1. はじめに
前回の記事では、Zabbix のインストール、基本的な設定、監視対象と基本的な監視項目の設定方法までを行いました。
今回は、その他の監視機能の説明や、指定した条件による障害検知とアラートメールの送信、グラフ表示機能などを紹介します。
2. Zabbix の監視機能について
Zabbix では多種多様な用途、目的に対応するために、さまざまな監視方法に対応しています。
以下は Zabbix 5.0 が対応している各機能の概要です。
| 監視タイプ (アイテムタイプ) |
概要 | 監視項目例・使用例 |
|---|---|---|
| Zabbixエージェント | Zabbix エージェントによる監視 (サーバからエージェントに対してデータを要求) |
CPU使用率、メモリ使用率、ディスク使用率、ファイル監視、Web 監視 |
| Zabbixエージェント (アクティブ) |
Zabbix エージェントによる監視 (エージェントからサーバに定期的にデータを送信) |
ログ監視 |
| シンプルチェック | Ping など Zabbix エージェントを使用しない監視 | ICMP ping、TCP 疎通、TCP 応答時間 |
| SNMPエージェント | SNMP エージェントによる監視 | CPU 使用率、メモリ使用率、ディスク使用率、ディスクI/O、ネットワークI/O |
| SNMPトラップ | SNMP トラップを受信 | linkDown, linkUp |
| Zabbixインターナル | Zabbix サーバ自身の監視 | 稼働時間、アイテム数、内部プロセスの CPU 使用率 |
| Zabbixトラッパー | zabbix_sender コマンドで送付されたデータを受信 | zabbix_sender コマンドによるデータ送信 |
| Zabbixアグリゲート | 同じホストグループに所属しているホストの同じキーを持つアイテムのデータから合計、最大、最小、平均を計算 | 複数機器のネットトラフィックの平均、最大/最小 |
| 外部チェック | Zabbix サーバ上でスクリプトやコマンドを実行し結果を取得 | スクリプトによる NTP サーバの稼働監視 |
| データベースモニタ | ODBC 経由で RDBMS に SQL を実行し結果を取得 | MySQL の稼働監視 |
| HTTPエージェント | HTTP や HTTPS でリクエストを行った結果を取得 | 特定の Web ページのコンテンツ取得 |
| IPMIエージェント | IPMI エージェントからデータを取得 | サーバの CPU の温度監視 |
| SSHエージェント | SSH 経由でコマンド実行した結果の取得 | OS の内部ステータスやアプリケーションの監視 |
| TELNETエージェント | Telnet 経由でコマンド実行した結果の取得 | OS の内部ステータスやアプリケーションの監視 |
| JMXエージェント | Java Gateway 経由で Java の JMX からデータを取得 | Java アプリケーションの監視 |
| 計算 | 任意のアイテムで取得したデータから四則演算などを行った結果を取得 | NIC のネットワーク帯域幅の合計を計算 |
| 依存アイテム | 他の任意のアイテムで取得したデータを受信する | JSON でデータを取得するアイテムから特定の項目だけ抜き出す |
3. Zabbix エージェント監視の種類
ここでは、使用頻度が高いと思われる Zabbix エージェントの監視項目のうち、代表的なものを紹介します。
その他のキーや監視タイプについては、Zabbix マニュアルの以下の項目を参照してください。
Zabbix エージェントの代表的なキー一覧
| 監視項目 | キー | 戻り値 | 設定例 |
|---|---|---|---|
| CPU 使用率 | system.cpu.util[<cpu>,<type>,<mode>] system.cpu.load[<cpu>,<mode>] |
使用率 (%) 浮動小数 |
system.cpu.util[,user,avg5] system.cpu.load[,avg5] |
| メモリ使用率 | vm.memory.size[<mode>] | バイト数 / % | vm.memory.size[free] |
| ディスク使用率 | vfs.fs.size[fs,<mode>] | バイト数 / % | vfs.fs.size[/,pfree] |
| ネットワーク使用率 | net.if.in[if,<mode>] net.if.out[if,<mode>] |
整数 | net.if.in[eth0,bytes] net.if.out[eth0,bytes] |
| プロセス起動数 | proc.num[<name>,<user>,<state>,<cmdline>] | プロセス数 | proc.num[httpd,apache] |
| ポート | net.tcp.port[<ip>,port] net.tcp.service[service,<ip>,<port>] |
0(down) / 1(up) | net.tcp.port[,80] net.tcp.service[http] |
| ファイルのチェックサム | vfs.file.cksum[file] | チェックサム | vfs.file.cksum[/etc/passwd] |
Zabbix エージェント(アクティブ)の代表的なキー一覧
| 監視項目 | キー | 設定例 |
|---|---|---|
| ログ監視 | log[file,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>] logrt[file,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>] |
log[/var/log/messages,,,100,,,] logrt[“/var/log/^messages-[0-9]{8}$”,,,100,,,] |
4. ログ監視について
ログの監視を行うには、Zabbix エージェント (アクティブ) を使用する必要があります。
通常の Zabbix エージェントは、サーバから定期的にデータを要求しに行きますが、Zabbix エージェント (アクティブ) は、エージェント自身が能動的に監視を行い、データをサーバに送信します。
log[file,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>]
は、1 つのログファイルのみを監視します。
logrt[file_format,<regexp>,<encoding>,<maxlines>,<mode>,<output>,<maxdelay>,<options>]
は、ローテートされた複数のログファイルを監視します。
ファイル名の候補は正規表現で指定します。
例えば、「/var/log/^messages-[0-9]{8}$」であれば「/var/log/messages-20211025」などのファイルが対象になります。
また、ログ監視では Zabbix エージェントを動作させるユーザー (zabbix) がログファイルにアクセスする権限が必要になりますので注意してください。
5. メディアタイプとメディアの設定
障害を検知した場合にメールを送信するには、事前にメディアタイプとメディアを設定しておく必要があります。
まずメディアタイプでメールの送信に使用するメールサーバを設定します。
-
- [管理] → [メディアタイプ] をクリックし、メディアタイプ一覧から「Email」をクリックします。
- 「SMTPサーバー」、「SMTP helo」、「送信元メールアドレス」を環境に合わせて適切に編集し、[更新] をクリックします。
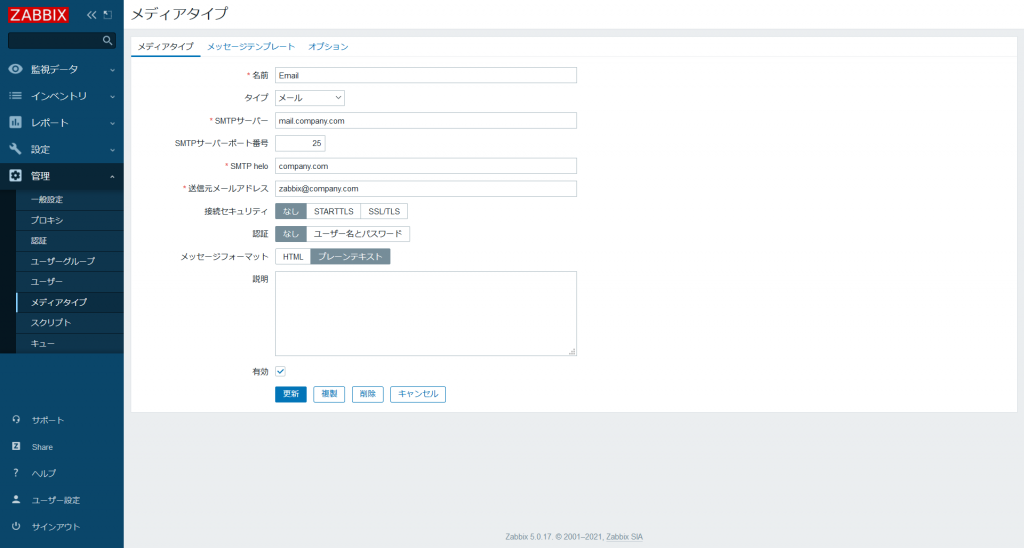
- 次にユーザーのメール送信先を設定します。ここでは Admin について設定します。
- 画面左下の [ユーザー設定] をクリックし、Admin ユーザーの設定ページを開きます。
- [メディア] タブをクリックし、[追加] をクリックすると、設定フォームが開くので以下の内容を設定し、[追加] をクリックします。
| タイプ | |
|---|---|
| 送信先 | (障害を通知するメールアドレス) |
| 有効な時間帯 | 1-7,00:00-24:00 |
| 指定した深刻度のときに使用 | 軽度の障害、重度の障害、致命的な障害にチェックを入れる |
| ステータス | 有効 |
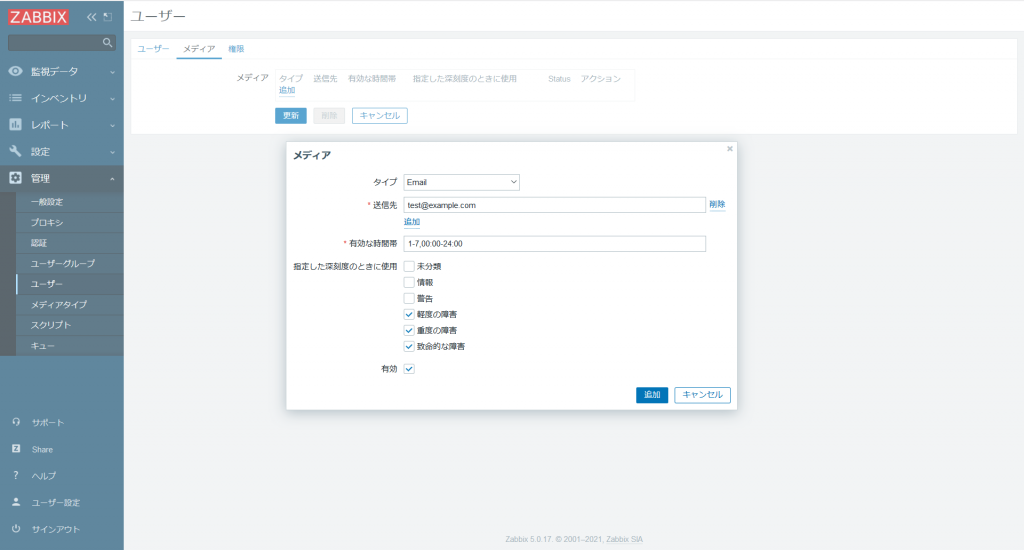
追加が完了すると以下の表示に変わります。設定に問題がなければ [更新] をクリックします。
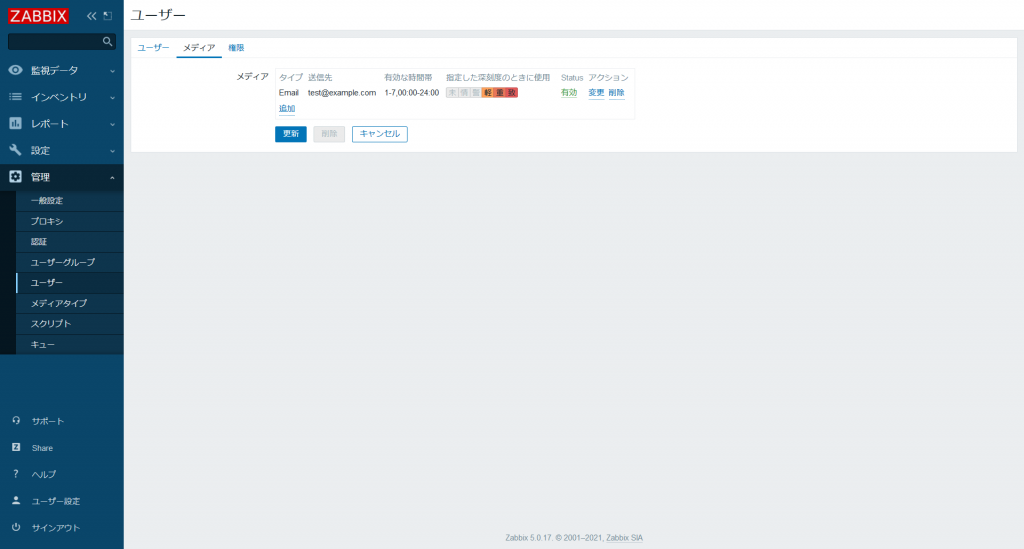
以上で、Zabbix が障害を検知した際に指定したアドレスにメールが送信されるようになりました。
また、今回はメールの設定を紹介しましたが、Webhook を用いて Slack や Microsoft Teams などのツールに通知を送信することも可能です。
6. トリガーの設定
Zabbix では、障害と復旧の検知の設定をトリガーと呼びます。
前回は CPU 使用率を監視するアイテムを作成しました。
今回は、それに対して、5 分間の CPU 使用率の平均値が一定の閾値を上回った場合は障害と判定し、アラートメールを送信するように設定してみましょう。
まずトリガーを作成します。
- [設定] → [テンプレート] を選択します。
- テンプレート一覧から「テストテンプレート」行の [トリガー] をクリックします。
- 画面右上の [トリガーの作成] をクリックします。
- 以下の項目を入力し、[保存] をクリックします。
| 名前 | CPU usage is too high |
|---|---|
| 条件式 | {Test template:system.cpu.util[,,].avg(300)}>90 |
| 説明 | 最近 5 分間の CPU 使用率の平均が 90 % を超えています |
| 深刻度 | 軽度の障害 |
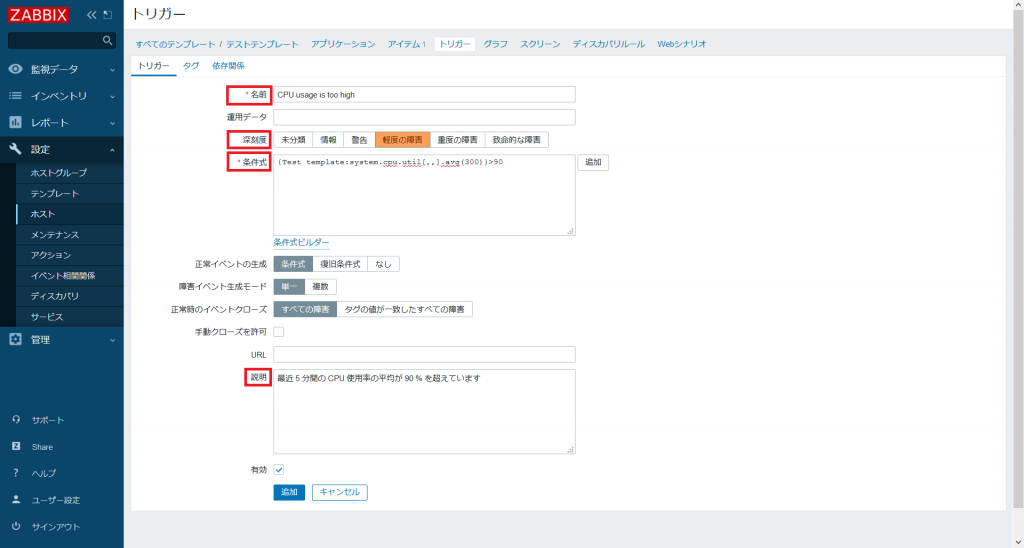
トリガーの条件式はテキストボックスに直接入力することもできますし、テキストボックス右横の [追加] ボタンをクリックし、設定フォームの項目に設定内容を入力することでも追加できます。項目を入力したら [挿入] をクリックします。
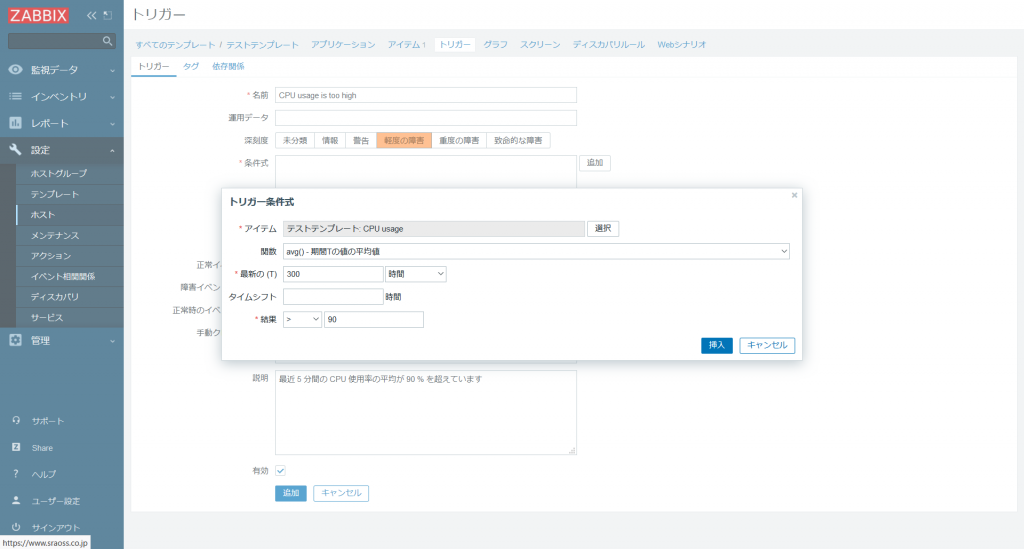
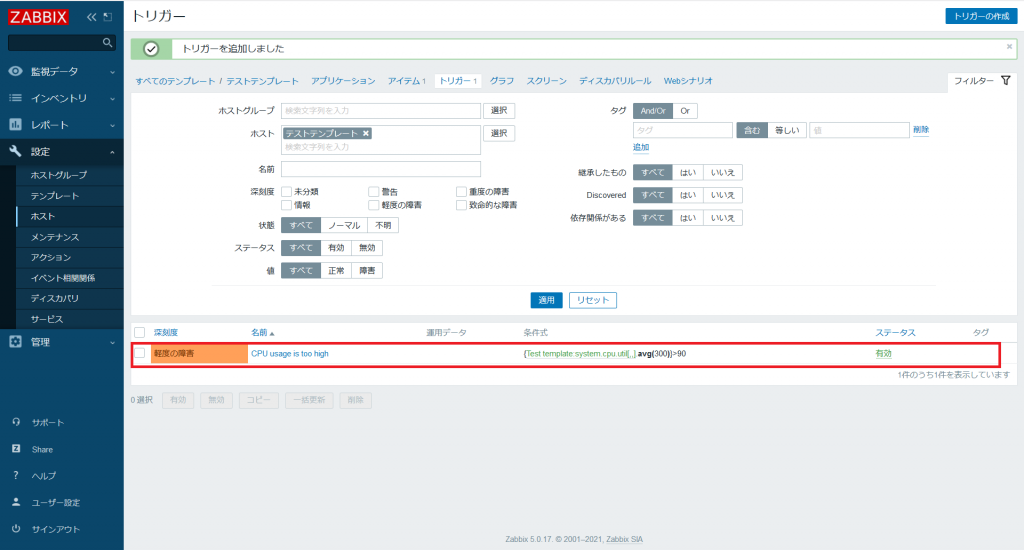
トリガーの作成に成功すると、以下のようにトリガー一覧に表示されます。(トリガー作成直後の場合は、まだ値を取得できていないためエラーが表示されることがあります。)
また、「テストテンプレート」をリンクしているホスト「Zabbix-agent」にも「テストテンプレート」で作成したトリガーが設定されたことが分かります。
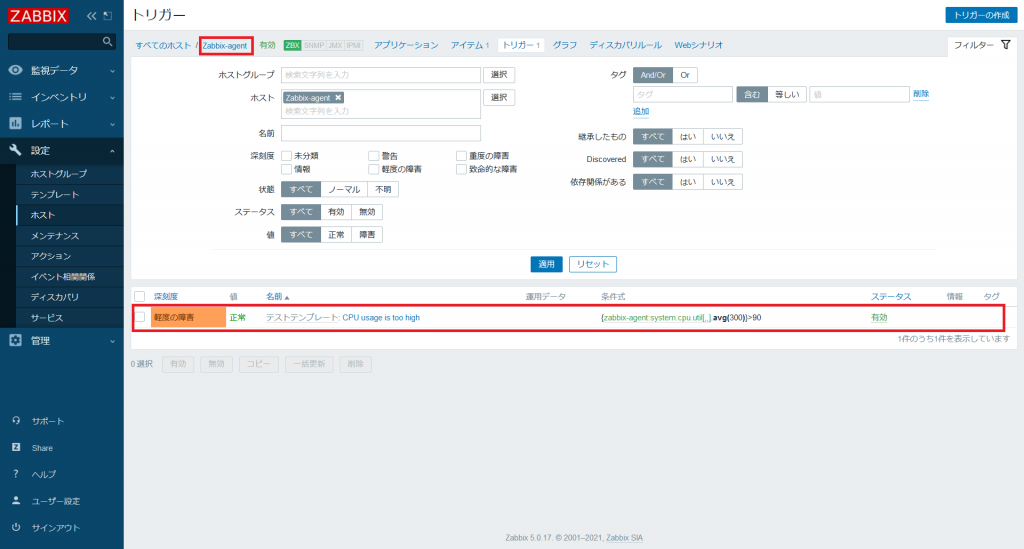
トリガーの設定により、障害を検知できるようになりました。次は障害を検知した際に通知をする設定を行います。
7. アクションの設定
Zabbix では、障害発生時や復旧時の動作の設定をアクションと呼びます。
先程設定したトリガーで障害を検知した場合に、指定したユーザーにメールを送信するアクションを作成します。
-
- [設定] → [アクション] を選択します。
- 画面右上の [アクションの作成] をクリックします。
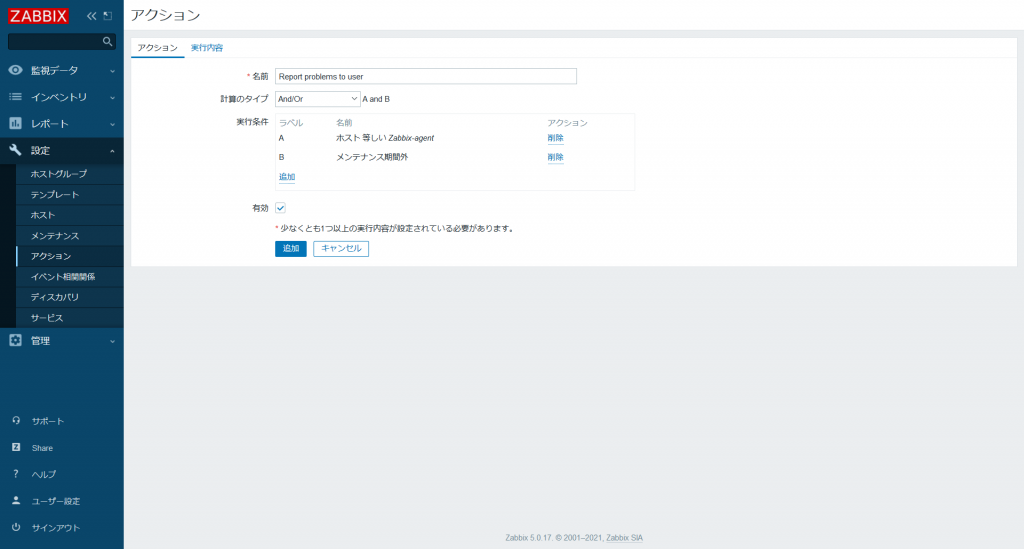
- [アクション] タブで以下の項目を入力します。
| 名前 | Report problems to user |
|---|---|
| 計算のタイプ | AND/OR |
| 実行条件 | (A) ホスト 等しい ”Zabbix-agent” |
| (B) メンテナンス期間中 “いいえ” | |
| 有効 | チェックする |
実行条件については [追加] をクリックして条件を追加することができます。
- [実行内容] タブをクリックし、アクションの実行内容を設定します。今回は [デフォルトのアクション実行ステップの間隔」と「メンテナンス中の場合に実行を保留」はデフォルトのままとします。[実行内容] の [追加] をクリックし、設定フォームを開きます。
- 以下の項目を設定します。その他はデフォルトのままとします。
| ユーザーに送信 | Admin |
|---|---|
| 次のメディアのみ使用 |
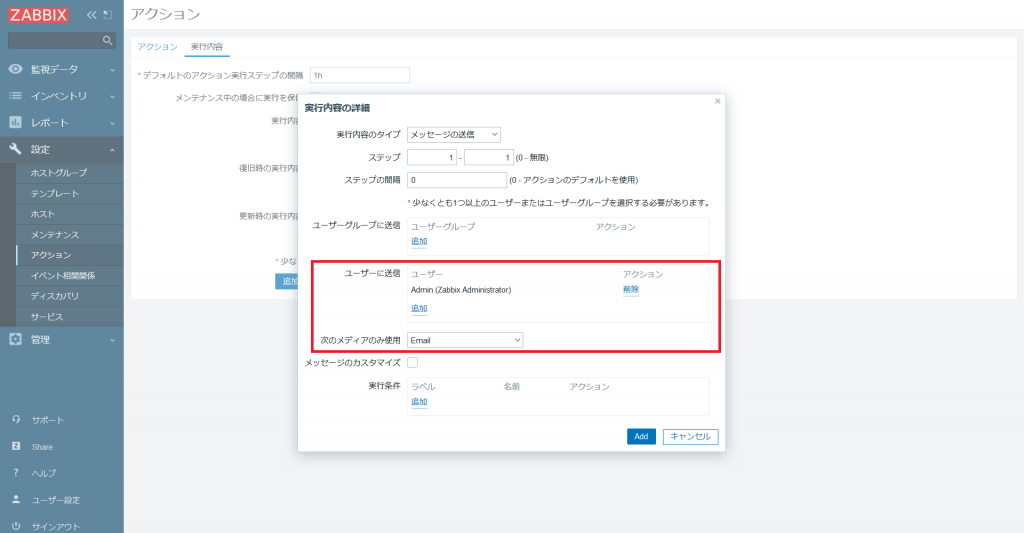
ここで通知メッセージについてですが、[メッセージのカスタマイズ] にチェックを入れることで任意のメッセージ設定を行うことができますが、今回はメディアタイプ「Email」に元々設定されているメッセージテンプレートを利用します。
メディアタイプ「Email」の障害通知のメッセージテンプレートは [管理] → [メディアタイプ] → 「Email」の [メッセージテンプレート] タブから確認および設定ができます。[障害] のメッセージテンプレートは以下となっています。
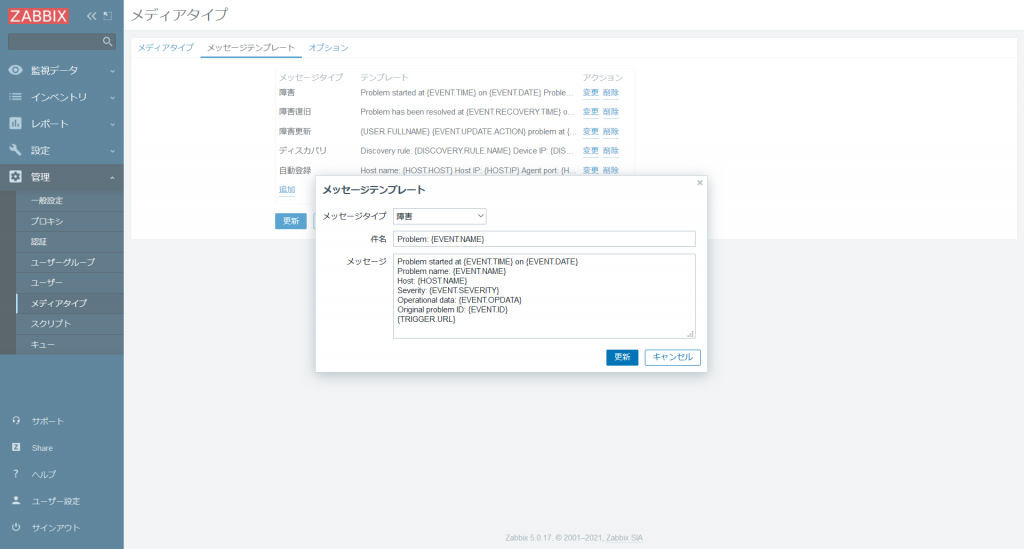
メッセージに記載されている {EVENT.NAME} などはマクロと呼ばれています。例えば {EVENT.NAME} であれば障害名、{HOST.NAME} であれば障害が発生したホスト名にメッセージを送信する際に変換してくれます。マクロについては Zabbix マニュアルもご参照ください。
このメッセージテンプレートによりメディアタイプ「Email」を他のアクションでも使用する場合に同じ形式のメッセージを通知することができます。
次に [復旧時の実行内容] についても同様に設定をします。障害復旧に関するメッセージテンプレートも用意されていますのでこちらについても [メッセージのカスタマイズ] にはチェックを入れません。
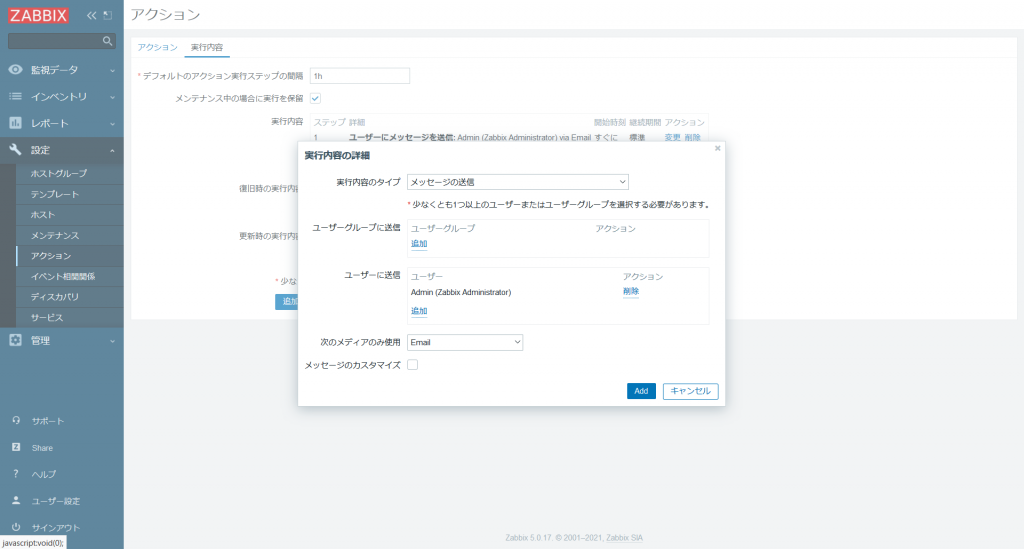
今回は [更新時の実行内容] は設定をしません。ここまでの設定ができたら [更新] をクリックします。
すると、アクションの一覧に作成したアクション「Report problems to user」が表示されます。
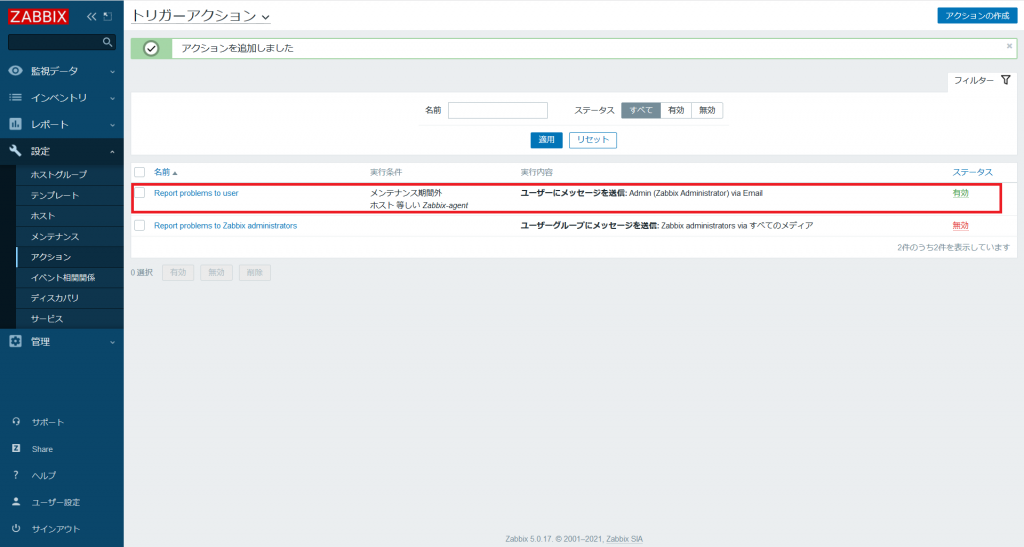
以上で障害検知した際の通知を送信する条件や実行内容を設定することができました。
8. 障害検知の確認
それでは、実際に疑似的に障害を発生させ、それが検知されるかを確認してみましょう。
Zabbix エージェントが動作している監視対象のホストにログインし、以下のコマンドを実行して 5 分以上待ち、Ctrl-C で停止します。
※ CPU 使用率が 100 % になるため、実際にサービスが稼働しているホストでは実行しないでください。
$ yes > /dev/null (Ctrl-Cで停止)
[監視データ] → [障害] から現在発生中の障害や履歴を確認することができます。
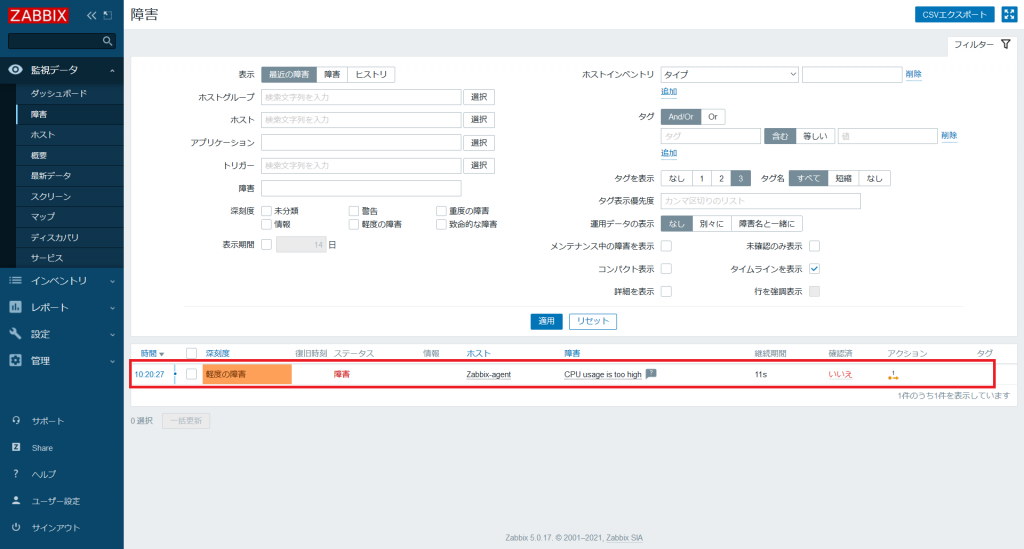
障害の発生時刻や継続期間 (発生してから現在までの経過時間) などの情報を確認することができます。
また、ユーザーのメディアで設定したメールアドレスに、以下のような障害通知メールが届きます。
通知内容から 2021/10/22 10:20:27 にホスト「Zabbix-agent」で障害が発生したことが分かります。
件名: Problem: CPU usage is too high メッセージ: Problem started at 10:20:27 on 2021.10.22 Problem name: CPU usage is too high Host: Zabbix-agent Severity: Average Operational data: 98.37074 Original problem ID: 15
本障害が復旧した際には以下のような復旧通知メールが届きます。
こちらの通知内容では同日の 10:22:27 に復旧していることが分かります。
件名: Resolved in 2m 0s: CPU usage is too high メッセージ: Problem has been resolved at 10:22:27 on 2021.10.22 Problem name: CPU usage is too high Problem duration: 2m 0s Host: Zabbix-agent Severity: Average Original problem ID: 15
ここまでで Zabbix における障害を検知する設定 (トリガーの設定)、障害を検知した際にメッセージを送信する通知先の設定 (メディアタイプおよびユーザーの設定)、通知の条件や内容を設定 (アクションの設定) を行いました。
9. グラフの作成
Zabbix では、特に設定を行わなくても各アイテムの履歴をグラフで表示することができますが、複数の監視項目のデータを 1 つのグラフにまとめて表示することもできます。
これにより、一目でシステムの状態を把握することができます。
なお、事前に以下のアイテムを「テストテンプレート」に作成しておきます。
| 名前 | CPU load |
|---|---|
| タイプ | Zabbixエージェント |
| キー | キー |
| データ型 | データ型 |
| 監視間隔 | 30s |
それでは以下の手順で「テストテンプレート」にグラフを作成します。
-
- [設定] → [テンプレート] をクリックします。
- テンプレート一覧から「テストテンプレート」行の [グラフ] をクリックします。
- 画面右上の [グラフの作成] をクリックし、以下の項目を入力します。
| 名前 | CPU load/usage |
|---|---|
| 高さ | 200 |
| グラフのタイプ | ノーマル |
| 凡例を表示 | チェックする |
| ワーキングタイムの表示 | チェックする |
| トリガーを表示 | チェックする |
| Y軸の最小値 | 計算 |
| Y軸の最大値 | 計算 |
- [アイテム] の [追加] をクリックし、対象のアイテムにチェックを入れて選択します。追加された項目について以下のように設定します。
名前 関数 グラフの形式 Y軸 色 テストテンプレート: CPU load 平均 線 右 1A7C11 テストテンプレート: CPU usage 平均 線 左 F63100 - [保存] をクリックします。
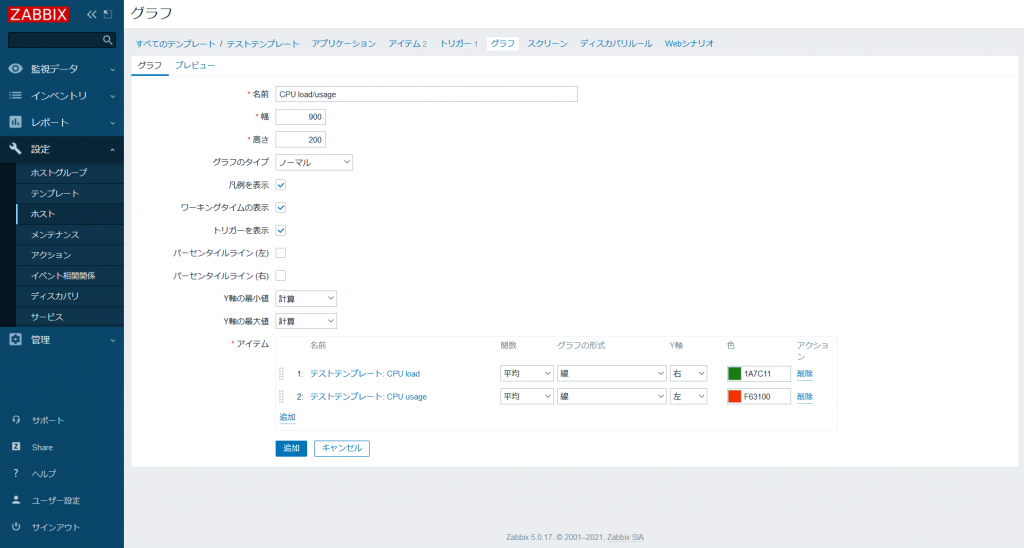
今回は「テストテンプレート」にグラフを作成したので、リンクしているホスト「Zabbix-agent」にも上記のグラフが作成されます。
それではホスト「Zabbix-agent」のグラフを確認してみましょう。
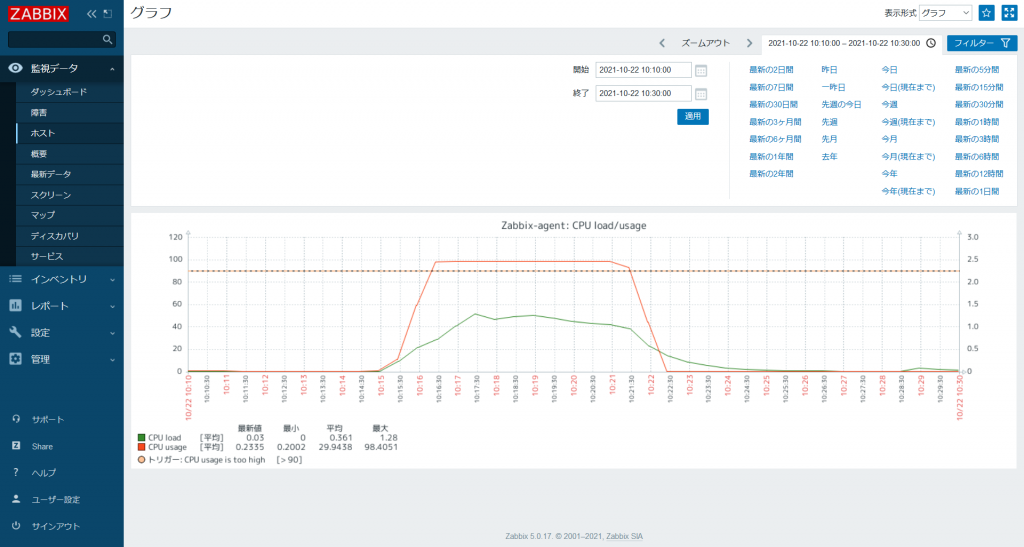
[監視データ] → [ホスト] で「Zabbix-agent」行の [グラフ] を選択すると、以下のようにグラフが表示されます。
「CPU load」は右側の Y 軸を、「CPU usage」は左側の Y 軸を参照します。
また、画面上部で表示期間を指定できるほか、現在表示している期間から直接表示期間を短くすることができます。
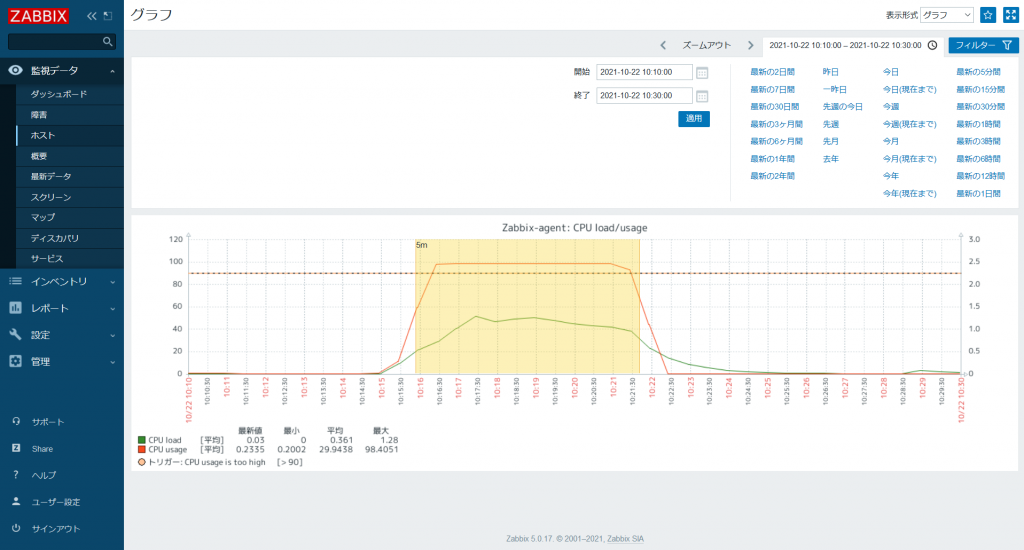
黄色で囲まれた範囲が表示されます。
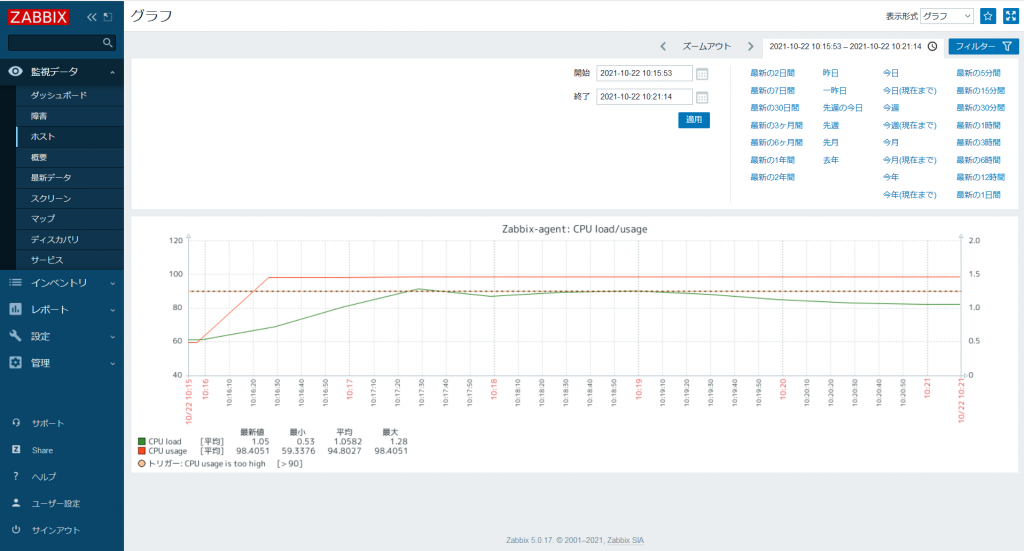
また、グラフの下に各アイテム名と [最新値] などの表示がありますが、表示期間の中でのそのアイテムの最新値や最大値を表示しています。グラフ上にオレンジ色の点線がありますが、アイテム「CPU usage」を使用しているトリガー「CPU usage is too high」の閾値を表しています。
最後に、グラフをドラッグし、デスクトップなどにドロップすることで現在表示しているグラフを画像ファイルとして保存することが可能です。
10. ダッシュボード
ダッシュボードは、任意のグラフや障害履歴、ホストの状態などを一つの画面にカスタマイズして表示させることができます。
Zabbix にログインした際にデフォルトで「Global view」というダッシュボードが表示されます。
「Global view」では「システム情報」、「ホスト稼働状況」、「深刻度ごとの障害数」、「Zabbix サーバが稼働しているサーバの時刻」、「障害」、「お気に入りのマップ」、「お気に入りのグラフ」のウィジェットが用意されています。
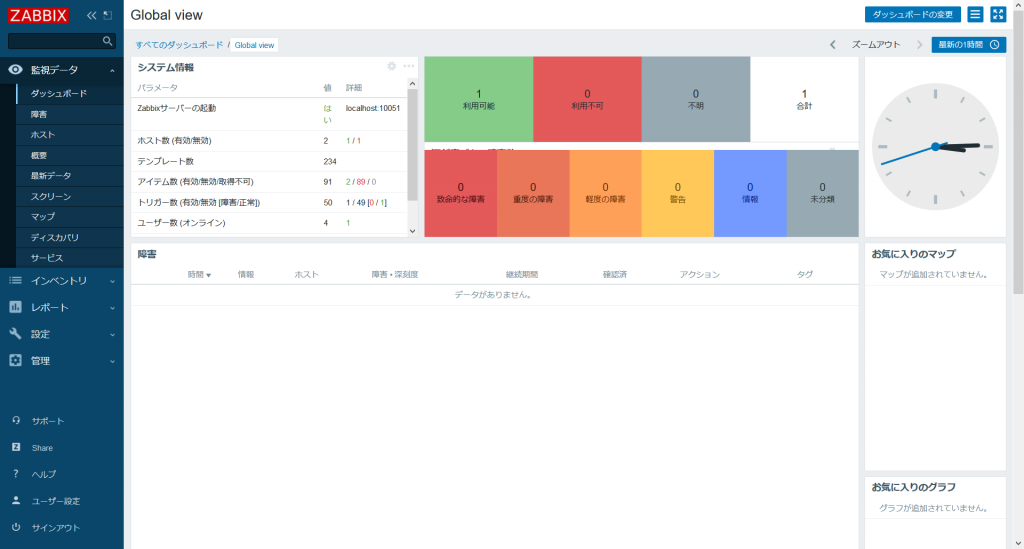
「システム情報」にはホストやアイテム数の情報など Zabbix サーバのシステム情報が表示されます。
「ホスト稼働状況」にはホストの状態が「利用可能」、「利用不可」、「不明」で分類されて、表示されます。
「深刻度ごとの障害数」には文面の通り、現在発生している障害数が深刻度ごとに表示されます。
「障害」には障害発生の履歴が表示されます。
「お気に入りのマップ」、「お気に入りのグラフ」についてはデフォルトでは何も表示されません。任意のマップやグラフの画面でお気に入り登録する必要があります。今回は「マップ」については紹介していませんので省略させていただきます。
それでは「9. グラフの作成」で作成したグラフ「Zabbix-agent: CPU load/usage」をお気に入り登録してみましょう。
[監視] → [ホスト] で「Zabbix-agent」行の「グラフ」をクリックします。
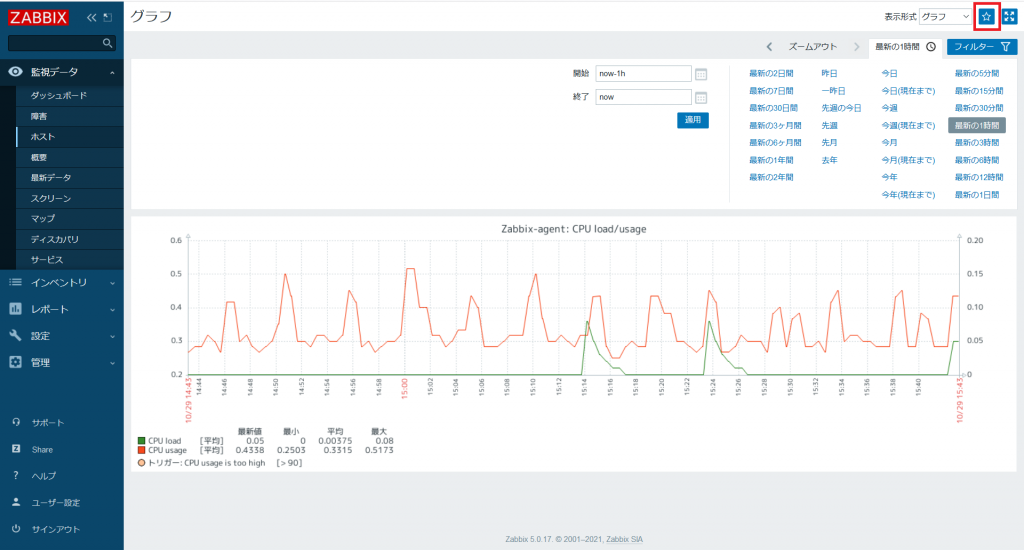
画面右上の星アイコンをクリックすることでお気に入り登録ができます。登録すると星アイコンが黄色に変わります。
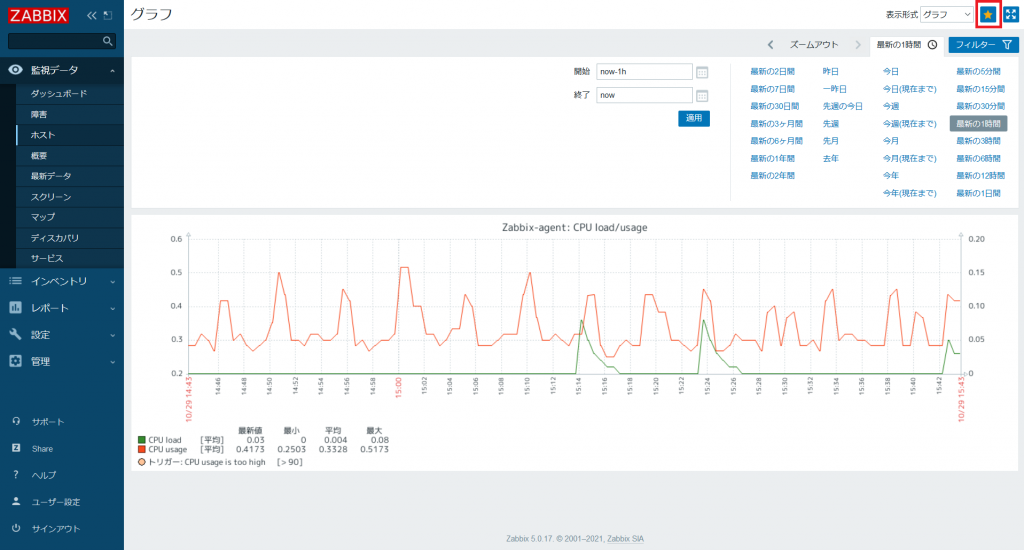
それでは [監視データ] → [ダッシュボード] で「Global view」に戻ります。
「お気に入りのグラフ」に「Zabbix-agent: CPU load/usage」のリンクが表示されました。不要になった場合は名前の右側にある×アイコンをクリックするとお気に入りが解除されます。
また、お気に入りの登録はユーザー単位で行います。Admin ユーザーで「Zabbix-agent: CPU load/usage」をお気に入りにした場合は Admin ユーザーでログインした際には「お気に入りのグラフ」に表示されますが、他のユーザーでログインした際には表示されません。
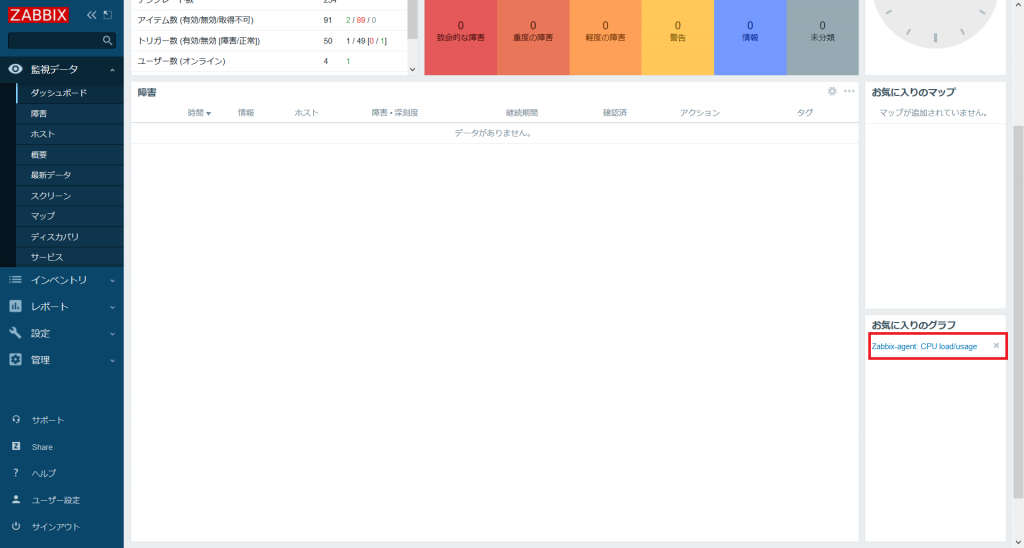
「お気に入りのグラフ」にはグラフのリンクのみ表示されますので、実際にグラフ「Zabbix-agent: CPU load/usage」を「Global view」に表示させてみましょう。
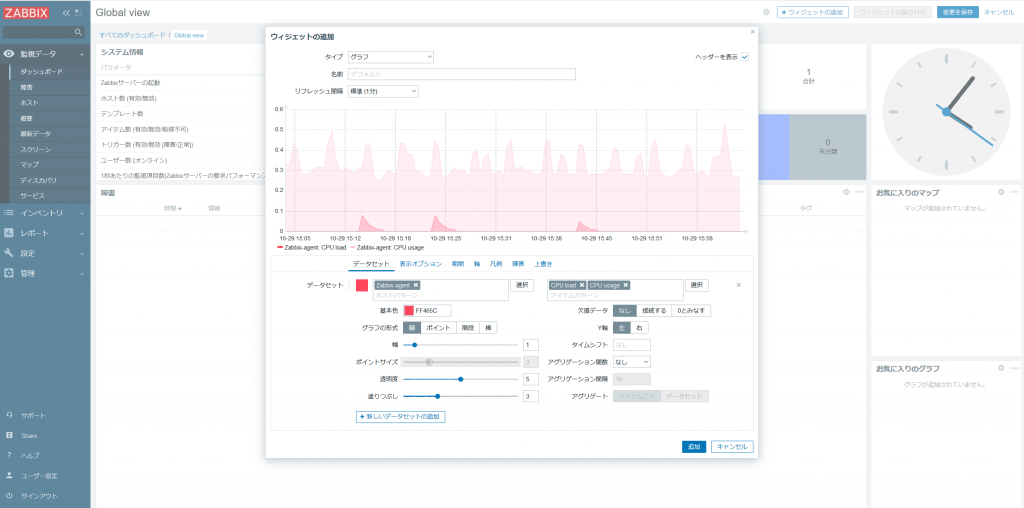
ダッシュボードの変更は画面右上の「ダッシュボードの変更」をクリックし、設定を行います。
| タイプ | グラフ | |
|---|---|---|
| 名前 | (空白) | |
| リフレッシュ間隔 | 標準(1分) | |
| データセット | ホストパターン | Zabbix-agent |
| アイテムパターン | CPU load と CPU usage を選択 | |
| その他の項目 | デフォルトのまま | |
「ウィジェットの追加」をクリックして、以下の項目を入力します。
上記の設定を行い、[追加] をクリックします。そうすると添付画像のように「障害」ウィジェットの下に「グラフ」ウィジェットが表示されるようになります。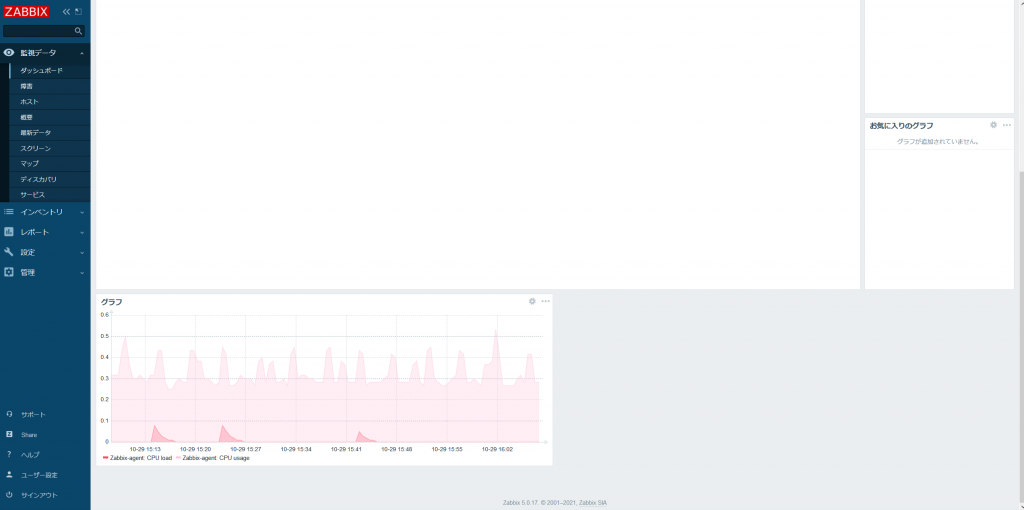 問題がないようでしたら画面右上の「変更を保存」をクリックして、設定を完了します。
問題がないようでしたら画面右上の「変更を保存」をクリックして、設定を完了します。
11. まとめ
今回は、Zabbix のさまざまな監視機能の紹介や、障害の検知と通知の設定方法、グラフとスクリーンの作成方法について解説しました。
次回は、Zabbix の管理画面上で行う各種操作を自動化できる、Zabbix API について紹介します。