
本記事では 2025 年 10 月 29 日から 30 日にかけて開催されたデータストリーミングのコミュニティイベント Current New Orleans 2025 の現地の様子をレポートします。
はじめに
Current はデータストリーミング分野の第一人者が一堂に会するコミュニティイベントです。イベントでは主に Apache Kafka® (以下 Kafka) や Apache Flink® (以下 Flink) などのストリーミング処理ソフトウェアに関する講演が行われ、世界中の人々が集まり交流、学び、そして情報共有する場です。
今年 2025 年は 3 月 19 日にインドのベンガルール、5 月 20 日にイギリスのロンドン、そして 10 月 29 日にアメリカのニューオーリンズで開催されました。今回はその中のニューオーリンズで開催されたイベントに参加してきましたので、私が聴講したセッションを中心にその様子をお伝えしたいと思います。
開催地、ニューオーリンズ
開催地であるニューオーリンズはアメリカのルイジアナ州南部にあるメキシコ湾に面した港湾都市です。ジャズの発祥地として有名で、フレンチクォータと呼ばれる地域ではフランス・スペイン植民地時代の街並みが残り、クレオール、ケイジャン料理などの美食も味わえる全米でも有数の観光都市でもあります。



イベント会場の様子
Current New Orleans 2025 はニューオーリンズの中心部、ミシシッピ川沿岸の Ernest N. Morial Convention Center (アーネスト N. モリアル コンベンションセンター) の一角で開催され、60 以上のセッションに 3,500 人以上が参加する非常に大規模なイベントとなりました。イベントホール内では 50 近いスポンサーブースが立ち並び、各社が提供するデータストリーミングに関する様々なソリューションの紹介や参加者同士の交流の場となっていました。




それ以外にもイベントホール内ではハッカソンが開催されていたり、VR の体験、ストリーミング処理ともかかわりの深い AI に関するアートの展示など、様々なイベントが開催され、大いに盛り上がっていました。


イベントで提供されるセッションは非常に多く複数のセッションが同時に行われていたため、そのすべてをレポートすることはできませんが、その中から私が聴講したものをいくつか紹介したいと思います。
一日目
Keynote (一日目): Building Intelligent Systems on Real-time Data
一日目の Keynoteでは Confluent 社の CEO 兼共同設立者、Jay Kreps 氏がプレゼンターとして壇上に立ちました。Confluent 社はカリフォルニアに本社を置き、Kafka を基盤とした企業向けのリアルタイムデータストリーミングプラットフォームやフルマネージドクラウドサービスを提供する会社で、日本法人として Confluent Japan もあります。また本イベント Current を主催する会社でもあります。

Keynote の主題は昨今の AI の台頭に対して、それを使ったシステムをどう構築し、組織内のソフトウェアそしてリアルタイムのデータとどう結び付けていくかについてです。効果的に AI を活用していくには AI が利用するデータをどのようにアップデートしていくかが重要です。例えばデータの更新をバッチ処理で行うとすればその分最新の状況との差異が生まれます。そこでリアルタイムデータを逐次的に処理できるストリーミングデータパイプラインを構築すれば、常にデータを最新に保ち続けることができます。そのシステムの構築に有効なのが Kafka や Flink といったストリーミング処理のソフトウェアです。企業にとっても日々生まれ続けるデータをリアルタイムに活用するためにはストリーム処理が必要不可欠なのだと感じました。
また Confluent Intelligence と名付けられた新しいサービスもこのセッションの中で発表されました。これはビルトインの機械学習関数、リアルタイムコンテキストエンジン、ストリーミングエージェントの 3 つの製品から構成されるサービスで、AI システムが過去のデータから継続的に学習し、リアルタイムで行動することを可能にするためのものとのことです。AI エージェントや RAG (検索強化生成)、AI 向け機械学習パイプラインの構築、または Kafka および Flink によるコンテキスト提供に活用が期待されるサービスです。


さらには、Confluent Private Cloud の発表も併せて行われました。これは Confluent Platform を基盤としており、自社インフラにクラウドサービスの効率性を備えたプライベートデータストリーミング環境を実現できるサービスとなるようです。
続いて一日目の個別セッションの内容をご紹介します。
Introduction to Apache Flink: Key Concepts and Architecture
ストリーム処理とバッチ処理の両方をサポートする分散処理フレームワークである Flink について解説する、初心者向けのワークショップセッションです。ストリーム処理とバッチ処理の概念や Flink による分散処理のコンセプトとアーキテクチャを基礎から丁寧に解説されており、ストリーム処理を一から学びたいという人にも最適なセッションだと感じました。

A Deep Dive into Kafka Consumer Rebalance Protocols: Mechanisms and Migration Process Insights
Kafka 4.0 で実装された新しい Consumer Rebalance Protocol の詳細について、既存との違いをデモを交えてわかりやすく解説されていました。また、既存のプロトコルからの移行のメカニズムについてもオンラインとオフライン両方に対応した方法を紹介されていました。
Consumer Rebalance Protocol とは、ConsumerGroup 内でどの Partition をどの Consumer に割り当てるかを調整するメカニズムです。従来のプロトコルではグループ内のメンバが変化した際に、リバランスが完了するまで一時的に Consume が停止するという制約がありましたが、新しいプロトコルではそれが軽減・削除されています。また、リバランスによる再割り当てのロジックを Broker 側に移動しており、それによる大幅な高速化や安定性の向上も見込めるという利点もあります。
The Kafka Protocol Deconstructed: A Live-Coded Deep Dive
このセッションでは Kafka が持つ様々な機能を実現する上でどのようなプロトコルを用いているのかを、かなり根本的な部分まで深掘りして解説されていました。例えば、リクエストのヘッダやボディがどういった要素から構成されていて、それぞれの要素にはどういった内容のデータが格納されているかなど、Kafka が実際にやり取りしている通信プロトコルを明らかにし、それを一から再構築するといったところまで実演していました。
プロトコルを深く知ることで Kafka の内部挙動を本質的に理解できると共に、実用上でのチューニングや問題解決にも応用できそうな、私にとっては非常に有用な内容でした。
Current party
一日目の終わりには参加者ならだれでも参加できるパーティが開かれました。時期が近いこともあり、中はハロウィン風の装飾がされていたり、ニューオーリンズらしくライブ演奏やクレオール、ケイジャン料理が味わえたりと様々な趣向が凝らされており、参加者同士の交流を深めるという意味でも非常に有意義なパーティでした。



二日目
Keynote (二日目): Be Ready for What’s Next
二日目の Keynote では Confluent 社のアドボカシーおよびデベロッパーエクスペリエンスエンジニアリング部門責任者の Adi Polak 氏が登場し、リアルタイムシステムの現在までの発展の経緯について語りました。モノリシックなシステムからマイクロサービスへの転換、マイクロサービス同士をつなぐ Kafka の登場、そしてデータレイクとして Apache Hadoop と HDFS から Apache Iceberg、Apache Hudi、Delta Lake といったテーブルフォーマットを導入したことによる信頼性の向上。これらの発展によって今現実に起こっていることをリアルタイムで処理するための準備が整いました。そして現在 AI が登場しました。真に信頼できる AI のためには優れたモデルが必要ですが、それを構築・実用するには信頼できるリアルタイムデータ、ひいてはそれを作り出す信頼できるシステムを準備しておくことが必要であると彼女は述べていました。

このセッションではその他にもテレビ番組のトークショーを模した形式でのデータストリーミング分野の第一人者へのインタビューや、コミュニティやこの分野に貢献した企業への授賞式なども行われました。

続いて二日目の個別セッションの内容をご紹介します。
What Can you do with a (Kafka) Queue?
このセッションでは Kafka をメッセージキューとして利用可能にするための新しい Consumer Group の実装である、Share Group について解説されていました。従来の Consumer Group では Partition 内でのメッセージ順序を維持するために、グループ内で重複して同じ Partition からメッセージを取得することはありませんが、Share Group ではそれを可能にすることでメッセージキューとして Kafka を使うことができるようになります。この機能はまだ完全に実装されてはいませんが、これによって Kafka の用途の可能性が広がる非常に興味深いものだと感じました。
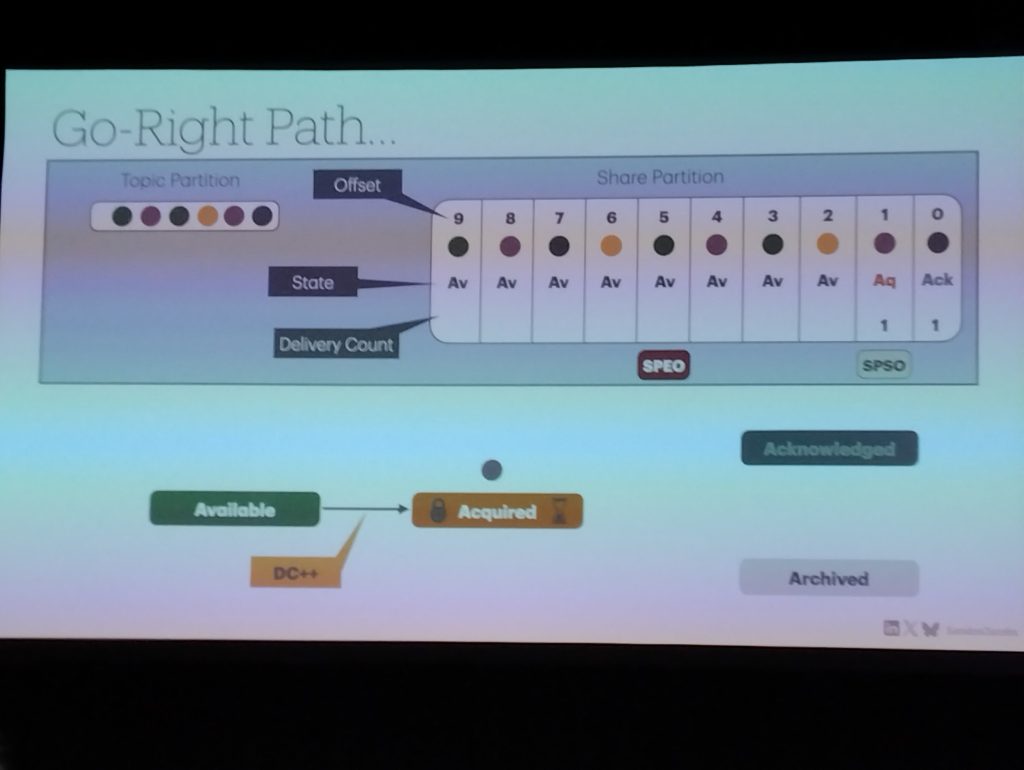
Playing Chess by Scaling Multi-Agent LLM Play with Kafka Queues
これは上記の Kafka のキュー機能を利用して、LLM (大規模言語モデル) にチェスを並列で同時にプレイさせてみたという、中々面白い内容のセッションです。AI と Kafka の新機能を組み合わせることで、アイディアによってはこういう使い方もできるんだという一例だと思います。実際にセッション中にデモを披露していましたが、かなりスムーズに LLM がチェスを複数盤面で同時にプレイする様子も伺えました。

AI 関連のセッション
Keynote で言及もあったように、データストリーミングは AI とも関連の深い分野です。本イベントでも AI に関するセッションは数多くあり、AI Alley Theater という AI セッション専用のブースが設けられるほどでした。


その他のイベントの様子




おわりに
Current はデータストリーミングの現在を肌で感じることのできる唯一のイベントです。私も今回参加したことで、Kafka をはじめとしたストリーミング処理について、最新の動向や深い知見を大いに得ることができ、データストリーミングの分野が今いかにホットであるかということを知ることができました。
セッションの内容も幅広く、初心者向けに Kafka や Flink といったデータストリーミングプラットフォームを構成するソフトウェアの基礎を解説するものや、より深く内部動作を解説するもの、ソリューションや活用例を紹介するものなど、データストリーミングを知りたい様々な層に広く訴求するイベントだと感じました。皆さんもデータストリーミングに興味があれば、是非参加してみることをお勧めします。
また、本イベントのセッションは動画でアーカイブされており、誰でも見ることができます。非常に多くの有用なセッションがありますので、データストリーミングや Kafka、Flink などのソフトウェアについて知りたいという方は、こちらもチェックしてみてください。