取り込まれていく可能性もあるでしょう。
PostgreSQL 9.6 では、新機能の CREATE ACCESS METHOD を用いて新しいインデックスアクセスメソッドを定義することができるようになりました。
また、今回の PGCon のセッションでは、PostgreSQL のインデックスの内部構造についてレクチャーするセッションが複数あり(Index Internals、B-Tree – explore the heart of PostgreSQL)、インデックスに注目が集まっているような印象も受けました。
全文検索を効率化する RUM インデックスのように、これからも新しいインデックスの提案が増えてくるのかもしれません。
現在 PostgreSQL 9.6 が beta テスト中ですが、その次のリリースではバージョン番号が変わって、ついに PostgreSQL 10.0 が登場するという話が出ています。そこではいったいどのような機能が取り込まれ、さらにその先に何が可能になってくるのでしょうか。
今からとても楽しみです。