
2025年3月13日〜15日にタイ・バンコクで開催された FOSSASIA Summit 2025 および FOSSASIA PGDay 2025 に参加しましたので、その内容を報告いたします。
はじめに
FOSSASIA は、オープンソース技術の促進と開発を目的としたアジア最大級のコミュニティであり、オープンソースソフトウェア(FOSS: Free and Open Source Software)に加え、ハードウェア、オープンデータ、AI などの分野で活動しています。FOSSASIA Summit は、このコミュニティが毎年開催するアジア最大級のオープンソース技術イベントであり、開発者、イノベーター、企業、教育者が一堂に会し、知識と技術を共有する場となっています。

今回の会場は バンコク市内の The True Digital Park West で、大小さまざまなデジタル企業や団体が入居するオフィススペース、コワーキングスペース、会議室、飲食店、イベントスペースなどを備えた巨大な複合施設です。会期中の3日間にわたり、AI & Data Science、Cloud & DevOps、Database、Hardware & Firmware、Security、Robotics など多岐にわたるテーマの合計170のセッションが、常時3〜4トラック並行して開催されていました。
FOSSASIA PGDay 2025 は PostgreSQL に焦点を当てたイベントで、FOSSASIA Summit 2025 の数あるセッションの1つとして、2日目に開催されました。
本レポートでは、FOSSASIA Summit 2025 の発表の中から、特に PGDay に関連するトピックを中心にいくつか紹介します。
FOSSASIA PGDay 2025
まずは、PGDay で行われた講演について紹介します。

AWS と PostgreSQL コミュニティ
PGDay の最初の講演は、Amazon Web Services (AWS) の Michael Paquier 氏による “AWS and the PostgreSQL community” でした。この講演では、プラチナスポンサーでもある AWS と PostgreSQL コミュニティの関わりが紹介されました。Amazon RDS や Amazon Aurora などのサービスで活用されているように、AWS にとって PostgreSQL は重要な戦略的コンポーネントと位置づけられています。こうしたサービスを顧客中心の方針で展開する中で、AWS は PostgreSQL に対し、ユーザーの課題を解決する機能の提案や実装を行っています。実際、AWS の PostgreSQL コミュニティへの貢献は大きく、コアチームメンバー 1 人、コミッター 7 人が AWS に所属しています。最新リリースである PostgreSQL 17 では、AWS のメンバーによる 162 件のパッチがコミットされており、全体の 10.2% を占めるとのことです。

講演の後半には、顧客の問題を解決するため AWS が関わった PostgreSQL 17 新機能の例が2つ紹介されました。1つは組み込みの照合順序です。照合順序(collation)とはテキストをソートするときに利用される文字の順序を規定するもので、従来は libc、ICU といった外部のライブラリに依存していました。その場合、外部ライブラリがアップグレードされた際に、照合順序の変化によりインデックスの破損などの影響がでる可能性がありました。PostgreSQL 17 では外部ライブラリに依存しない組み込みの照合順序プロバイダを持てるようになっています。また、もう1つの例として論理レプリケーションの pg_upgrade 対応が挙げられていました。
pgroll: スキーマ移行ツール
Fujitsu の Kothari Nishchay 氏による講演 “PostgreSQL pgroll – Zero-Downtime, Reversible Schema Migrations” では、テーブル定義の変更を安全に行うためのオープンソースのコマンドラインツール pgroll が紹介されました。このツールを使うと、アプリケーションの互換性を破るような破壊的変更や、データベースをロックすることなく、スキーマ移行を行うことができます。
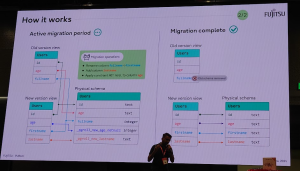
スキーマの変更は JSON ファイル形式でコマンドに指定します。複数のスキーマバージョンを同時に保持することができるため、アプリケーションに問題が発生した場合、元のスキーマにロールバックすることも可能です。この複数のスキーマ管理は、実際のテーブルにビューを使用して「仮想的なスキーマ」を作ることで実現されています。例えば、テーブルのカラム定義を変更する場合、実際のテーブルには古い定義のカラムを残し、新しいカラムを追加します。そして、このカラムの参照は新旧それぞれのスキーマに対応したビュー経由で行われ、。新旧カラム間のデータの同期はトリガを用いて行われます。移行が完全に完了すれば、古いバージョンのスキーマは削除可能となり、最終的に実際のテーブル定義が更新されます。
PostgreSQL と Microsoft SQL Server の違い
PostgreSQL は、他の RDBMS からの移行先としても人気が高まっています。AWS の Roneel Kumar 氏と Sameer Kumar 氏による講演 “Overcoming Challenges in SQL Server to PostgreSQL Migrations: Mapping Backups, Collations, and Case Sensitivity” では、Microsoft SQL Server(以下、SQL Server)から PostgreSQL への移行時に知っておくべき両者の違いが、二人の講演者による対話形式で紹介されました。
比較の内容は、データレイアウト、メモリ、トランザクションなどのアーキテクチャから、データ型、大文字小文字の扱いといったアプリケーション開発機能に関わるもの、バックアップやレプリケーションなどの運用面に至るまで、多岐にわたりました
例えば、トランザクションに関しては、PostgreSQL と SQL Server では同時実行制御の方法に大きな違いがあります。具体的な状況として、複数のトランザクションが同時にテーブルの同じ行にアクセスし、片方が行の更新、もう片方が参照を行う場合を考えます。PostgreSQL では基本的に MVCC(MultiVersion Concurrency Control:多版型同時実行制御)を使用しており、更新前の古い行の情報はテーブルの中に残ります。そのため、更新前の行への参照は、行の更新中でもロック待ちが発生しません。一方、SQL Server ではロックを使用しており、更新と参照の間でロック待ちが発生します。SQL Server でも Snapshot Isolation モードでは MVCC を使用しますが、その場合、古い更新前の行の情報は tempdb と呼ばれる別の領域に格納されるという違いがあります。

その他にも、データ型の違いに関して、SQL Server の bit データ型を移行するには PostgreSQL の boolean 型を使用するのが良いという情報や、SQL Server 向けに書かれたアプリケーションを PostgreSQL で動作させるためのツール Babelfish for PostgreSQL の紹介もありました。
PostgreSQL のベクトル検索
Postgres Professional (PostgresPro) の Vladlen Popolitov 氏による講演 “PostgreSQL for AI – Real Vector Search in PostgreSQL –” では、生成AIの普及により注目度が高まっているベクトル検索に関する解説が行われました。
ベクトルは、テキスト、画像、音声などのさまざまなデータを変換して生成することが可能で、これによりベクトル間の距離、つまり類似性に基づいた検索が可能になります。
このような検索機能を PostgreSQL に提供するのが、拡張モジュールの pgvector です。オープンソースであることによるコストの低さに加え、最近のパフォーマンス向上もあり、PostgreSQL + pgvector の組み合わせは、Pinecone など他のベクトル検索専用データベースと並ぶ人気の選択肢となりつつあります。
講演の前半では、pgvector がサポートするベクトルインデックスアルゴリズム HNSW(Hierarchical Navigable Small World) の概要や、パラメータ調整による検索レイテンシ・精度への影響、またベクトルサイズの削減がもたらす効果について説明がありました。
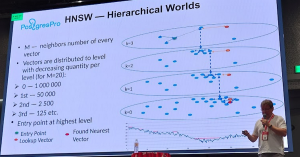
後半では、類似性検索とフィルタリング条件を併用する場合の課題について取り上げられました。たとえば、「あるテキストに似ていて、かつ著者が特定の人物で、言語が日本語であるテキストを10件抽出する」といった検索を行う場合、まずベクトルによる類似検索が行われた後に、追加のフィルタリングが実行されます。このため、初期の類似検索で十分な候補が得られなかった場合、指定件数(10件)に満たない結果しか得られないことがあります。
この課題への対応策としては、検索範囲を広げるようパラメータ設定を調整する方法がありますが、これは検索のレイテンシ(応答時間)の増加というトレードオフを伴います。別の対策として、部分インデックスを利用する方法も紹介されました。
さらに、pgvector v0.8.0 以降では新たに「反復スキャン(iterative scan)」という機能が導入されており、必要な件数が得られるまで自動で類似検索を繰り返すことが可能になっています。
最後に、フィルタリング検索用の他カラムを指定してベクトルインデックスを構築できる、マルチカラムベクトルインデックスについても言及がありました。現時点ではオープンソース実装は存在していませんが、PostgresPro が提供する商用パッケージでは既に対応しているとのことです。
Learned Index
Fujitsu Australia Limited の Gary Evans 氏による講演 “Exploring the benefits of learned indexes in PostgreSQL: Theory and Implementation” では、機械学習を活用したインデックス構造である Learned Index の理論と PostgreSQL への実装に関するアイデアが紹介されました。
インデックスは、データベースの検索性能を向上させるために広く利用されている構造で、抽象的には「キー値から対応するレコード位置を特定するマッピング」を提供するものです。たとえば、代表的なインデックス構造である B-tree は、木構造を使ってキーの探索を行います。
Learned Index は、このキー探索に機械学習モデルを応用する新しいアプローチです。まず、データの分布を学習させたモデルを使って、特定のキーが存在するおおよその位置を予測し、その周辺を効率的に探索することで、従来よりも高速な検索を実現します。また、インデックスのサイズを小さく抑えられるという利点もあります。

講演ではこの概念の解説に続き、2017年から現在に至るまでの Learned Index に関する研究の流れが紹介されました。学術界でも注目を集めるトピックであり、トップレベルのデータベース国際会議「VLDB 2023」で採択された論文のうち、11件が Learned Index に関するものであったことも紹介されました。
PostgreSQL で Learned Index の実装に取り組む理由としては、PostgreSQL の高い拡張性、pgvector などの進化する AI エコシステムの存在、Learned Index と相性の良いとされるパーティショニングや BRIN インデックス のサポート、充実したインデックスフレームワークなどが挙げられていました。また、実装アプローチとして、Learned Index の学習が進むまでは従来のインデックスと併用し、安定して動作するようになった段階で切り替えるとなどのアイデアも紹介されました。
最後に、想定される課題として、プランナによるコスト推定の精度や、複数トランザクションの同時実行時における安全性の確保などが挙げられていました。
アジアの多言語に対応した全文検索
地元タイのソフトウェアエンジニアである Vee Satayamas 氏による講演 “PostgreSQL extension that enables full-text searching on almost every known human language” は、PostgreSQL の全文検索を多言語に対応させる拡張モジュールの開発について紹介されました。
PostgreSQL には組み込みで全文検索機能が備わっていますが、デフォルトではタイ語や日本語など、主にアジアの言語には対応していないという課題が提示されました。これは、アジア開催の FOSSASIA PGDay らしい視点でもあります。
これまでにも、タイ語の全文検索に対応する拡張モジュールとして pg-search-thai が存在していましたが、長らくメンテナンスが行われていませんでした。そこで、Vee 氏はこのモジュールを Rust で再実装し、タイ語だけでなく、日本語、中国語、ミャンマー語などにも対応した chamkho-PG を開発したとのことです。

Injection Points: PostgreSQL の新しいテスト基盤
ASW の Michael Paquier 氏によるもう1つの講演 “Advanced testing with Injection Points” では PostgreSQL 17 で導入された新しいテスト機能について解説が行われました。この機能は、複数のプロセスが相互に関与するような状況のテストを容易にする、主に PostgreSQL の開発者を対象としています。
PostgreSQL コードの中には injection point と呼ばれるコードが数カ所埋め込まれており、テストコードはその箇所で特定のメッセージを出力させたり、プロセスを待機させたり、逆に待機しているプロセスを起こしたりといった様々な動作をさせることが可能となります。実際にこの機能は TAP テスト、Isolation テストと呼ばれる PostgreSQL のテストコードの中で使用されており、PostgreSQL の品質の向上に一役買っています。
実際にこの機能は、PostgreSQL のテストスイートに含まれる TAP テストや Isolation テストといった仕組みの中で活用されており、複雑な並行動作の検証や、エッジケースの再現性の向上に貢献しています。こうした Injection Points の導入により、PostgreSQL の品質はさらに高められています。
その他の発表
FOSSASIA PGDay 2025 ではこの他にも、拡張統計情報を自動生成するツール pg_stat_advisor の紹介、マルチマスタ論理レプリケーションクラスタを構築する pgEdge による DDL レプリケーションの自動化、PostgreSQL を使った メッセージキューの実装に関する議論、さらに Kafka で収集した膨大なログデータを PostgreSQL で効率的に管理するツール Bagger の紹介など、さまざまな興味深い講演が行われました。
FOSSASIA のその他の発表
続いて、FOSSASIA 2025 で行われた PGDay 以外の講演をいくつか紹介します。
ThaiLLM:タイにおけるオープンソースAIの取り組み
ビッグデータ研究所(Big Data Institute, BDI)の Tiranee Achalakul 博士による講演 “Empowering Thailand with Open Source AI: The Vision and Impact of ThaiLLMs” では、BDI の取り組みと、タイ独自の言語モデルである ThaiLLM プロジェクトについて紹介されました。
BDI はタイの公的機関であり、「医療・観光などに関するビッグデータの統合と解析」、「データの提供者と消費者を結びつけるエコシステムの構築」、「マイクロクレデンシャルを活用した人材育成」の3つがミッションとして紹介されました。
ThaiLLM は、2つ目のミッションである「ビッグデータエコシステムの構築」の一環として、国内の複数機関と連携して進められているプロジェクトです。このプロジェクトでは、タイ固有の言語や文化に適した AI モデルの開発を目指しており、生成されたモデルは 一部のデータやツール等も含めてオープンソースとして公開される予定とのことです。
Eval-Driven による生成AI開発
Mercari の Teofilo Narboneta Zosa氏と Jehandad Kamal氏による講演 “LLMOps for Eval-Driven Development at Scale” では、生成AIアプリケーションの開発における「評価」の重要性と、その方法論について解説されました。
冒頭では、生成AIアプリケーションを構成する基本要素として (1) 言語モデルそのもの、(2) 入力となるプロンプト、RAG (Retrieval Augumented Generation) により与えられるコンテキストなどのデータ、(3) モデルが生成する結果の評価の3つが挙げられ、この中でも、とくに 評価(3つ目の要素) を重視する「Eval-Centric」なアプローチが、生成AIアプリケーションの開発・運用において重要であると強調されました。
具体例として紹介されたのが、メルカリが提供する生成AI機能「AI出品サポート」です。これは、フリマに出品する商品の写真とカテゴリを入力するだけで、商品名や説明文を自動生成するというサービスです。
講演ではこのアプリケーションを例に、プロンプトの評価方法についてもいくつかの実践例が紹介されました。たとえば、最初は「タイトルの長さ」や「説明文が日本語で書かれているか」といった単純なヒューリスティック評価からスタートし、人間からその後は生成モデル自身を用いた評価、いわゆる LLM-as-a-Judge の手法を導入。また、トレーディングカードなどのニッチな商品に関しては、生成された説明文の事実性を検証するための工夫も必要であったことが語られました

後半では、評価を素早く反復できるようにするための具体的な実践として、モデルの入力や出力を可視化する可観測性の確保、プロンプトやデータセットのバージョン管理による再現性の確保、そして評価の自動化を支えるツールの導入といった、評価基盤の整備が重要であることが強調されました。
さまざまなデータベース
FOSSASIA Summit 2025 では、PostgreSQL 以外にもさまざまなデータベースに関する講演が行われました。
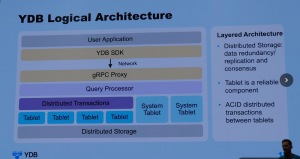
例えば、YDB の Evgenii Ivanov 氏の講演 “Designing YDB: Constructing a Distributed DBMS for OLTP and OLAP from the Ground Up” では、オープンソースの分散データベース管理システムである YDB が紹介されました。YDB は OLTP と OLAP の両方に対応したリレーショナルデータベースであり、コンピュートとストレージを分離し、数千台のサーバ上で動作可能な分散アーキテクチャを採用しています。また、分散トランザクションによって ACID 特性を満たす強い一貫性を提供するとのことでした。
講演の冒頭では、名前が似ている分散データベース管理システムである「YugabyteDB」とは別物であることが軽く触れられ、その後、主に分散ストレージのアーキテクチャについて詳しく説明されました。
さらに、WebStoating Pte. Ltd. の Ilya Verbitskiy 氏による講演 “Unlocking the Power of Graph Databases with Neo4j” では、グラフデータベース Neo4j の概要と、その問い合わせ言語である Cypher クエリの紹介がありました。また、MySQL の Phasupong 氏による講演 “MySQL Document Store” では、MySQL における JSON 型のサポートとその活用方法について解説が行われました。
特定のデータベースソフトウェアに特化していない講演として、Grab の Chin Hwee Ong 氏による “Your Data is Late Again! Handling Late-Arriving Data in the Modern Data Stack” では、データ処理基盤における遅れて到着するデータへの対応方法について解説されました。
講演の冒頭では、遅れたデータを正しく捉えるために重要な「時間」の概念として、(1) 現実世界でイベントが発生した時刻である Valid Time(有効時間)、(2) システムにデータが記録された時刻である System Time(システム時間)の2つが紹介されました。
その後、遅れて到着するデータが下流システムに与える影響を防ぐための方法として、遅延データの検出やデータ整合性を確認する手法が解説されました。また、遅れて到着したデータを差分的に処理する際の注意点についても触れられました。特に、遅れをどの程度まで遡って処理するかを決めることで、精度とパフォーマンスのトレードオフを調整する方法が紹介されました。
生成AI関連
上で述べたメルカリの講演以外にも、生成AIに関する講演も多数ありました。
例えば、Fleek Network の Mohit Bhat 氏による講演 “All About AI Agents: Building Your Own Open Source AI Agent to Post on Your Behalf” では、AI エージェント作成に必要となる基本概念として、LLM (言語モデル)、Embeddings (埋め込み)、RAG (Retrieval-Augmented Generation) について解説され、さらに ElizaOS などのフレームワークを用いた実践的なアプローチが紹介されました
また、Michael Christen 氏による講演 “The Complete Anatomy of ChatGPT: A Precise Breakdown of LLMs and Transformers” では、生成AIの発展を歴史的に振り返る内容が紹介されました。具体的には、マルコフ連鎖(1906年)から始まり、シャノンの情報理論(1948年)、パーセプトロン(1957年)、中国人の部屋(1980年)といった思考実験、リカレントニューラルネットワーク (RNNs)(1996年)、Convolutional Networks (CNNs)(1998年)、Embeddings(2002年)、アテンションメカニズム(2014年)、GPT-1(2018年)に至るまでの重要な理論や技術をエポックメイキングな論文を引用しながら、2022年に登場した ChatGPT へと至る過程を解説する大変興味深い内容でした。

データベースに関する講演として先に紹介した YDB と、生成AIに関する講演として YDB の Alexander Zevaykin 氏と Elena Kalinina 氏による “YDB: How to implement streaming RAG in a distributed database” では、YDB の非構造データのメッセージング機能「トピック」とベクトル検索機能を用いて、継続的に流入するデータに基づく RAG である「Streaming RAG」を実装する方法が解説されました。
Tor が支える匿名性と自由
セキュリティの分野では、The Tor Project の Roger Dingledine 氏による講演 “Tor: privacy for everyone” では、プライバシー保持のための技術である Tor について、その考え方と仕組みが紹介されました。「匿名性」という概念の捉え方は人によって異なり、例えば市民にとってはプライバシー、ビジネスにとってはセキュリティ、政府にとっては通信解析の障害となり得る一方、人権活動家にとっては情報への到達可能性を意味します。例えば、ある国では、BBC のニュースを政府によって阻止されずに読むために Tor が使用されている例が紹介されました。このように、社会的に弱い立場にいる人々にとってこそ、技術は特に有用であるという主張がなされました。
おわりに

今回の FOSSASIA Summit 2025 に参加して、まず感じたことは、タイおよびアジアにおけるオープンソースコミュニティの活力でした。特にタイ国内では、独自の言語モデル「ThaiLLM」のプロジェクトに代表されるように、オープンソース技術を活用したデジタル経済の普及・発展に力を入れていることが伺えました。
講演内容は、やはり全体的に AI 関連の話題が多く、オープンソースにおいてもこの分野がこれからさらに発展していくであろうことが感じられました。筆者は業務で主に PostgreSQL やデータベースの分野に関わっていますが、AI と関連する領域についての理解を深める必要性を改めて実感しました。
また、FOSSASIA はオープンソース技術全般の普及や発展を目的とする組織であるため、特定のオープンソース製品だけではなく、関連する概念や理論、アイデアについての発表も多かったことが印象的でした。まさに、オープンに知識や技術を共有する場として非常に刺激的なイベントでした。